HighLevel is an all-in-one sales and marketing platform built for agencies. We empower businesses to streamline their operations with tools like CRM, marketing automation, appointment scheduling, funnel building, membership management, and more. But what truly sets HighLevel apart is our commitment to AI-powered solutions, helping our customers automate their businesses and achieve remarkable results.
As a software as a service (SaaS) platform experiencing rapid growth, we faced a critical challenge: managing a database that could handle volatile write loads. Our business often sees database writes surge from a few hundred requests per second (RPS) to several thousand within minutes. These sudden spikes caused performance issues with our previous cloud-based document database.
This previous solution required us to provision dedicated resources, which created several bottlenecks:
Slow release cycles: Provisioning resources before every release impacted our agility and time-to-market.
Scaling limitations: We constantly battled DiskOps limitations due to high write throughput and numerous indexes. This forced us to shard larger collections across clusters, requiring complex coordination and consuming valuable engineering time.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3e60750d80a0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Going serverless with Firestore
To overcome these challenges, we sought a database solution that could seamlessly scale and handle our demanding write requirements.
Firestore‘s serverless architecture made it a strong contender from the start. But it was the arrival of point-in-time recovery and scheduled backups that truly solidified our decision. These features eliminated our initial concerns and gave us the confidence to migrate the majority of HighLevel’s workloads to Firestore.
Since migrating to Firestore, we have seen significant benefits, including:
Increased developer productivity: Firestore’s simplicity has boosted our developer productivity by 55%, allowing us to focus on product innovation.
Enhanced scalability: We’ve scaled to over 30 billion documents without any manual intervention, handling workloads with spikes of up to 250,000 RPS and five million real-time queries.
Improved reliability: Firestore has proven exceptionally reliable, ensuring consistent performance even under peak load.
Real-time capabilities: Firestore’s real-time sync capabilities power our real-time dashboards without the need for complex socket infrastructure.
Firestore powering HighLevel’s AI
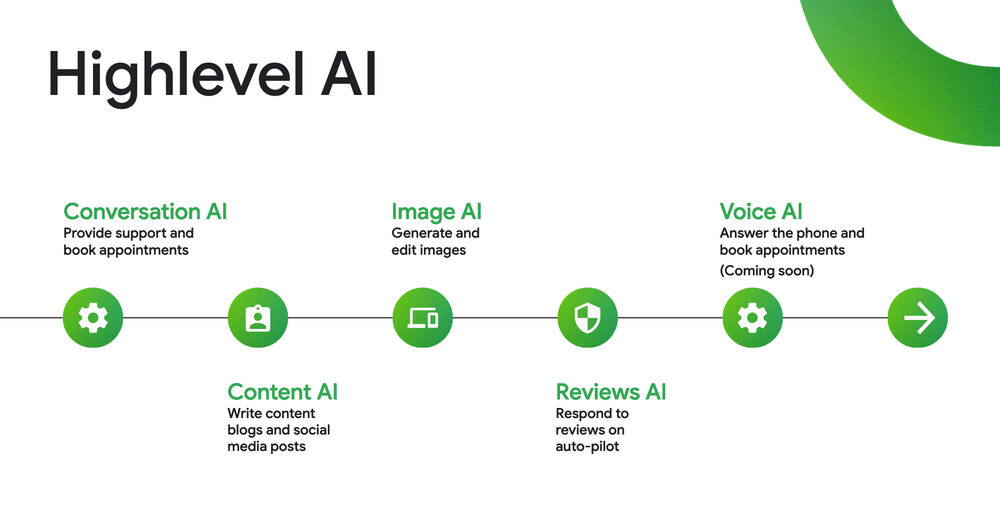
Firestore also plays a crucial role in enabling our AI-powered services across Conversation AI, Content AI, Voice AI and more. All these services are designed to put our customers’ businesses on autopilot.
Fig. 1: HighLevel AI features
For Conversation AI, for example, we use a retrieval augmented generation (RAG) architecture. This involves crawling and indexing customer data sources, generating embeddings, and storing them in Firestore, which acts as our vector database. This approach allows us to:
- Overcome context window limitations of generative AI models
- Reduce latency and cost
- Improve response accuracy and minimize hallucinations
Fig. 2: HighLevel’s AI Architecture
Lessons learned and a path forward
Fig. 3: Google Firestore field indexes data
Our journey with Firestore has been eye-opening, and we’ve learned valuable lessons along the way.
For example, in December 2023, we encountered intermittent failures in collections with high write queries per second (QPS). These collections were experiencing write latencies of up to 60 seconds, causing operations to fail as deadlines expired before completion. With support from the Firestore team, we conducted a root-cause analysis and discovered that the issue stemmed from default single-field indexes on constantly increasing fields. These indexes, while helpful for single-field queries, were generating excessive writes on a specific sector of the index.
Once we understood the root cause, our team identified and excluded these unused indexes. This optimization resulted in a dramatic improvement, reducing write-tail latency from 60 seconds to just 15 seconds.
Firestore has been instrumental in our ability to scale rapidly, enhance developer productivity, and deliver innovative AI-powered solutions. We are confident that Firestore will continue to be a cornerstone of our technology stack as we continue to grow and evolve. Moving forward, we are excited to continue leveraging Firestore and Google Cloud to power our AI initiatives and deliver exceptional value to our customers.
Get started
Are you curious to learn more about how to use Firestore in your organization?
Watch our Next 2024 breakout session to discover recent Firestore updates, learn more about how HighLevel is experiencing significant total cost of ownership savings, and more!
Learn more about Firestore and start a free trial today!
This project has been a team effort. Shout out to the Platform Data team — Pragnesh Bhavsar in particular who has done an amazing job leading the team to ensure our data infrastructure runs at such a massive scale without hiccups. We also want to thank Varun Vairavan and Kiran Raparti for their key insights and guidance. For more from Karan Agarwal, follow him on LinkedIn.