The End-to-End Agentic AI Pipeline
In this article, you will learn the seven architectural components that separate a production-grade agentic AI system from a demo script, and how each one…
In this article, you will learn the seven architectural components that separate a production-grade agentic AI system from a demo script, and how each one…
In this article, you will learn how Ollama, LM Studio, and llama.cpp differ across the dimensions that matter most to practitioners, and how to choose…
Figure 1: CUDA-to-MLX optimization translation map. CUDA optimization knowledge can be translated into architecture-native MLX strategies rather than copied instruction-for-instruction. We face a new epoch in computing. Hardware is changing rapidly — not just faster GPUs, but a growing range of chips from different vendors, each with its own architecture and often tailored to specific …
Read more “From CUDA to MLX: How K-Search Brings Decades of Kernel Expertise to Apple Silicon”
Memory & State For AI Agents Building an AI agent can be tricky. Keeping it on track over a six-month deployment is incredibly hard. LLMs…
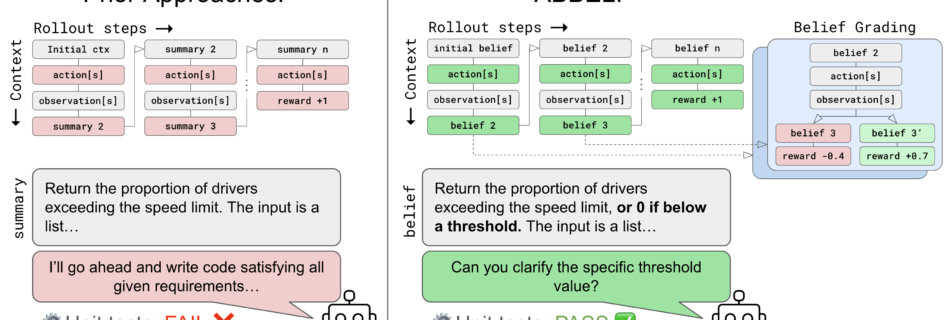
Overview of ABBEL compared to traditional recursive summarization. Beliefs replace the full interaction history as the agent’s working context, and belief grading improves performance by supervising the contents of each belief state.. As task horizons grow, LLM contexts can’t scale forever. Self-summarization enables concise, interpretable contexts, but at a significant performance cost, especially for human …
Read more “Teaching LLMs to Update Beliefs for Efficient Long-Horizon Interaction”
In this article, you will learn how an agent’s approach to managing state — stateless or stateful — shapes both its implementation and the deployment…
It’s tempting to treat loop engineering as something invented in a single week in June, but the mechanics behind it are closer to five years old, and knowing the lineage is what separates a real understanding of the idea from just repeating the trend piece.
In this article, you will learn how agentic AI architecture has evolved by mid-2026, including the shift away from orchestrated reasoning loops, the rise of…
In this article, you will learn how to build a complete agentic workflow in Python with LangGraph, from a single model call to a tool-using…
In this article, you will learn what prompt injection and tool misuse are in the context of agentic AI systems, and which defense strategies experts…