Retrofit, don’t rebuild: Agentic overlays for transforming legacy enterprise services
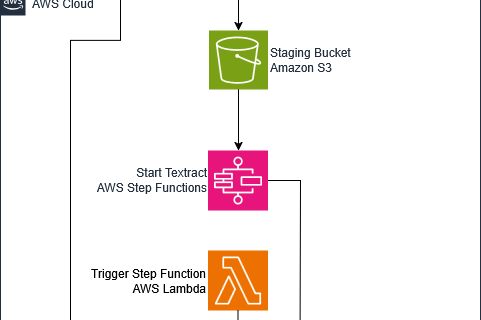
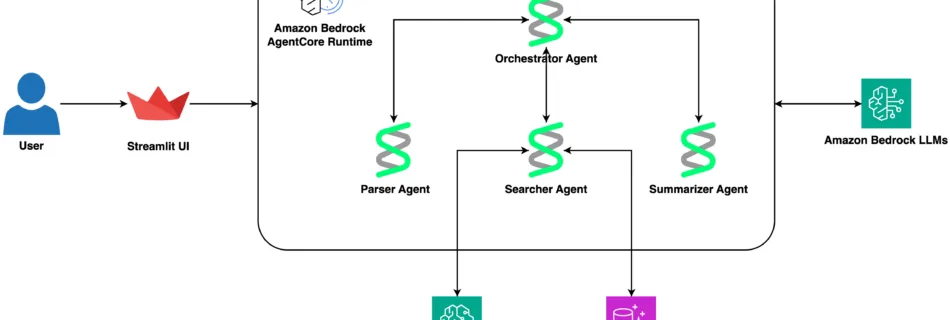
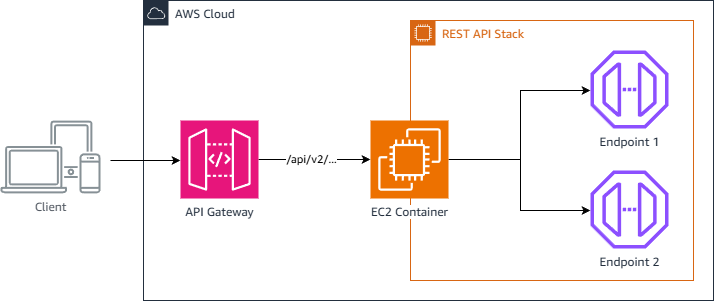
The opinions expressed in this post are the authors’ views and not those of Cisco. Enterprise architectures have long been centered on REST APIs and microservices. These systems are stable, well-tested, and deeply embedded in production environments. They weren’t designed for Agent-to-Agent (A2A) communication, the emerging standard for autonomous agents that collaborate, reason, and coordinate …
Read more “Retrofit, don’t rebuild: Agentic overlays for transforming legacy enterprise services”