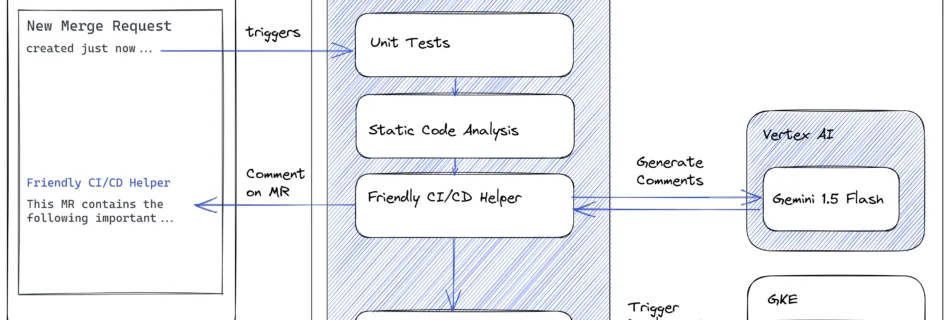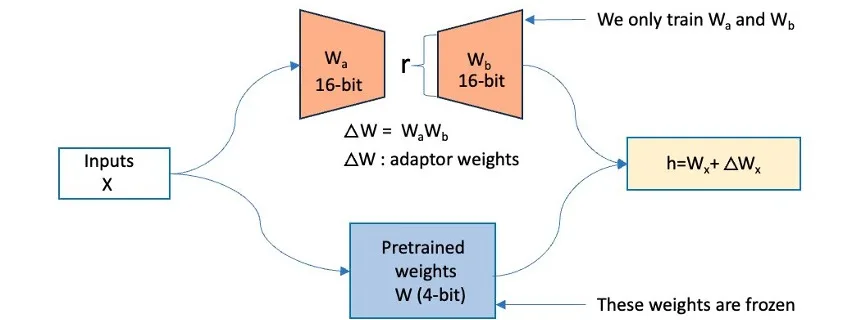
Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA
Companies across various scales and industries are using large language models (LLMs) to develop generative AI applications that provide innovative experiences for customers and employees. However, building or fine-tuning these pre-trained LLMs on extensive datasets demands substantial computational resources and engineering effort. With the increase in sizes of these pre-trained LLMs, the model customization process …
Read more “Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA”