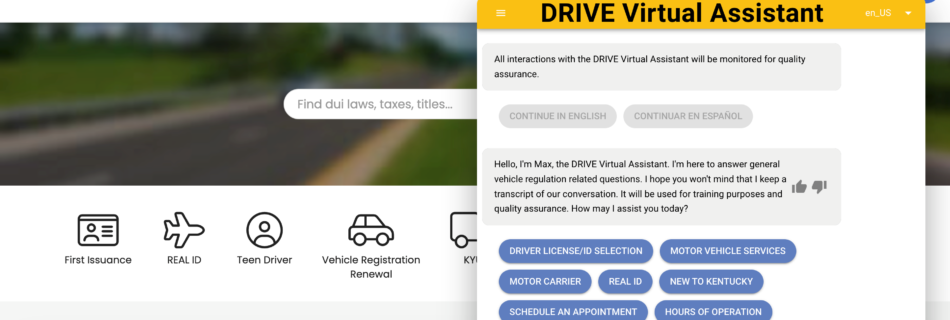
Reduce call hold time and improve customer experience with self-service virtual agents using Amazon Connect and Amazon Lex
This post was co-written with Tony Momenpour and Drew Clark from KYTC. Government departments and businesses operate contact centers to connect with their communities, enabling citizens and customers to call to make appointments, request services, and sometimes just ask a question. When there are more calls than agents can answer, callers get placed on hold …