Microsoft’s Recall Feature Is Even More Hackable Than You Thought
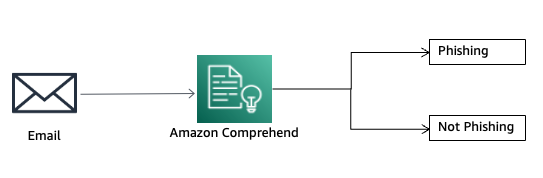
A new discovery that the AI-enabled feature’s historical data can be accessed even by hackers without administrator privileges only contributes to the growing sense that the feature is a “dumpster fire.”