13 Best Toiletry Bags, Tested and Reviewed (2024)
Our team evaluated a ton of toiletry bags to find the best storage, organization, and design options for all your essentials.
Our team evaluated a ton of toiletry bags to find the best storage, organization, and design options for all your essentials.
To get started with AI agents, we must first identify differences between agents and models and define roles and communication requirements.Read More
This is the first time Russia has used its so-called Oreshnik intermediate-range ballistic missile in combat. The launch also serves as a warning to the West.
Let’s dive into the how and why of image background removal.
Unity makes strength.
*Equal Contributors A dominant paradigm in large multimodal models is to pair a large language de- coder with a vision encoder. While it is well-known how to pre-train and tune language decoders for multimodal tasks, it is less clear how the vision encoder should be pre-trained. A de facto standard is to pre-train the vision …
Read more “Multimodal Autoregressive Pre-Training of Large Vision Encoders”
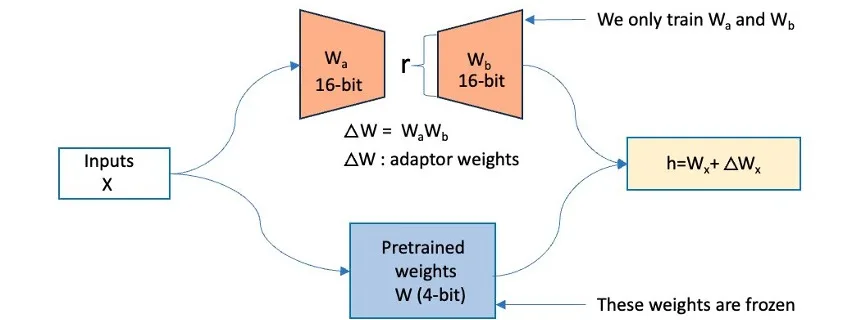
Companies across various scales and industries are using large language models (LLMs) to develop generative AI applications that provide innovative experiences for customers and employees. However, building or fine-tuning these pre-trained LLMs on extensive datasets demands substantial computational resources and engineering effort. With the increase in sizes of these pre-trained LLMs, the model customization process …
Read more “Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA”
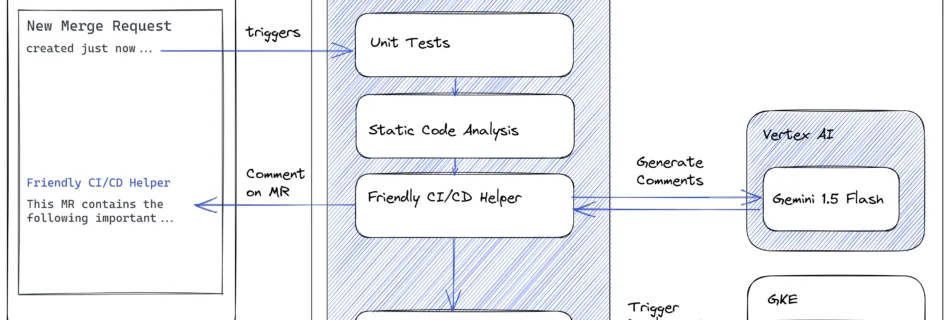
In the domain of software development, AI-driven assistance is emerging as a transformative force to enhance developer experience and productivity and ultimately optimize overall software delivery performance. Many organizations started to leverage AI-based assistants, such as Gemini Code Assist, in developer IDEs to support them in solving more difficult problems, understanding unfamiliar code, generating test …
Read more “Boost your Continuous Delivery pipeline with Generative AI”
Ai2 released Tülu 3, a model that makes fine-tuning open-source LLMs easier and get its performance closer to closed LLMs like GPT-4o.Read More
Black Friday deals on Amazon devices have started early. Even the brand-new Kindle lineup is on sale.