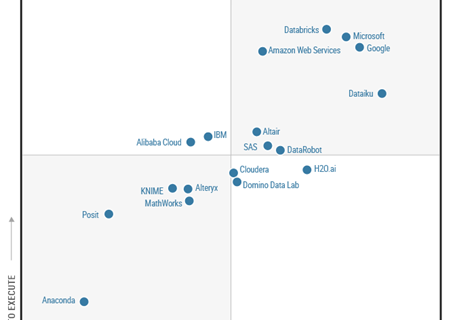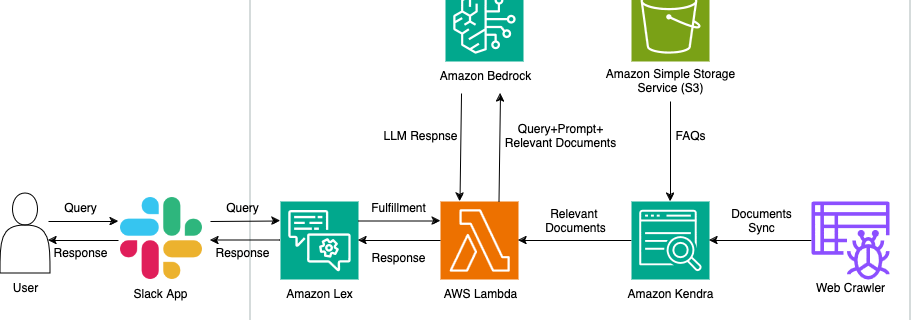
Build a generative AI Slack chat assistant using Amazon Bedrock and Amazon Kendra
Despite the proliferation of information and data in business environments, employees and stakeholders often find themselves searching for information and struggling to get their questions answered quickly and efficiently. This can lead to productivity losses, frustration, and delays in decision-making. A generative AI Slack chat assistant can help address these challenges by providing a readily …
Read more “Build a generative AI Slack chat assistant using Amazon Bedrock and Amazon Kendra”