Gemma: Introducing new state-of-the-art open models
Gemma is built for responsible AI development from the same research and technology used to create Gemini models.
Category Added in a WPeMatico Campaign
Gemma is built for responsible AI development from the same research and technology used to create Gemini models.

Posted by Zheng Xu, Research Scientist, and Yanxiang Zhang, Software Engineer, Google Language models (LMs) trained to predict the next word given input text are the key technology for many applications [1, 2]. In Gboard, LMs are used to improve users’ typing experience by supporting features like next word prediction (NWP), Smart Compose, smart completion …
Read more “Advances in private training for production on-device language models”

Introduction Everyone is excited about generative AI (gen AI) nowadays and rightfully so. You might be generating text with PaLM 2 or Gemini Pro, generating images with ImageGen 2, translating code from language to another with Codey, or describing images and videos with Gemini Pro Vision. No matter how you’re using gen AI, at the …
Read more “Orchestrate Vertex AI’s PaLM and Gemini APIs with Workflows”
Large language models (LLMs) have the potential to impact a wide range of creative domains, as exemplified in popular text-to-image generators like DALL·E and Midjourney. However, the application of LLMs to motion-based visual design has not yet been explored and presents novels challenges such as how users might effectively describe motion in natural language. Further, …
Read more “Keyframer: Empowering Animation Design using Large Language Models”

Introduction As part of the process laid out in the Biden-Harris Administration’s Executive Order on Safe, Secure, and Trustworthy AI, the National Institute of Standards and Technology (NIST) released a request for information to assist the agency in carrying out its obligations under the Executive Order. Palantir is proud to continue our ongoing contributions to …
Read more “Palantir’s Response to NIST RFI on Artificial Intelligence”
In an era of accelerating climate change, predicting the near-future can yield major benefits. For instance, when utility officials are aware that a heat wave is on its way, they can plan energy procurement to prevent power outages. When farmers in drought-prone regions are able to predict which crops are susceptible to failure, they can …
Read more “Climate change predictions: Anticipating and adapting to a warming world”
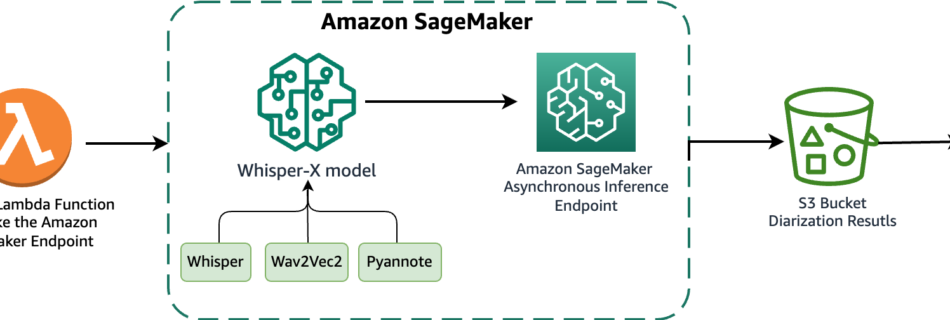
ZOO Digital provides end-to-end localization and media services to adapt original TV and movie content to different languages, regions, and cultures. It makes globalization easier for the world’s best content creators. Trusted by the biggest names in entertainment, ZOO Digital delivers high-quality localization and media services at scale, including dubbing, subtitling, scripting, and compliance. Typical …
Read more “Streamline diarization using AI as an assistive technology: ZOO Digital’s story”

The potential of video analytics and generative AI to revolutionize industries is immense. These technologies are opening new frontiers in automated insights, decision-making, and content generation. By marrying AI insight and audio data, organizations are realizing benefits across the span of business, from increased sales and revenue to enhanced customer experiences and reduced costs. Any …
2023.04.10 – 2024.02.08 You were not very good and we didn’t use you very much – no wonder you were less than 1 year old when you went to AI-heaven. In the ever-evolving landscape of artificial intelligence, we bid farewell to Bard, a pioneering AI companion that has been a source of creativity, learning, and …
In today’s complex global business environment, effective supply chain management (SCM) is crucial for maintaining a competitive advantage. The pandemic and its aftermath highlighted the importance of having a robust supply chain strategy, with many companies facing disruptions due to shortages in raw materials and fluctuations in customer demand. The challenges continue: one 2023 survey …
Read more “Streamlining supply chain management: Strategies for the future”