
Evaluating Netflix Show Synopses with LLM-as-a-Judge
by Gabriela Alessio, Cameron Taylor, and Cameron R. Wolfe Introduction When members log into Netflix, one of the hardest choices is what to watch. The challenge isn’t a lack of options — there are thousands of titles — but finding the most intriguing one is complex and deeply personal. To help, we surface personalized promotional assets, especially the show synopsis — a …
Read more “Evaluating Netflix Show Synopses with LLM-as-a-Judge”
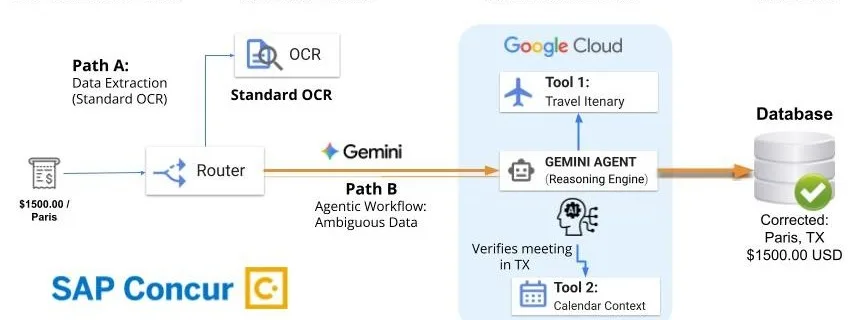
How SAP Concur automates expense reporting with agentic AI
For decades, expense automation relied on a simple premise: If the machine can read the text, it can do the work. But anyone who has ever tried to scan a crumpled, smudged, or sun-bleached receipt from their pocket knows that reading isn’t enough. When key data is missing, such as a city name or a …
Read more “How SAP Concur automates expense reporting with agentic AI”
A Theoretical Framework for Acoustic Neighbor Embeddings
This paper provides a theoretical framework for interpreting acoustic neighbor embeddings, which are representations of the phonetic content of variable-width audio or text in a fixed-dimensional embedding space. A probabilistic interpretation of the distances between embeddings is proposed, based on a general quantitative definition of phonetic similarity between words. This provides us a framework for …
Read more “A Theoretical Framework for Acoustic Neighbor Embeddings”
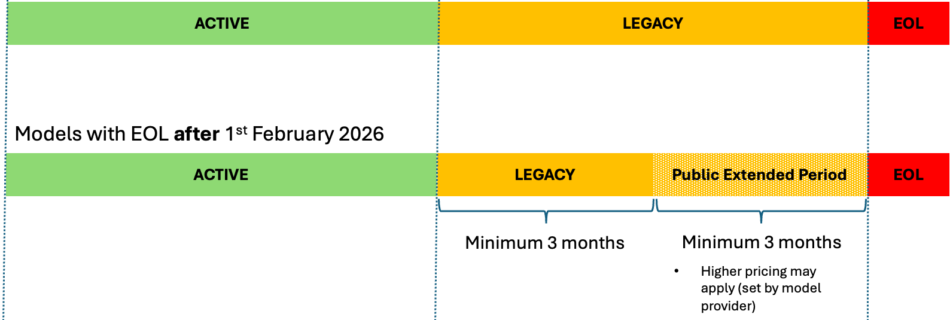
Understanding Amazon Bedrock model lifecycle
Amazon Bedrock regularly releases new foundation model (FM) versions with better capabilities, accuracy, and safety. Understanding the model lifecycle is essential for effective planning and management of AI applications built on Amazon Bedrock. Before migrating your applications, you can test these models through the Amazon Bedrock console or API to evaluate their performance and compatibility. …
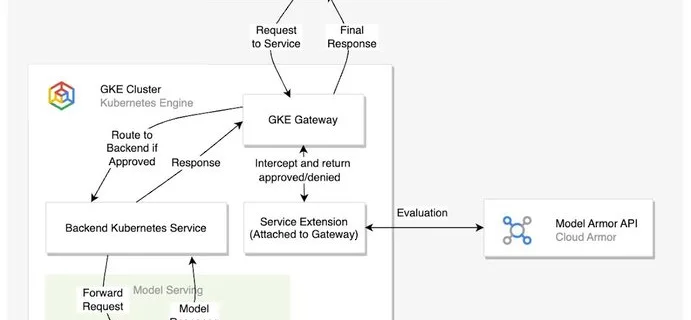
Guardrails at the gateway: Securing AI inference on GKE with Model Armor
Enterprises are rapidly moving AI workloads from experimentation to production on Google Kubernetes Engine (GKE), using its scalability to serve powerful inference endpoints. However, as these models handle increasingly sensitive data, they introduce unique AI-driven attack vectors — from prompt injection to sensitive data leakage — that traditional firewalls aren’t designed to catch. Prompt injection …
Read more “Guardrails at the gateway: Securing AI inference on GKE with Model Armor”
Governance-Aware Agent Telemetry for Closed-Loop Enforcement in Multi-Agent AI Systems
Enterprise multi-agent AI systems produce thousands of inter-agent interactions per hour, yet existing observability tools capture these dependencies without enforcing anything. OpenTelemetry and Langfuse collect telemetry but treat governance as a downstream analytics concern, not a real-time enforcement target. The result is an “observe-but-do-not-act” gap where policy violations are detected only after damage is done. …
Read more “Governance-Aware Agent Telemetry for Closed-Loop Enforcement in Multi-Agent AI Systems”
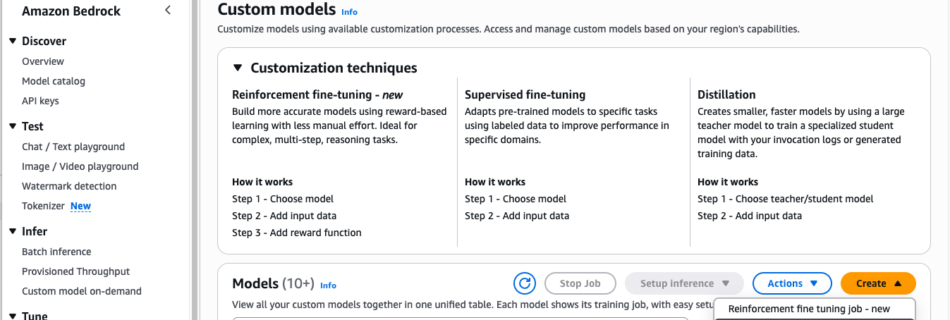
Customize Amazon Nova models with Amazon Bedrock fine-tuning
Today, we’re sharing how Amazon Bedrock makes it straightforward to customize Amazon Nova models for your specific business needs. As customers scale their AI deployments, they need models that reflect proprietary knowledge and workflows — whether that means maintaining a consistent brand voice in customer communications, handling complex industry-specific workflows or accurately classifying intents in …
Read more “Customize Amazon Nova models with Amazon Bedrock fine-tuning”
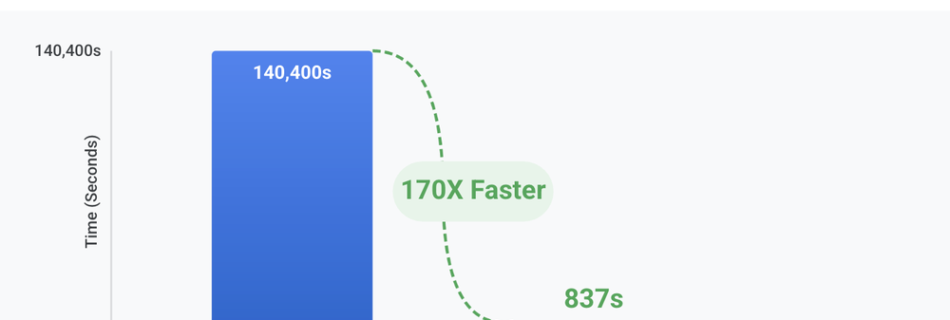
New GKE Cloud Storage FUSE Profiles take the guesswork out of configuring AI storage
In the world of AI/ML, data is the fuel that drives training and inference workloads. For Google Kubernetes Engine (GKE) users, Cloud Storage FUSE provides high-performance, scalable access to data stored in Google Cloud Storage. However, we learned from customers that getting the maximum performance out of Cloud Storage FUSE can be complex. Today, we …
Read more “New GKE Cloud Storage FUSE Profiles take the guesswork out of configuring AI storage”

Frontend Engineering at Palantir: Plotlines in Three.js
About this SeriesFrontend engineering at Palantir goes far beyond building standard web apps. Our engineers design interfaces for mission-critical decision-making, build operational applications that translate insight to action, and create systems that handle massive datasets — thinking not just about what the user needs, but what they need when the network is unreliable, the stakes are high, …
Read more “Frontend Engineering at Palantir: Plotlines in Three.js”