AI chatbot frenzy: Everything everywhere (all at once)
This is not another AI winter. Why generative AI and AI chatbots will change everything and evolve to artificial general intelligence.Read More
This is not another AI winter. Why generative AI and AI chatbots will change everything and evolve to artificial general intelligence.Read More
submitted by /u/darkside1977 [link] [comments]

Marketing personalization is a dynamic, data-driven approach to digital marketing. Brands implement marketing personalization using multiple data points based on customer behavior, buying history, preferences, and interests. Brands use this information to personalize emails, product recommendations, website experiences, and more to provide customers with personalized messaging and customer experiences that cater to their changing needs …
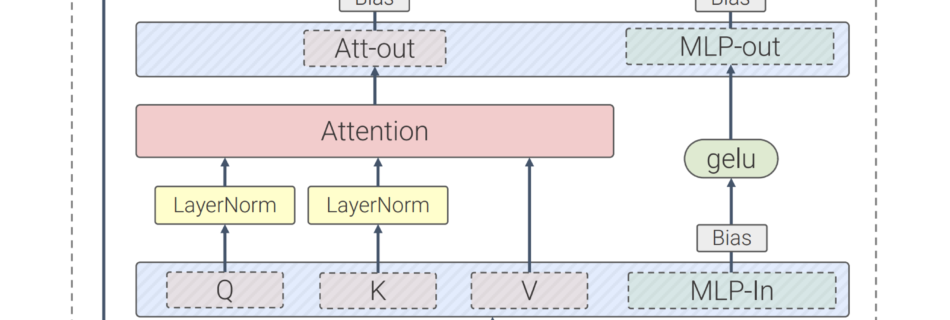
Posted by Piotr Padlewski and Josip Djolonga, Software Engineers, Google Research Large Language Models (LLMs) like PaLM or GPT-3 showed that scaling transformers to hundreds of billions of parameters improves performance and unlocks emergent abilities. The biggest dense models for image understanding, however, have reached only 4 billion parameters, despite research indicating that promising multimodal …
Read more “Scaling vision transformers to 22 billion parameters”
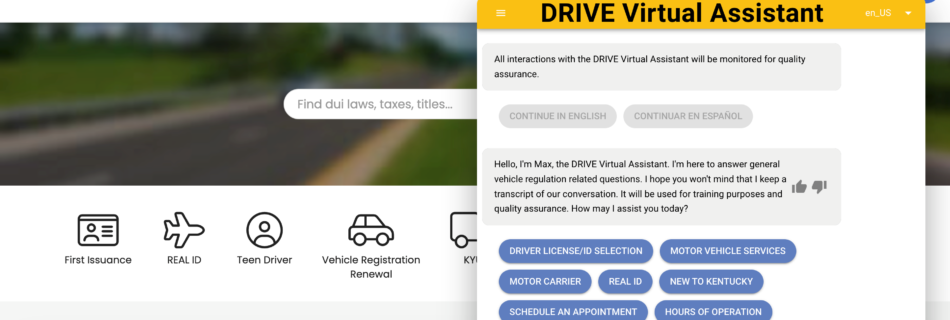
This post was co-written with Tony Momenpour and Drew Clark from KYTC. Government departments and businesses operate contact centers to connect with their communities, enabling citizens and customers to call to make appointments, request services, and sometimes just ask a question. When there are more calls than agents can answer, callers get placed on hold …
AI has never been more front and center for both consumers and development teams. I have hosted AI conversations, and one of the top comments I get is how to get started in AI without a ton of resources or ML developers on hand. The first place I send people is the treasure trove of …
Read more “Got your eye on AI? Try these 6 interactive tutorials”
Cybersecurity experts argue the open letter calling for a pause on GPT-4 and LLM development will do little to address cyberthreats.Read More
Artificial intelligence technologies like ChatGPT are seemingly doing everything these days: writing code, composing music, and even creating images so realistic you’ll think they were taken by professional photographers. Add thinking and responding like a human to the conga line of capabilities. A recent study proves that artificial intelligence can respond to complex survey questions …
Read more “Can AI predict how you’ll vote in the next election?”
Tomorrow.io was arguably the first company to hire an AI-focused content role and it demonstrates how companies are embracing the technology.

There is such a thing as too much data — when it becomes too overwhelming to properly figure out how to use it. Keeping track and making sense of what data your organization has, where it came from, who owns it, and how they can use it, alongside a myriad of other questions, can be a daunting …