Unlock the potential of generative AI in industrial operations
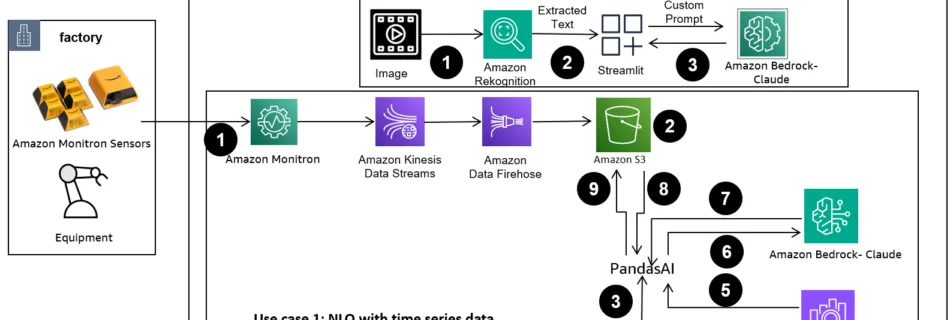
In the evolving landscape of manufacturing, the transformative power of AI and machine learning (ML) is evident, driving a digital revolution that streamlines operations and boosts productivity. However, this progress introduces unique challenges for enterprises navigating data-driven solutions. Industrial facilities grapple with vast volumes of unstructured data, sourced from sensors, telemetry systems, and equipment dispersed …
Read more “Unlock the potential of generative AI in industrial operations”