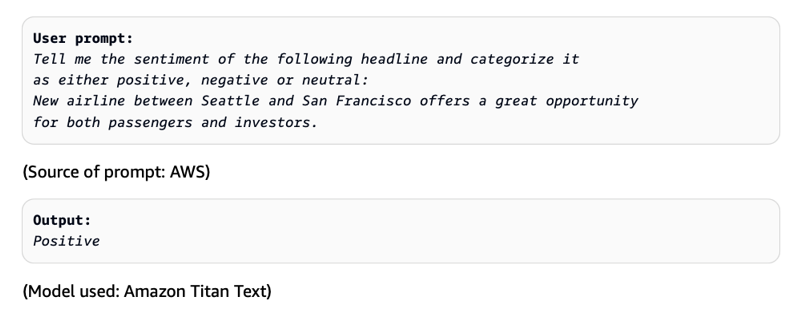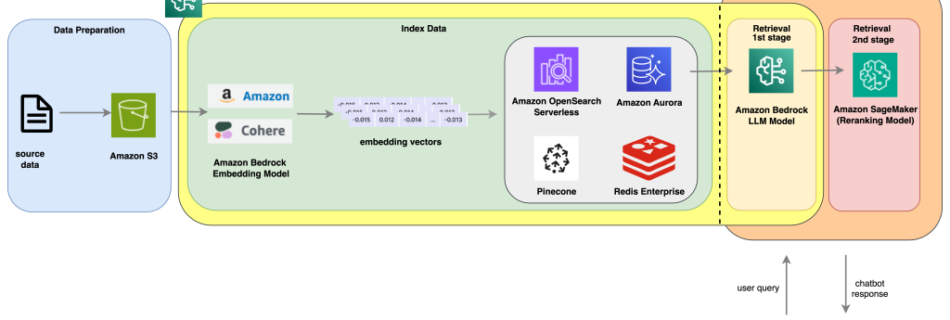
Improve AI assistant response accuracy using Knowledge Bases for Amazon Bedrock and a reranking model
AI chatbots and virtual assistants have become increasingly popular in recent years thanks the breakthroughs of large language models (LLMs). Trained on a large volume of datasets, these models incorporate memory components in their architectural design, allowing them to understand and comprehend textual context. Most common use cases for chatbot assistants focus on a few …