Generative AI foundation model training on Amazon SageMaker
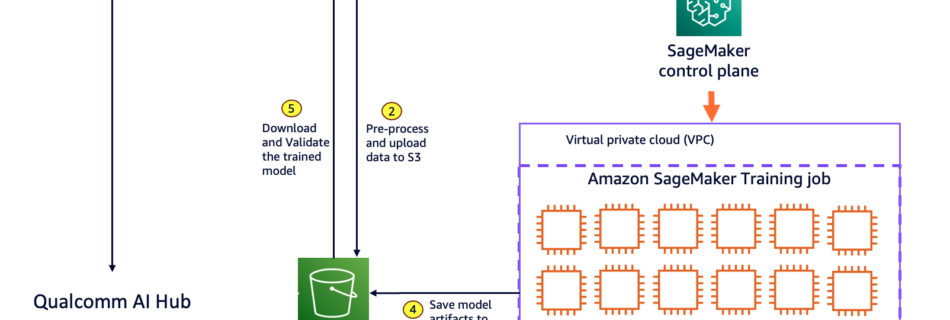
To stay competitive, businesses across industries use foundation models (FMs) to transform their applications. Although FMs offer impressive out-of-the-box capabilities, achieving a true competitive edge often requires deep model customization through pre-training or fine-tuning. However, these approaches demand advanced AI expertise, high performance compute, fast storage access and can be prohibitively expensive for many organizations. …
Read more “Generative AI foundation model training on Amazon SageMaker”