Transformer vs LSTM for Time Series: Which Works Better?
From daily weather measurements or traffic sensor readings to stock prices, time series data are present nearly everywhere.
From daily weather measurements or traffic sensor readings to stock prices, time series data are present nearly everywhere.
Building newly trained machine learning models that work is a relatively straightforward endeavor, thanks to mature frameworks and accessible computing power.
This article is divided into four parts; they are: • How Logits Become Probabilities • Temperature • Top- k Sampling • Top- p Sampling When you ask an LLM a question, it outputs a vector of logits.
Machine learning models possess a fundamental limitation that often frustrates newcomers to natural language processing (NLP): they cannot read.
Data leakage is an often accidental problem that may happen in machine learning modeling.
By Jacob Meyers and Rob Zienert Temporal is a Durable Execution platform which allows you to write code “as if failures don’t exist”. It’s become increasingly critical to Netflix since its initial adoption in 2021, with users ranging from the operators of our Open Connect global CDN to our Live reliability teams now depending on Temporal …
Read more “How Temporal Powers Reliable Cloud Operations at Netflix”

Foundation model training has reached an inflection point where traditional checkpoint-based recovery methods are becoming a bottleneck to efficiency and cost-effectiveness. As models grow to trillions of parameters and training clusters expand to thousands of AI accelerators, even minor disruptions can result in significant costs and delays. In this post, we introduce checkpointless training on …
The AI state of the art is shifting rapidly from simple chat interfaces to autonomous agents capable of planning, executing, and refining complex workflows. In this new landscape, the ability to ground these intelligent agents in your enterprise data is key to unlocking true business value. Google Cloud is at the forefront of this shift, …
Read more “Connect your enterprise data to Google’s new Antigravity IDE”
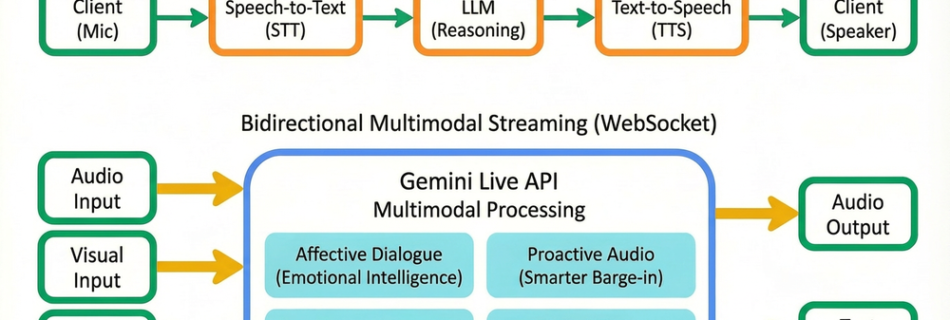
Give your AI apps and agents a natural, almost human-like interface, all through a single WebSocket connection. Today, we announced the general availability of Gemini Live API on Vertex AI, which is powered by the latest Gemini 2.5 Flash Native Audio model. This is more than just a model upgrade; it represents a fundamental move …
Read more “A developer’s guide to Gemini Live API in Vertex AI”
TL;DR In 2026, the businesses that win with AI will do three things differently: redesign core workflows around AI agents, treat AI as an operating system rather than a toolset, and deliberately restructure human work to compound AI advantages instead of fighting them. By 2026, AI will no longer be a differentiator by itself. Nearly …
Read more “3 Actionable AI Recommendations for Businesses in 2026”