Build an Amazon Bedrock based digital lending solution on AWS
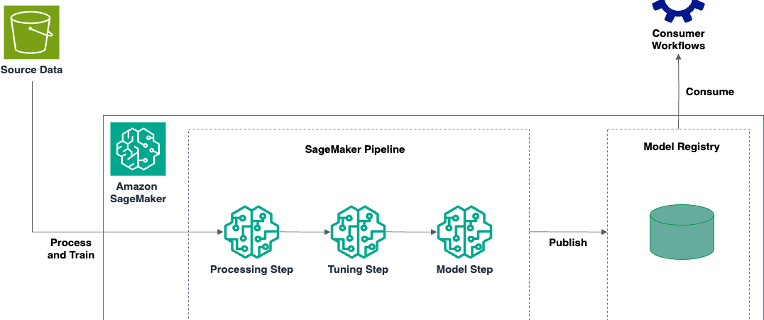
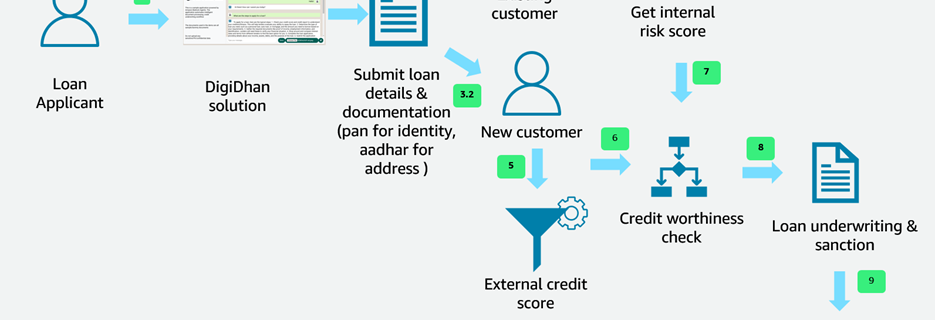
Digital lending is a critical business enabler for banks and financial institutions. Customers apply for a loan online after completing the know your customer (KYC) process. A typical digital lending process involves various activities, such as user onboarding (including steps to verify the user through KYC), credit verification, risk verification, credit underwriting, and loan sanctioning. …
Read more “Build an Amazon Bedrock based digital lending solution on AWS”