Implement a backup strategy for Amazon Quick Sight BI assets
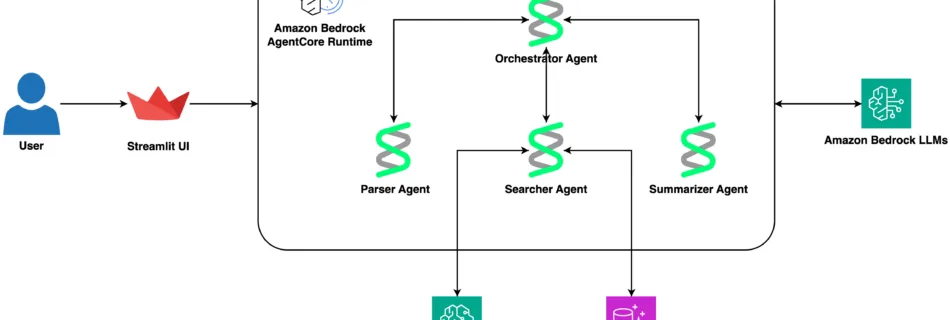
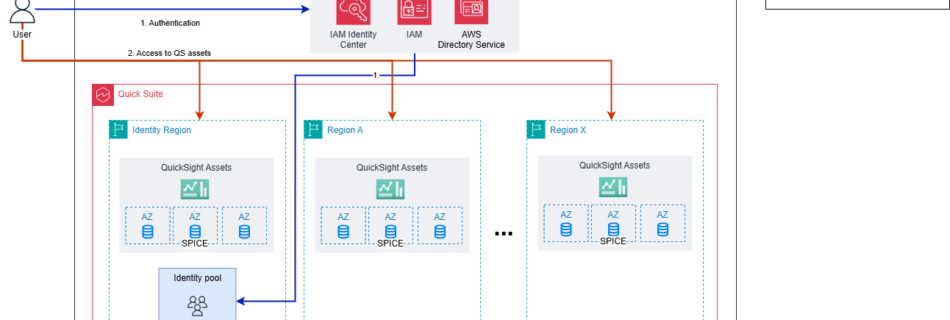
Amazon Quick Sight is a core feature within Amazon Quick — an agentic, AI-powered digital workspace designed to maximize end-user productivity— that provides AI-powered BI capabilities through natural language queries, interactive dashboards, and embedded analytics from trusted enterprise data sources. Amazon Quick Sight assets such as dashboards, analyses, datasets, and data sources can be backed up using the …
Read more “Implement a backup strategy for Amazon Quick Sight BI assets”