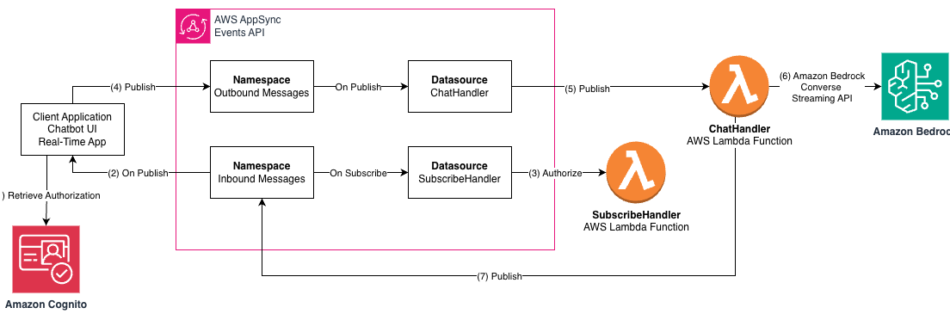
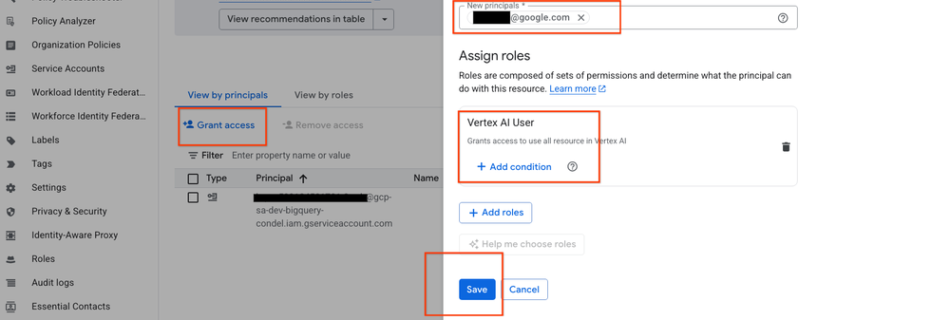
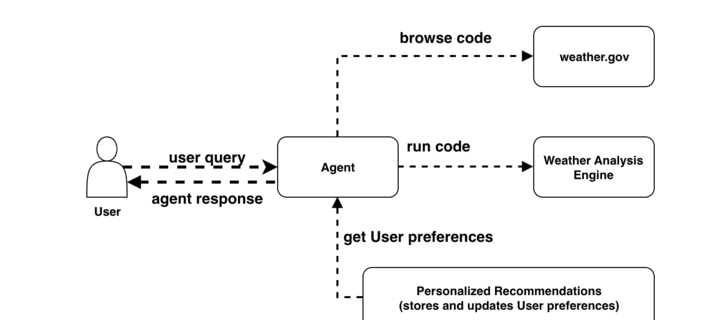
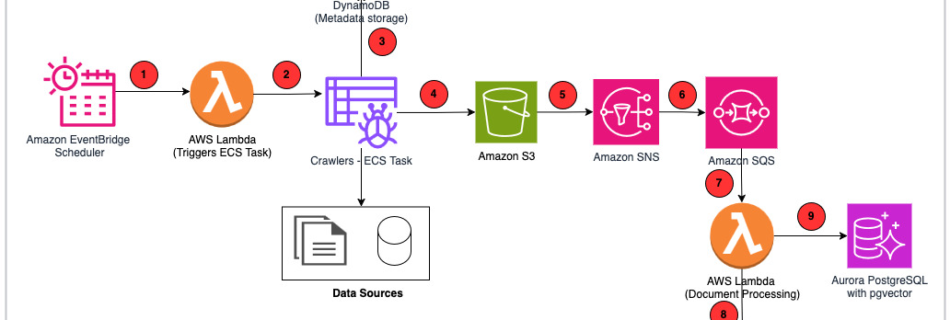
The AI Evolution of Graph Search at Netflix
The AI Evolution of Graph Search at Netflix: From Structured Queries to Natural Language By Alex Hutter and Bartosz Balukiewicz Our previous blog posts (part 1, part 2, part 3) detailed how Netflix’s Graph Search platform addresses the challenges of searching across federated data sets within Netflix’s enterprise ecosystem. Although highly scalable and easy to configure, …