Anomaly Detection Techniques in Large-Scale Datasets
Anomaly detection means finding patterns in data that are different from normal.
Anomaly detection means finding patterns in data that are different from normal.
Our pioneering speech generation technologies are helping people around the world interact with more natural, conversational and intuitive digital assistants and AI tools.
Translating text that contains entity names is a challenging task, as cultural-related references can vary significantly across languages. These variations may also be caused by transcreation, an adaptation process that entails more than transliteration and word-for-word translation. In this paper, we address the problem of cross-cultural translation on two fronts: (i) we introduce XC-Translate, the …
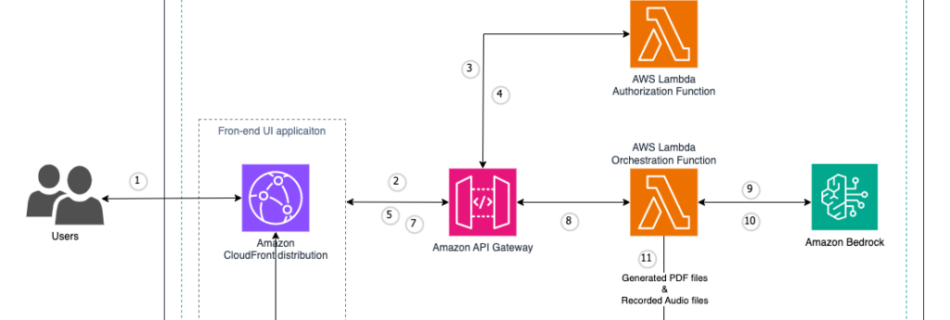
Preserving and taking advantage of institutional knowledge is critical for organizational success and adaptability. This collective wisdom, comprising insights and experiences accumulated by employees over time, often exists as tacit knowledge passed down informally. Formalizing and documenting this invaluable resource can help organizations maintain institutional memory, drive innovation, enhance decision-making processes, and accelerate onboarding for …
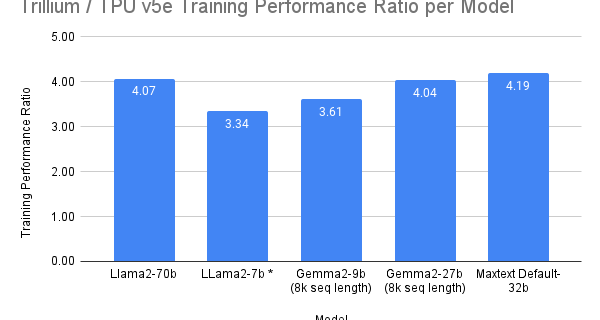
The rise of generative AI has ushered in an era of unprecedented innovation, demanding increasingly complex and more powerful AI models. These advanced models necessitate high-performance infrastructure capable of efficiently scaling AI training, tuning, and inferencing workloads while optimizing for both system performance and cost effectiveness. Google Cloud has been pioneering AI infrastructure for over …
Read more “Powerful infrastructure innovations for your AI-first future”
OpenAI’s voice assistant API offers five new, more natural voices and discounted prices in the newest update.Read More
The race for better generative AI is also a race for more computing power. On that score, according to CEO Mark Zuckerberg, Meta appears to be winning.
A team including researchers from Seoul National University College of Engineering has developed neuromorphic hardware capable of performing artificial intelligence (AI) computations with ultra-low power consumption. The research, published in the journal Nature Nanotechnology, addresses fundamental issues in existing intelligent semiconductor materials and devices while demonstrating potential for array-level technology.
Computer vision (CV) is a field where machines learn to “see” and understand images or videos.
This paper was accepted at the Efficient Natural Language and Speech Processing (ENLSP) workshop at NeurIPS 2024. Speculative decoding is a prominent technique to speed up the inference of a large target language model based on predictions of an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target …
Read more “Speculative Streaming: Fast LLM Inference Without Auxiliary Models”