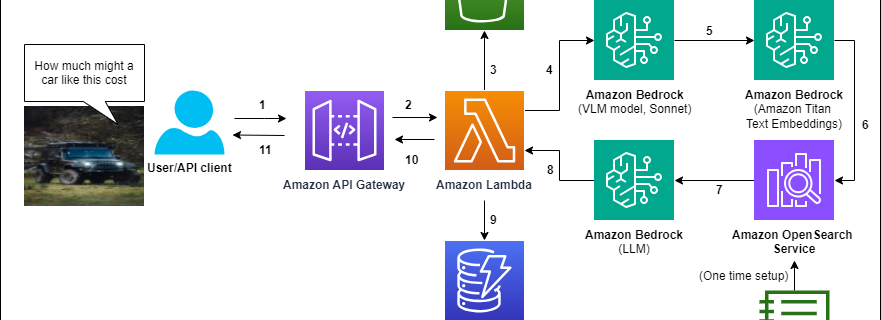
Create a multimodal chatbot tailored to your unique dataset with Amazon Bedrock FMs
With recent advances in large language models (LLMs), a wide array of businesses are building new chatbot applications, either to help their external customers or to support internal teams. For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer …
Read more “Create a multimodal chatbot tailored to your unique dataset with Amazon Bedrock FMs”