Source: Original Article
This is a guest post co-written with David Meredith and Josh Zacharias from Associa.
Associa, North America’s largest community management company, oversees approximately 7.5 million homeowners with 15,000 employees across more than 300 branch offices. The company manages approximately 48 million documents across 26 TB of data, but their existing document management system lacks efficient automated classification capabilities, making it difficult to organize and retrieve documents across multiple document types. Every day, employees spend countless hours manually categorizing and organizing incoming documents—a time-consuming, error-prone process that creates bottlenecks in operational efficiency and potentially results in operational delays and reduced productivity.
Associa collaborated with the AWS Generative AI Innovation Center to build a generative AI-powered document classification system aligning with Associa’s long-term vision of using generative AI to achieve operational efficiencies in document management. The solution automatically categorizes incoming documents with high accuracy, processes documents efficiently, and provides substantial cost savings while maintaining operational excellence. The document classification system, developed using the Generative AI Intelligent Document Processing (GenAI IDP) Accelerator, is designed to integrate seamlessly into existing workflows. It revolutionizes how employees interact with document management systems by reducing the time spent on manual classification tasks.
This post discusses how Associa is using Amazon Bedrock to automatically classify their documents and to help enhance employee productivity.
Solution overview
The GenAI IDP Accelerator is a cloud-based document processing solution built on AWS that automatically extracts and organizes information from various document types. The system uses OCR technology and generative AI to convert unstructured documents into structured, usable data while scaling seamlessly to handle high document volumes.
The accelerator is built with a flexible, modular design using AWS CloudFormation templates that can handle different types of document processing while sharing core infrastructure for job management, progress tracking, and system monitoring. The accelerator supports three processing patterns. We use Pattern 2 for this solution using OCR (Amazon Textract) and classification (Amazon Bedrock). The following diagram illustrates this architecture.
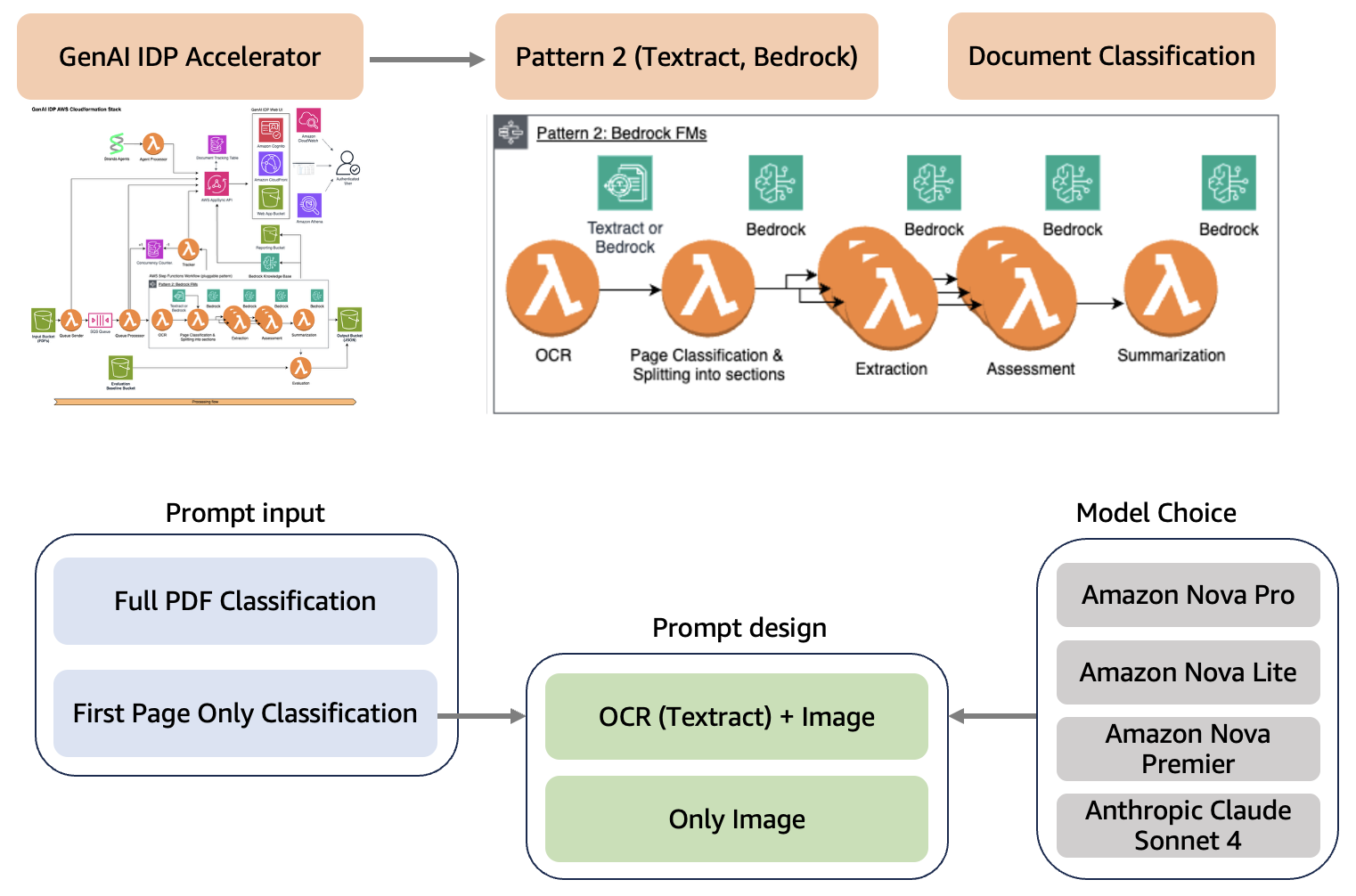
We optimized the document classification workflow by evaluating three key aspects:
- Prompt input – Full PDF document (all pages) vs. first page only
- Prompt design – Multimodal prompting with OCR data (using the Amazon Textract
analyze_document_layout) vs. document image only
- Model choice – Amazon Nova Lite, Amazon Nova Pro, Amazon Nova Premier, and Anthropic’s Claude Sonnet 4 on Amazon Bedrock
This comprehensive evaluation framework helped us identify the configuration that delivers the highest accuracy while minimizing processing inference costs for Associa’s specific document types and operational requirements. The evaluation dataset consists of 465 PDF documents across eight distinct document types. The dataset includes some samples identified as draft documents or email correspondences. These samples are categorized as document type Unknown due to insufficient classification criteria. The distribution of document types across classes is unbalanced, ranging from 6 samples for Policies and Resolutions to 155 samples for Minutes.
Evaluation: Prompt input
We started our initial evaluation using full PDF documents, where all pages of a PDF were used as input to the prompt for classification. The following table shows the accuracy for full PDF classification using Amazon Nova Pro with OCR and image. We observed an average classification accuracy of 91% considering the different document types with an average cost of 1.10 cents per document.
Document Type
Number of Samples
Number of Samples Classified Correctly
Classification Accuracy
Classification Cost (in Cents)
Bylaws
46
42
91%
1.52c
CCR Declarations
22
19
86%
1.55c
Certificate of Insurance
74
74
100%
1.49c
Contracts
71
66
93%
1.48c
Minutes
155
147
95%
1.47c
Plat Map
21
20
95%
1.45c
Policies and Resolutions
6
5
83%
0.35c
Rules and Regulations
50
44
88%
0.36c
Unknown
20
8
40%
0.24c
Overall
465
425
91%
1.10c
Using full PDF for document classification demonstrates an accuracy of 100% for Certificate of Insurance and 95% for Minutes. The system correctly classified 425 out of 465 documents. However, for the Unknown document type, it achieved only 40% accuracy, correctly classifying just 8 out of 20 documents.
Next, we experimented with using only the first page of a PDF document for classification, as shown in the following table. This approach improved overall accuracy from 91% to 95% with 443 out of 465 documents classified correctly while reducing classification cost per document from 1.10 cents to 0.55 cents.
Document Type
Number of Samples
Number of Samples Classified Correctly
Classification Accuracy
Classification Cost (in Cents)
Bylaws
46
44
96%
0.55c
CCR Declarations
22
21
95%
0.55c
Certificate of Insurance
74
74
100%
0.59c
Contracts
71
64
90%
0.56c
Minutes
155
153
99%
0.55c
Plat Map
21
17
81%
0.56c
Policies and Resolutions
6
4
67%
0.57c
Rules and Regulations
50
49
98%
0.56c
Unknown
20
17
85%
0.55c
Overall
465
443
95%
0.55c
Apart from improved accuracy and reduced cost, the first-page-only approach significantly improved Unknown document classification accuracy from 40% to 85%. First pages typically contain the most distinctive document features, whereas later pages in drafts or email threads can introduce noise that confuses the classifier. Combined with faster processing speeds and lower infrastructure costs, we selected the first-page-only approach for the subsequent evaluations.
Evaluation: Prompt design
Next, we experimented on prompt design to evaluate whether OCR data is necessary for document classification or just using the document image is sufficient. We evaluated by removing the OCR text extraction data from the prompt and only using the image in a multimodal prompt. This approach removes the Amazon Textract costs and relies entirely on the model’s understanding of visual features. The following table shows the accuracy for first-page-only classification using Amazon Nova Pro with only image.
Document Type
Number of Samples
Number of Samples Classified Correctly
Classification Accuracy
Classification Cost (in Cents)
Bylaws
46
45
98%
0.19c
CCR Declarations
22
20
91%
0.19c
Certificate of Insurance
74
74
100%
0.18c
Contracts
71
63
89%
0.18c
Minutes
155
151
97%
0.18c
Plat Map
21
18
86%
0.19c
Policies and Resolutions
6
4
67%
0.18c
Rules and Regulations
50
48
96%
0.18c
Unknown
20
10
50%
0.18c
Overall
465
433
93%
0.18c
The image-only classification approach demonstrates similar issues as the full PDF classification approach. Although this method achieves an overall accuracy of 93%, for Unknown document types, it could classify only 10 out of 20 documents correctly with 50% accuracy. The following table summarizes our evaluation of an image-only approach.
Overall Classification Accuracy (All Document Types, Including Unknown)
Classification Accuracy (Document Type: Unknown)
Classification Cost (in Cents)
First page only classification (OCR + Image)
95%
85%
0.55c
First page only classification (Only Image)
93%
50%
0.18c
The image-only approach removes OCR costs but reduces overall accuracy from 95% to 93% and Unknown document accuracy from 85% to 50%. Accurate Unknown document classification is critical for downstream human review and operational efficiency at Associa. We selected the combined OCR and image approach to maintain this capability.
Evaluation: Model choice
Using the optimal configuration of first-page-only classification with OCR and image, we evaluated different models to identify an optimal balance of accuracy and cost, as summarized in the following table. We focus on overall classification performance, classification of unknown documents, and per-document classification costs.
Overall Classification Accuracy (All Document Types, Including Unknown)
Classification Accuracy (Document Type: Unknown)
Classification Cost (in Cents)
Amazon Nova Pro
95%
85%
0.55c
Amazon Nova Lite
95%
50%
0.41c
Amazon Nova Premier
96%
90%
1.12c
Anthropic Claude Sonnet 4
95%
95%
1.21c
Overall classification accuracy ranged from 95–96% across the models, with variation in unknown document type performance. Certificate of Insurance, Plat Map, and Minutes achieved 98–100% accuracy across the models. Anthropic’s Claude Sonnet 4 achieved the highest unknown document accuracy (95%), followed by Amazon Nova Premier (90%) and Amazon Nova Pro (85%). However, Anthropic’s Claude Sonnet 4 increased classification cost from 0.55 cents to 1.21 cents per document. Amazon Nova Premier achieved the best overall classification accuracy at 1.12 cents per document. Considering the trade-offs between accuracy and cost, we selected Amazon Nova Pro as the optimal model choice.
Conclusion
Associa built a generative AI-powered document classification system using Amazon Nova Pro on Amazon Bedrock that achieves 95% accuracy at an average cost of 0.55 cents per document. The GenAI IDP Accelerator facilitates reliable performance scaling to high volume of documents across their branches. “The solution developed by AWS Generative AI Innovation Center improves how our employees manage and organize documents, and we foresee significant reduction of manual effort in document processing,” says Andrew Brock, President, Digital & Technology Services & Chief Information Officer at Associa. “The document classification system provides substantial cost savings and operational improvements, while maintaining our high accuracy standards in serving residential communities.”
Refer to the GenAI IDP Accelerator GitHub repository for detailed examples and choose Watch to stay informed on new releases. If you’d like to work with the AWS GenAI Innovation Center, please reach out to us or leave a comment.
Acknowledgements
We would like to thank Mike Henry, Bob Strahan, Marcelo Silva, and Mofijul Islam for their significant contributions, strategic decisions, and guidance throughout.
About the authors
David Meredith is Director of Employee Software Development at Associa. He oversees the efforts of the Associa team to create software for their 15,000 employees to use daily. He has almost 20 years of experience with software in the residential property management industry and lives in the Vancouver area of BC, Canada.
is Director of Employee Software Development at Associa. He oversees the efforts of the Associa team to create software for their 15,000 employees to use daily. He has almost 20 years of experience with software in the residential property management industry and lives in the Vancouver area of BC, Canada.
 Josh Zacharias is a Software Developer at Associa, where he is a lead engineer for the internal software team. His work includes architecting full stack solutions for various departments in the company as well as empowering other developers to be more efficient experts in developing software.
Josh Zacharias is a Software Developer at Associa, where he is a lead engineer for the internal software team. His work includes architecting full stack solutions for various departments in the company as well as empowering other developers to be more efficient experts in developing software.
 Monica Raj is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she works with organizations across various industries to develop AI solutions. Her work focuses on building and deploying agentic AI solutions, natural language processing, contact center automation, and intelligent document processing. Monica has extensive experience in building scalable AI solutions for enterprise customers.
Monica Raj is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she works with organizations across various industries to develop AI solutions. Her work focuses on building and deploying agentic AI solutions, natural language processing, contact center automation, and intelligent document processing. Monica has extensive experience in building scalable AI solutions for enterprise customers.
 Tryambak Gangopadhyay is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he collaborates with organizations across a diverse spectrum of industries. His role involves researching and developing generative AI solutions to address crucial business challenges and accelerate AI adoption. Prior to joining AWS, Tryambak completed his PhD at Iowa State University.
Tryambak Gangopadhyay is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he collaborates with organizations across a diverse spectrum of industries. His role involves researching and developing generative AI solutions to address crucial business challenges and accelerate AI adoption. Prior to joining AWS, Tryambak completed his PhD at Iowa State University.
 Nkechinyere Agu is an Applied Scientist at the AWS Generative AI Innovation Center, where she works with organizations across various industries to develop AI solutions. Her work focuses on developing multimodal AI solutions, agentic AI solutions, and natural language processing. Prior to joining AWS, Nkechinyere completed her PhD at Rensselaer Polytechnic Institute, Troy NY.
Nkechinyere Agu is an Applied Scientist at the AWS Generative AI Innovation Center, where she works with organizations across various industries to develop AI solutions. Her work focuses on developing multimodal AI solutions, agentic AI solutions, and natural language processing. Prior to joining AWS, Nkechinyere completed her PhD at Rensselaer Polytechnic Institute, Troy NY.
 Naman Sharma is a Generative AI Strategist at the AWS Generative AI Innovation Center, where he collaborates with organizations to drive adoption of generative AI to solve business problems at scale. His work focuses on leading customers from scoping, deploying, and scaling frontier solutions with the GenAIIC Strategy and Applied Science teams.
Naman Sharma is a Generative AI Strategist at the AWS Generative AI Innovation Center, where he collaborates with organizations to drive adoption of generative AI to solve business problems at scale. His work focuses on leading customers from scoping, deploying, and scaling frontier solutions with the GenAIIC Strategy and Applied Science teams.
 Yingwei Yu is an Applied Science Manager at the Generative AI Innovation Center, based in Houston, Texas. With extensive experience in applied machine learning and generative AI, Yingwei leads the development of innovative solutions across various industries.
Yingwei Yu is an Applied Science Manager at the Generative AI Innovation Center, based in Houston, Texas. With extensive experience in applied machine learning and generative AI, Yingwei leads the development of innovative solutions across various industries.
 Dwaragha Sivalingam is a Senior Solutions Architect specializing in generative AI at AWS, serving as a trusted advisor to customers on cloud transformation and AI strategy. With eight AWS certifications, including ML Specialty, he has helped customers in many industries, including insurance, telecom, utilities, engineering, construction, and real estate. A machine learning enthusiast, he balances his professional life with family time, enjoying road trips, movies, and drone photography.
Dwaragha Sivalingam is a Senior Solutions Architect specializing in generative AI at AWS, serving as a trusted advisor to customers on cloud transformation and AI strategy. With eight AWS certifications, including ML Specialty, he has helped customers in many industries, including insurance, telecom, utilities, engineering, construction, and real estate. A machine learning enthusiast, he balances his professional life with family time, enjoying road trips, movies, and drone photography.