OpenAI announces leadership transition

Emerging practices for Society-Centered AI
Posted by Anoop Sinha, Research Director, Technology & Society, and Yossi Matias, Vice President, Google Research The first of Google’s AI Principles is to “Be socially beneficial.” As AI practitioners, we’re inspired by the transformative potential of AI technologies to benefit society and our shared environment at a scale and swiftness that wasn’t possible before. …
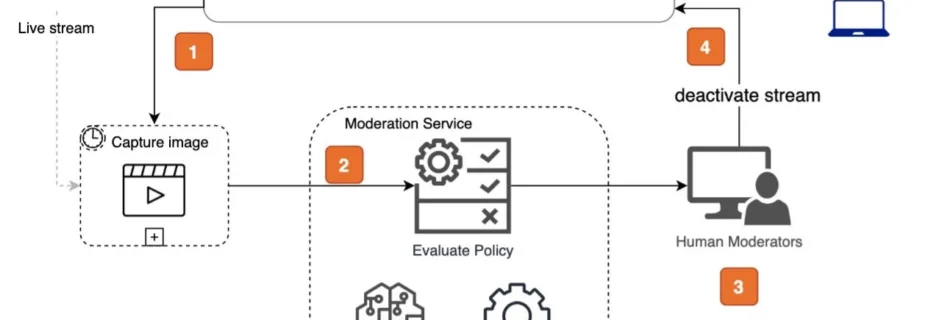
Moderate your Amazon IVS live stream using Amazon Rekognition
Amazon Interactive Video Service (Amazon IVS) is a managed live streaming solution that is designed to provide a quick and straightforward setup to let you build interactive video experiences and handles interactive video content from ingestion to delivery. With the increased usage of live streaming, the need for effective content moderation becomes even more crucial. …
Read more “Moderate your Amazon IVS live stream using Amazon Rekognition”
The four building blocks of responsible generative AI in banking
The future of banking is generative. While headlines often exaggerate how generative AI (gen AI) will radically transform finance, the truth is more nuanced. At Google Cloud, we’re optimistic about gen AI’s potential to improve the banking sector for both banks and their customers. We also believe that it can be done in a responsible …
Read more “The four building blocks of responsible generative AI in banking”

Responsible AI at Google Research: Adversarial testing for generative AI safety
Posted by Kathy Meier-Hellstern, Building Responsible AI & Data Systems, Director, Google Research The Responsible AI and Human-Centered Technology (RAI-HCT) team within Google Research is committed to advancing the theory and practice of responsible human-centered AI through a lens of culturally-aware research, to meet the needs of billions of users today, and blaze the path …
Read more “Responsible AI at Google Research: Adversarial testing for generative AI safety”
Transforming the future of music creation
Announcing our most advanced music generation model and two new AI experiments, designed to open a new playground for creativity
Creating a sustainable future with the experts of today and tomorrow
When extreme weather strikes, it hits vulnerable populations the hardest. In the current global climate of stronger and more frequent storms, heat waves, droughts and floods, how do we build more positive environmental and social impact? We have a responsibility to apply our technological expertise, resources and ecosystem to help the world become more resilient …
Read more “Creating a sustainable future with the experts of today and tomorrow”

Responsible AI at Google Research: Adversarial testing for generative AI safety
Posted by Kathy Meier-Hellstern, Building Responsible AI & Data Systems, Director, Google Research The Responsible AI and Human-Centered Technology (RAI-HCT) team within Google Research is committed to advancing the theory and practice of responsible human-centered AI through a lens of culturally-aware research, to meet the needs of billions of users today, and blaze the path …
Read more “Responsible AI at Google Research: Adversarial testing for generative AI safety”
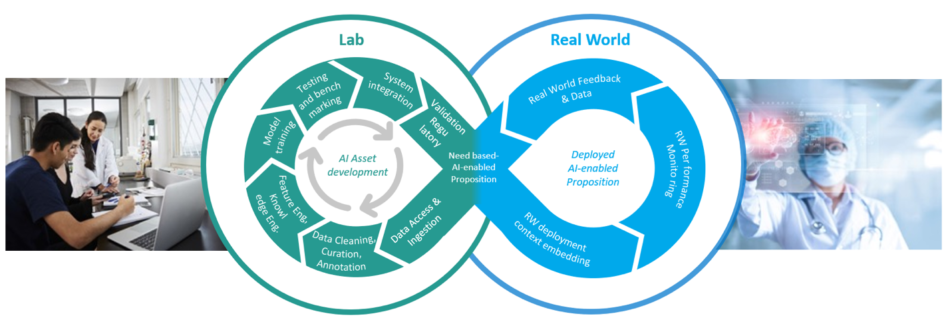
Philips accelerates development of AI-enabled healthcare solutions with an MLOps platform built on Amazon SageMaker
This is a joint blog with AWS and Philips. Philips is a health technology company focused on improving people’s lives through meaningful innovation. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care. It partners with …