
Evaluating Generative AI (Engineering Responsible AI, #4)
A Field Manual

Editor’s Note: This is the fourth post in a series on Responsible AI and expands on the topic of AI Testing & Evaluation (T&E) introduced in the previous post.
Introduction
In the previous blog post in this series, we introduced AIP Evals, which provides users with the capabilities to efficiently test their Generative AI systems and empirically validate improvements, enabling organizations to more confidently deploy their AI solutions in production.
In this post, we dive deeper into some of the tradecraft behind testing Generative AI, based on our firsthand experience working with our customers as they apply AI to their most critical challenges. Some of the approaches we cover are basic building blocks that are well-known in the AI/ML community, like how to effectively use ground-truth evaluation data. Other techniques, like LLM-as-a-Judge evaluators or perturbation testing, are more advanced and may only be relevant for certain use cases. Taken together, we hope these techniques can guide you through the common workflows and challenges in Generative AI T&E, so you can field more robust, reliable, and effective AI systems in production.
Designing a Testing Plan
What do you want to test?
When working with our customers on designing a T&E strategy for Generative AI, we often start the conversation with a simple but critical question: what do you want to test?
One of the common pitfalls in working with LLMs is the temptation to treat these models as one-size-fits-all solutions for many disparate problems. For example, some might describe their use of an LLM as “chat.” This framing, however, leads to two issues: first, it is defined abstractly, detached from the context in which the AI-generated content will be used for decision-making. This kind of context is essential for T&E. Interacting with an LLM to generate a travel plan requires very different T&E than interacting with an LLM to generate code for a mission-critical system. Second, the “chat” paradigm groups distinct user workflows — such as summarization, translation, information retrieval, and question answering — into a single, overly broad category. While this might accurately describe how some users interact with an LLM, the ability to “chat” is not the primary focus from an evaluation perspective, but rather simply the mode of delivering a result.
Instead, the most successful AI T&E strategies require an up-front analysis of what actually needs to be tested. We recommend considering two separate aspects of any use of AI to address both the “macro” and “micro” elements of the AI workflow:
- End-to-end Workflow: Ultimately, AI should be used to advance workflow objectives, such as writing emails, predicting maintenance dates, or triaging tickets. It is helpful to zoom out and consider the entire operational workflow where AI is embedded, as well as the outcomes that AI aims to enable. These types of T&E metrics often describe fundamental elements (the nouns) and actions (the verbs) of the operational process — such as the number of patients discharged, the delay in insurance underwriting, or the rate of shipping throughput — without focusing on the specific application of AI.
- “Testable” AI Tasks: On the other hand, it is also helpful to break down complex, multi-step workflows into smaller components, where we can evaluate each part more precisely. For instance, when using an LLM to answer questions about a set of reference documents, we can break this process down into two distinct tasks: document retrieval and question-answering. Each of these tasks has unique invariants and testing strategies, and they may require different subject-matter experts to advise on how best to incorporate AI for the specific task. This kind decomposition enables us to use general-purpose models effectively by tailoring the evaluation process of each individual AI task.
Tip #1: Incorporate T&E metrics to assess improvements in both the entire end-to-end workflow and “testable” AI tasks.
What does “good” look like?
The next step is determine how to evaluate the AI system on a workflow or task. One way to think about this is by asking yourself: what does “good” look like?
When considering the entire end-to-end workflow where AI is embedded, it is beneficial to define and measure Key Performance Indicators (KPIs) that can be used as proxies for the ultimate result — even if AI is only used for one component of the entire process. For example, if you are using an LLM to assist with routing shipments to certain factories, the percentage of misrouted shipments can be used as an evaluation criteria that represents how the inclusion of AI components affects the routing optimization workflow’s overall efficacy. By incorporating Workflow KPIs in your T&E strategy, you can better mitigate the risk of T&E only improving parts of the process without improving the whole workflow.
Determining what “good” looks like for a specific task can be more challenging. Take summarization, for example. There can be many “good” summaries for a single source document, as multiple valid summaries often exist. This pattern is common in many uses of Generative AI: the stochastic, “generative” nature of these models can produce unique yet similar responses for the same input. This variability makes it harder to measure accuracy in the same way we would for a “traditional” AI task like binary classification.
In such cases, we can determine whether our AI systems meet our criteria for “good” by describing and evaluating the qualities or characteristics the model’s output should ideally exhibit, even when “good” isn’t strictly defined. To do this, it is helpful to break down a task into two components — syntax and semantics — and evaluate them separately.
Syntax represents the physical or grammatical structure of the LLM response. Below are a few examples of how we might evaluate the syntax of the LLM output for a few tasks:
- Code Generation: Did the model output syntactically-valid code? Does it compile?
- Translation: Did the model output text in the right target language?
- Function Calling: Did the model output text for function arguments with the right types and data structures?
Semantics represents the content of the LLM response and whether it contains contextually correct information based on the model input, the prompt, and task definition. Consider the following examples of the qualities of the model response we might want to assess for semantic evaluation:
- Comprehensiveness: Does the LLM response comprehensively respond to the prompt?
- Relevance: Does the LLM response contain all of the relevant information?
- Conciseness: Is the LLM response free of extraneous information? Does it only include the relevant information?
By evaluating these aspects of Generative AI tasks separately, we can gain a clearer understanding of where the model excels and where it may need improvement. This approach also allows us to tailor the evaluation methodology for each evaluation criterion. For example, it’s often easy to evaluate questions of syntax with software-defined checks; however, assessing semantics may require more advanced techniques, especially in cases where we lack ground truth data, as we discuss later.
Tip #2: When considering evaluation criteria for LLM-performed tasks, consider both the syntax and semantics of the model’s output, and evaluate them separately.
Once you have identified the tasks you want to test and the criteria for evaluation, it’s time to get started putting your T&E strategy into practice.
Evaluation With Ground Truth
Testing and Evaluation (T&E) of AI models often relies on evaluation datasets that represent the “ground truth,” where for each data point, the model’s prediction is compared against an expected value. This type of testing against ground truth data can still be valuable for Generative AI.
Importantly, this “ground truth” data does not always have to come from real, historical examples. Sometimes, we call this evaluation dataset “reference data” to better highlight that it may simply contain examples useful for assessing the model’s performance when we have some expectation of what the model’s output should be for a given case.
Curating “Ground Truth” Evaluation Data
Different approaches for curating this kind of data come with their own tradeoffs regarding comprehensiveness, context-specificity, quality, and more. In all cases, it is important to work with domain experts and users to identify or create ground truth data and continuously iterate with these stakeholders throughout the T&E process. Let’s explore at a few methods below:
- Using Open-Source Benchmarks: Using open-source benchmark datasets can be particularly helpful when customizing a general-purpose model through fine-tuning, prompt engineering, or tool augmentation, and want to ensure that such customizations do not degrade the model’s basic abilities. For example, giving an LLM the ability to query documents might introduce contradictory information from different sources, potentially weakening the model’s question-answering capabilities. Standard benchmarks can help monitor the model’s baseline performance as you iterate on the document corpus and adjust the LLM prompts. Since benchmarks may not capture context-specific nuances of your workflows, they should be used alongside other evaluation methods.
- Writing Unit Tests: Unit testing is valuable for capturing knowledge from subject matter experts about your AI system. For example, you might want to test that your LLM gracefully handles edge cases known to be challenging or that the LLM can answer common questions in an expected manner as a way of sanity checking the model’s performance. These tests are often manually written to account for specific scenarios or potential adversarial inputs that you want to proactively assess your AI system’s performance against.
- Leveraging Historical Data: When Generative AI is used to improve an existing workflow, it’s useful to compare the performance of the AI system against a baseline of historical data. For instance, in the example from our previous blog post, we built a test suite based on historical product recall decisions and their associated defect reports. We then evaluated the LLM’s recall predictions against this known data to understand how the model would have performed and which decisions would have been made differently had we used the LLM-based approach in the past.
- Producing Synthetic Test Data: When comprehensive ground truth data is unavailable, generating synthetic examples or augmenting existing data sources can be beneficial. Although it may seem counterintuitive to create synthetic “ground truth” data, this approach can help build a comprehensive dataset to understand expected model behavior. For example, in document information extraction tasks, one common approach is to have an LLM generate question-answer pairs based on the text within a document. You can then evaluate how well a Generative AI system responds to these questions based on the generated answers.
AIP provides all these approaches at your fingertips. You can seamlessly integrate open-source or historical data directly into the Ontology and use it to back test suites in AIP Evals. You can also generate synthetic data in Code Repositories or Pipeline Builder — and even use an LLM in Pipeline Builder to help augment an existing dataset.
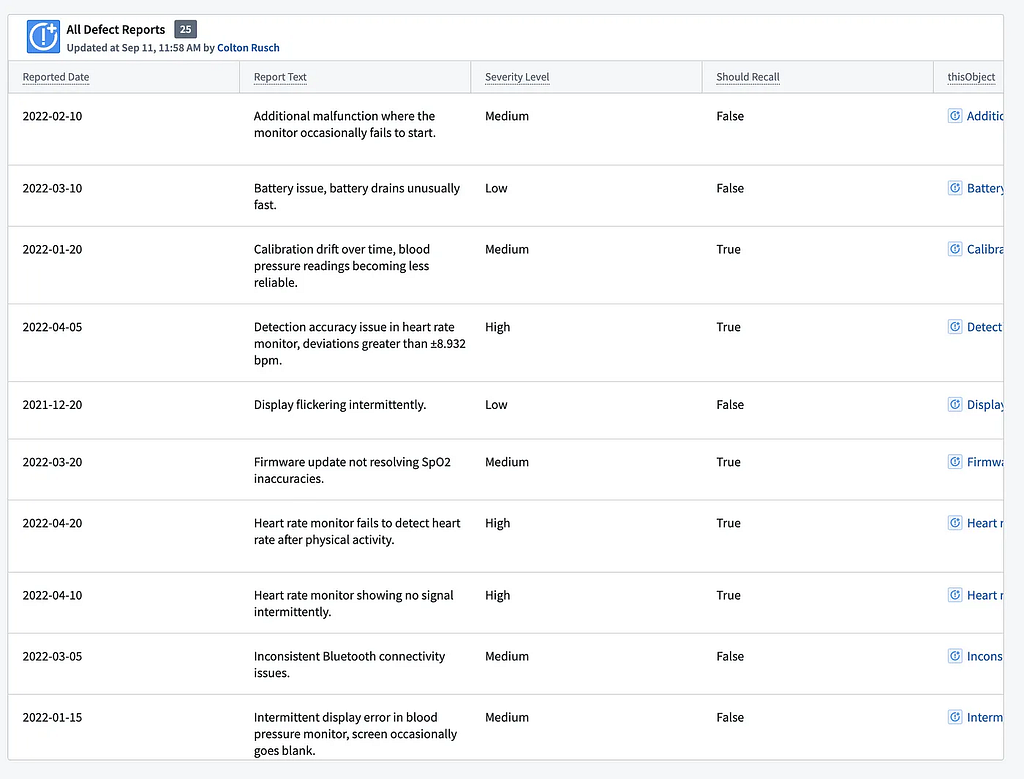
Tip #3: Engage with domain experts and users to identify or generate “ground truth” data. Obtain feedback on the specific successes and failures of the AI solution compared to the prior baseline. Continuous input and feedback from those who deeply understand the operational workflow where AI is being introduced are critical for using AI both responsibly and effectively.
Designing Evaluators
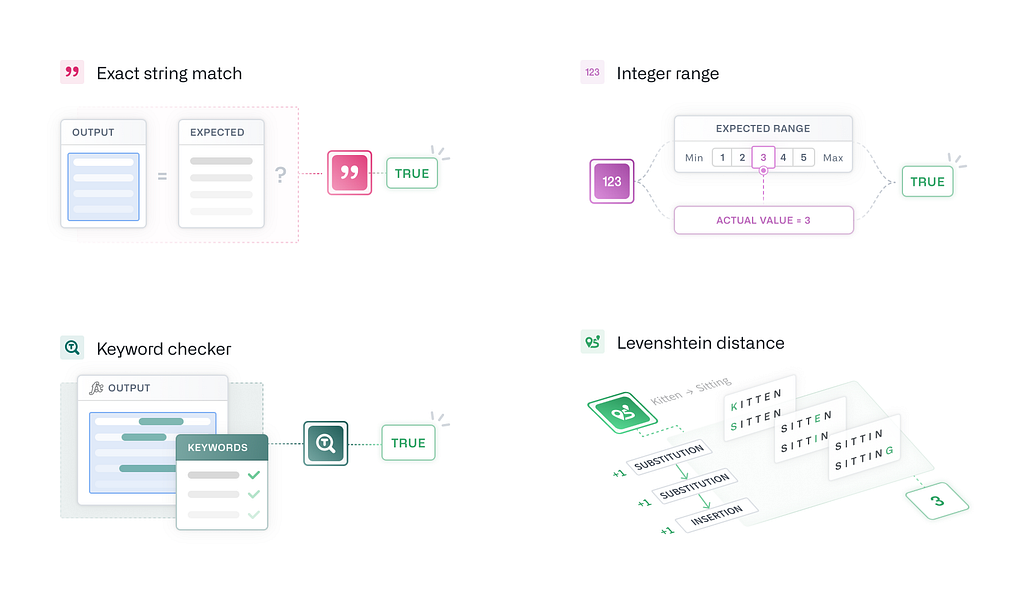
Once we have “ground truth” data for evaluation, we need to design “evaluators” to produce metrics that help us understand how the LLM output performs relative to this data. For example, it could be as easy as doing an “Exact Match” comparison to directly compare the LLM’s output and the expected ground truth value. However, it is sometimes useful to accept a wider range of values from an LLM. Using range comparison functions or fuzzy matches (e.g., regular expressions, keyword matches, cosine similarity) can help account for the variety of “correct” answers an LLM could produce for a given input.
Tip #4: For more flexible comparisons against ground truth, use regular expression and “fuzzy match” comparison evaluators like Levenshtein distance, cosine similarity, or range intervals when “exact match” evaluators are too restrictive.
AIP Evals provides several default evaluators for both exact match and fuzzy comparison. Additionally, AIP enables you to write custom evaluators to incorporate more advanced T&E metrics, tailoring T&E to your specific use case. For example, you may want to use a word embedding model to assess the similarity between a reference text and LLM-generated text based on cosine similarity. Or, you may prefer to use your favorite open-source package or custom business logic to compute domain-specific metrics. In AIP, you can write these custom evaluators in Functions and publish them for use in your evaluation suite within AIP Evals.
Evaluation Without Ground Truth
Even when ground truth data is available, it may not capture the full breadth of qualities that define “good” model responses. This is especially true for tasks involving natural language output, where a variety of qualities are necessary for a response to be considered “good.” Relying solely on ground truth data in these cases would require multiple examples for each input to cover all relevant characteristics, which is challenging to achieve in practice. Instead, we can employ evaluation techniques that directly assess the desired characteristics of the model outputs without comparing them to reference examples.
Deterministic Evaluators
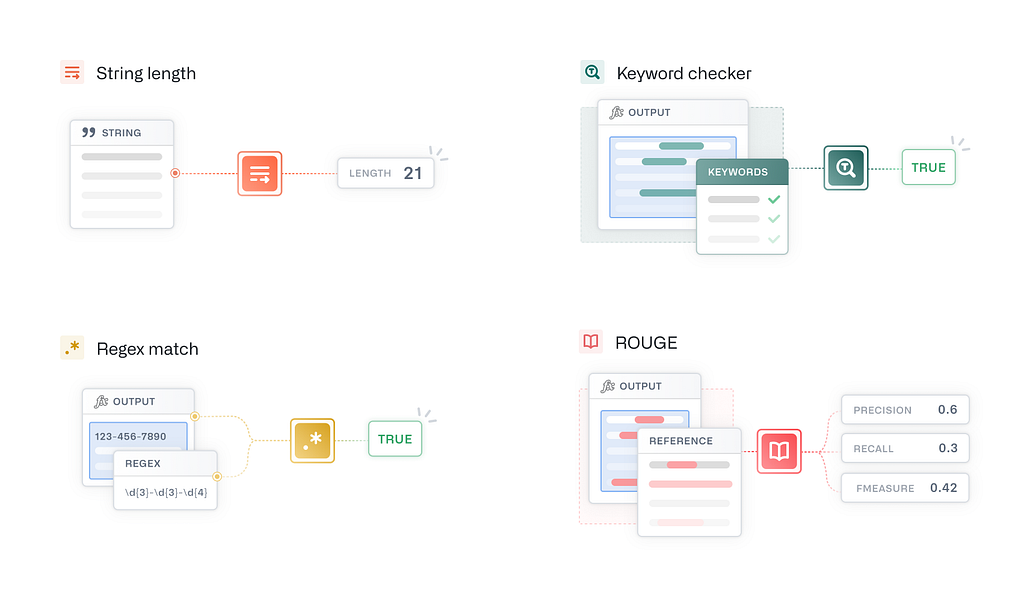
Deterministic evaluators allow you to directly evaluate qualities of the LLM output. For example, in a summarization task, we might want to ensure that the LLM output is shorter than the reference text it is summarizing or that the summary is in the correct language. To evaluate conciseness, we could measure the length of the summary. For language identification, we could use a Natural Language Processing (NLP) library. Neither of these “evaluators” requires a “ground truth” value for comparison. Instead, they rely on “reference-less”, deterministic methods that evaluate the LLM output based on certain parameters. By applying several such evaluators for the characteristics you want to ensure in your LLM response, you can start to put together a holistic picture of the different facets of what “good” might look like for a specific AI task.
Tip #5: Use deterministic evaluators to assess various characteristics or heuristics expected from the LLM response.
AIP Evals comes with several built-in deterministic, reference-less evaluators by default, including “String Length,” “Regex Match,” “Keyword Checker,” and a ROUGE scorer. You can also write custom evaluators to meet specific needs. While many of these evaluators can also be used with ground truth data, they serve as a good starting point for T&E, especially if ground truth data is not yet available.
LLM-as-a-Judge Paradigm
Another common approach to evaluate the effectiveness of an LLM is by using a second, “evaluator” LLM. This approach is often referred to as “LLM-as-a-Judge” [1]. In AIP, you can easily employ an LLM-backed AIP Logic function as an evaluator in AIP Evals, making this T&E technique both easy and accessible without requiring any code. With LLM-as-a-Judge evaluators at your fingertips, here are a few best practices to keep in mind:
- LLM-as-a-Judge Prompt Design: The key challenge of designing an LLM-as-a-Judge evaluator is writing a prompt that effectively captures your evaluation criteria. For example, you could ask the LLM to evaluate the summarization of news reports with questions like: “Does the summary capture the key points from the news report?” or “Is the summary concise without omitting key details?,” and so on. To tailor these questions to your specific use case, we recommend writing “multi-shot” prompts for the evaluator LLM, where the prompts include a few examples. In this case, you would provide examples of news reports, good summaries, and the expected evaluator outputs. This approach provides the evaluator more context on how to assess the model output (i.e., the summary) in relation to the model input (i.e., the original news report) and the specific evaluation questions.
- Pass/Fail Evaluators: We recommend framing the prompts for LLM-as-a-Judge evaluators as binary, pass/fail questions rather than using numeric scales to grade responses. Pass/fail questions make evaluation results immediately actionable by clearly indicating whether a response meets the specified criteria or not. In contrast, numeric scoring, such as rating responses on a 1–5 scale, can lead to outcomes that are difficult to action as it’s not always evident what distinguishes a score of 3 from a 4, and how those scores should inform improvements to the LLM under evaluation. [2] Evaluator LLMs that produce numeric scores can be useful as an initial step when collaborating with a domain expert to develop evalution criteria. However, these numeric rankings can often be refined into pass/fail evaluators — and even combined to produce a composite “score” from several yes-or-no decisions.
- Cost: One challenge of using LLM-as-a-Judge evaluators is that LLM calls are often expensive, both in terms of cost and latency. This is especially true if you are ensembling the results of several different LLM-as-a-Judge evaluators in a k-LLM approach. To mitigate these challenges, we recommend using LLM-as-a-Judge evaluators for heuristics that can be assessed with simple LLM calls and do not require complex, multi-step LLM reasoning. Also consider applying LLM-as-a-Judge evaluators to a sample of the evaluation dataset, while using more efficient evaluators on the entire test suite.
- Evaluating the Evaluator: LLM-as-a-Judge evaluators should undergo evaluation to ensure their effectiveness. This can be done by using Deterministic Evaluators and Unit Tests as you develop the prompts. Importantly, framing your evaluator LLM’s prompt as a yes-or-no question can make it easier to design good evaluator LLMs, as this question format makes it easier to align the evaluation process with human preferences and expectations. Collaborating with a domain expert to generate a “golden dataset” of pass/fail determinations for the characteristics being evaluated is more straightforward and reliable than devising and implementing a novel numeric scoring system.
- LLM-as-a-Judge with Ground Truth data: The LLM-as-a-Judge approach can provide additional insights, especially when the evaluation criteria are subjective, even ground truth data is available. For instance, you could use an evaluator LLM to assess whether a generated summary matches the tone of a reference summary.
Tip #6: When using LLMs to evaluate other LLMs, define clear, binary pass/fail criteria based on input from domain experts and end-users. Avoid LLM-as-a-Judge evaluators that incorporate complex scoring or ranking systems.
Testing for Robustness and Consistency
Most T&E approaches focus on evaluating the accuracy of an AI system. For Generative AI, we’ve found that it is also important to evaluate for robustness. Since Generative AI models are non-deterministic and highly sensitive to small variations in input, we have a few recommendations for how to better understand the consistency and robustness of your AI system during the T&E process.
Handling Non-Determinism
Running the same input through a Generative AI model can yield different outputs due to architectural elements that introduce randomness, such as temperature parameters or top-k sampling. While this randomness can enhance the creativity of LLM responses — which is sometimes desirable for specific generative tasks — it can complicate evaluation, and underscores the importance of evaluating the consistency of your model responses.
Tip #7: In cases where this non-determinism is undesirable, tune relevant model hyperparameters to reduce it where possible (e.g., lowering the “temperature” value to 0).
Regardless, there will always be some variability in Generative AI outputs. To account for this, it’s important to run each test case multiple times and analyze the aggregate results. AIP Evals facilitates this by allowing you to specify how many times to run each test case in your evaluation suite. By examining the distribution of outputs, you can assess the consistency and stability of your AI model’s performance. From there, you can address undesirable non-determinism via techniques like prompt engineering and preprocessing data to eliminate sources of ambiguity or contradiction.
Tip #8: Run each test case multiple times to capture the variability in your model’s outputs. Analyze aggregate metrics to assess consistency and identify outlier behaviors that may need attention.
Perturbation Testing
Real-world data is inherently messy. Users make typos, data formats change, and inputs come in all shapes and sizes. For your AI systems to be successful in these real-world contexts, they must be capable of gracefully handling such irregularities and diversity.
Perturbation testing is a technique that involves systematically modifying inputs to evaluate your model’s robustness to variations and noise. By introducing controlled changes to your test cases, you can uncover how sensitive your model is to different types of input perturbations, such as typos, synonyms, random noise, and more. For instance, if your model performs sentiment analysis, you might test how it handles reviews with typos, slang, or emojis. Does the model still accurately detect positive or negative sentiments when the input isn’t perfectly formatted or contains synonyms for certain phrases?

Beyond testing for robustness, perturbation testing is also a powerful tool for other aspects of Responsible AI. For example, by altering demographic details in inputs — such as names, genders, or cultural references — you can observe if the model reflects embedded bias. This can help uncover hidden failure modes of your AI system that might lead to undesirable disparate impacts if deployed in real-world contexts. Additionally, perturbation testing can reveal vulnerabilities to adversarial inputs. Malicious actors might exploit weaknesses by crafting inputs that confuse the model. By proactively testing with such perturbations, you can strengthen your model against potential attacks.
Tip #9: Use perturbation testing to evaluate your model’s resilience to input variations and uncover potential biases.
So, how do you perform perturbation testing in AIP? Let’s walk through a brief example. Suppose you’re developing an AI model to extract key information from medical notes — such as patient symptoms, diagnoses, and prescribed treatments. Using AIP, you can implement perturbation testing by automating the generation of new test case Objects that are variations of your original medical notes. Let’s go step by step:
Step 1: Define Perturbation Logic: Use Pipeline Builder, Functions, or Transforms in AIP to systematically introduce changes to specific fields in your medical note Objects. This can be done using either deterministic logic or LLM-based functions. Consider the following perturbation strategies:
- Synonym Replacement: Swap out medical terminology with synonyms, medical abbreviations, or non-expert terms to see if the model still correctly interprets the information.
- Typos and Misspellings: Introduce common misspellings in medication names or medical terms to test the model’s ability to handle errors.
- Demographic Alterations: Change implicit or explicit patient details such as age, gender, or ethnicity to assess if the model’s performance remains consistent across different demographics.
- Noise Injection: Add irrelevant text, extraneous information, or format variations to the notes to evaluate the model’s ability to focus on only the context relevant to the task at hand.
- Adversarial Inputs: Introduce adversarial inputs such as prompt injection attacks to evaluate the model’s resilience against manipulation or exploitation attempts.
Step 2: Generate Perturbed Objects: Execute your perturbation logic to create new Objects that mirror your original Object type but with controlled variations. This results in a set of test Objects with realistic, notional examples that the AI system might encounter in practice.
Step 3: Run Evaluations on Perturbed Objects: Use Object-Set-backed Evaluation Suites in AIP Evals to run your perturbed Objects through a set of Evaluators.
Step 4: Analyze Evaluation Metrics: By running evaluations on these perturbed Objects, you can compare how performance metrics change with different perturbations. For example:
- Does the model’s accuracy drop significantly when typos are introduced in medication names?
- Does performance vary when patient demographic details are altered?
- How does added noise affect the extraction of key information?
By conducting perturbation testing, you gain valuable insights into specific weaknesses and failure modes of your AI system. In this example, the results of perturbation evaluations can help to determine whether the model needs improvement in handling misspelled terms, requires adjustments to maintain performance across different demographics, or needs enhanced filtering mechanisms to manage irrelevant information effectively.
Conclusion
These insights shared here on T&E for Generative AI are just the beginning. There’s a wealth of topics to explore — from A/B testing and post-deployment evaluation to drift monitoring and beyond. As the underlying technologies evolve and use cases mature, we’ll continue to find new ways to better understand the performance of Generative AI.
If we can leave you with one take-away, it’s this: testing & evaluation is integral to your success when working with AI. We strongly encourage you to get started with the T&E methods we described above and to experiment with new approaches that suit the context, workflow, and users of your AI applications.
For those new to Palantir software, head over to build.palantir.com to get started with AIP. Prepare to leverage tools like Pipeline Builder, the Ontology, AIP Evals, and an extensive suite of platform tools to create a T&E strategy tailored to your specific use case and needs. If you’re already an AIP user, we’re excited to hear how T&E has helped you put Responsible AI into practice.
Authors
Arnav Jagasia, Head of Software Engineering for Privacy and Responsible AI
Colton Rusch, Privacy and Civil Liberties Engineer
[1] LLM-as-a-Judge was coined as a term in this paper: https://arxiv.org/abs/2306.05685.
[2] For more examples of how pass/fail LLM-as-a-judge is useful, see https://hamel.dev/blog/posts/llm-judge/
![]()
Evaluating Generative AI: A Field Manual was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.