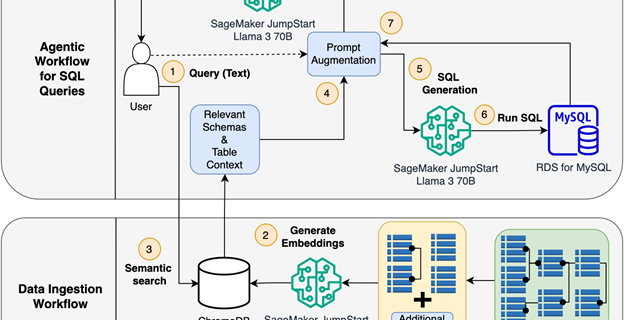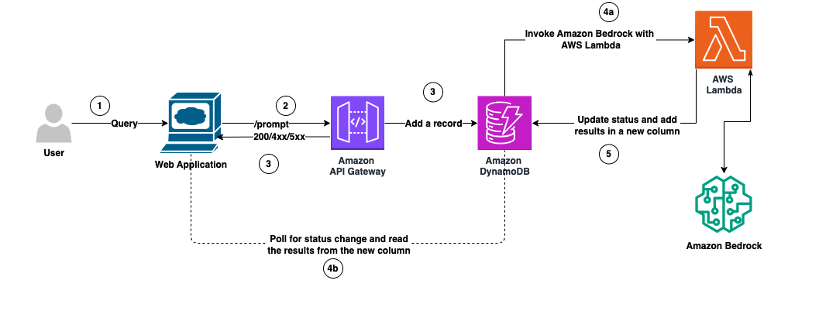
How Vidmob is using generative AI to transform its creative data landscape
This post was co-written with Mickey Alon from Vidmob. Generative artificial intelligence (AI) can be vital for marketing because it enables the creation of personalized content and optimizes ad targeting with predictive analytics. Specifically, such data analysis can result in predicting trends and public sentiment while also personalizing customer journeys, ultimately leading to more effective …
Read more “How Vidmob is using generative AI to transform its creative data landscape”