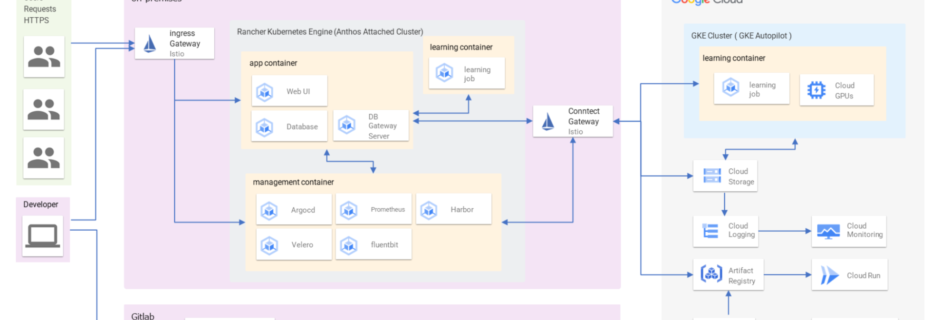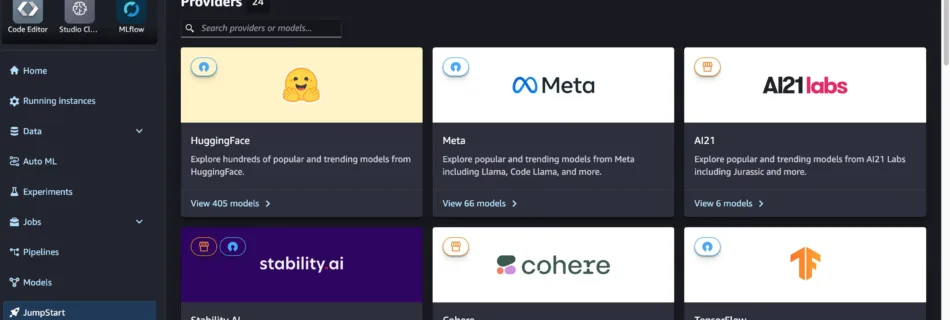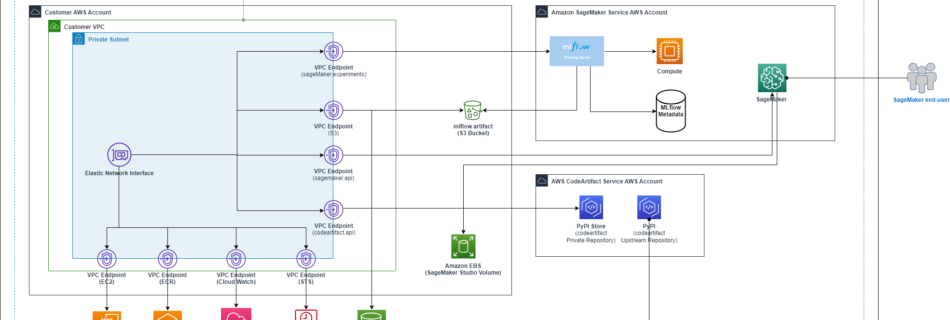
Accelerating ML experimentation with enhanced security: AWS PrivateLink support for Amazon SageMaker with MLflow
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker, users want a seamless and secure way to experiment with and select the models that deliver the most value for their business. In the initial stages of an ML …