By Nipun Kumar, Rajat Shah, Peter Chng
Introduction
This is the first blog post in a multi-part series that shares technical insights into how our ML model serving infrastructure powers several personalized experiences at scale across various domains (e.g., title recommendations, commerce). In this introductory blog post, we will dive into our domain-independent API abstraction and its traffic routing capabilities that the central ML model serving platform exposes to several domain-specific microservices for model inference. This singular API, or entry point, into the ML model serving platform has significantly increased the speed of innovation for iterating on newer versions of existing ML experiences, as well as enabling completely new product experiences with ML.
Machine Learning use cases powering member experiences on Netflix require rapid iteration and evolution in response to new learnings. The success of our ML model serving infrastructure largely depends on enabling researchers to rapidly experiment with new hypotheses and safely, at scale, release their models into production. Equally important is enabling multiple microservices at Netflix to seamlessly get model inference without exposing the complexities of ML model inference. To achieve this in a uniform and scalable manner, we created a centralized ML serving platform. As of 2025, the platform serves hundreds of model types and versions, netting 1 million requests per second. In this post, we’ll zoom in on a core challenge of any large-scale ML serving system: How to route traffic to the right model instance, on the right cluster shard, for the right user and use case, while preserving a simple abstraction for both client services and model researchers.
Background
Models at Netflix
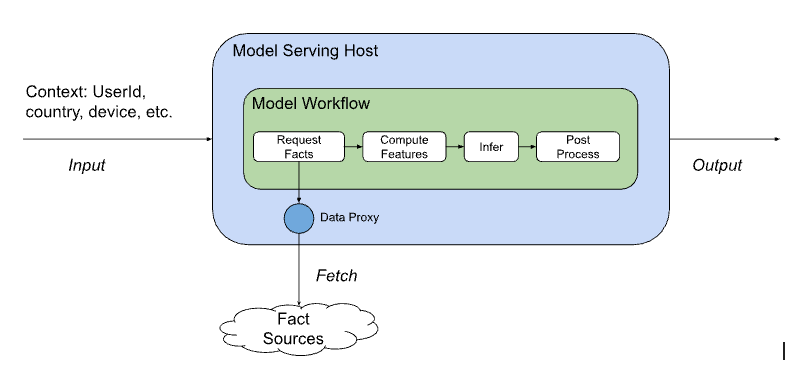
To properly frame our discussion, let’s first clarify the distinction between model serving and model inference. At Netflix, the definition of an ML model has historically been somewhat unique. While model inference typically focuses only on an infer(features) -> score capability, models at Netflix act as self-contained workflows that transform inputs to outputs. A “model” encapsulates pre- and post-processing, feature computation logic, and an optional ML-trained component, all packaged in a standard format suitable for use across multiple contexts. We refer to the end-to-end execution of this workflow as model serving. This distinction matters because our routing and API abstractions operate at the level of workflows, not just individual scoring functions.
A few simplified examples of model serving use cases:
Use case: Personalized Continue Watching row on Netflix Homepage
- Input: UserId, Country, Device ID
- Output: Ranked List of movies and shows (aka title): [titleId1, titleId2, titleId3,…]
Use case: Payment Fraud Detection
- Input: UserId, Country, Payment Transaction details
- Output: Probability of the transaction being fraudulent
A typical flow of this serving workflow is depicted below:

To achieve this higher level of abstraction, the model definition contains a list of facts (raw, unprocessed data or observations built as states in different business workflows) that it needs to compute features, and it relies on the model serving platform to supply these facts at serving time by calling several other microservices. Likewise, during offline training, Netflix’s ML fact store provides snapshots for bulk access to facilitate feature computation.
The important takeaway from this model definition is that the calling services only need to provide standard request context (such as userId, country, device), and the relevant domain context (such as titles to rank, or payment transaction for fraud detection), and the model can itself compute features and perform inference as part of the execution flow. This common set of request contexts across domains enables them to share a standard API abstraction and standardizes how various client microservices can uniformly integrate with the serving app. Furthermore, clients are shielded from the model selection and execution, allowing the model architecture and data inputs to evolve with minimal client coordination.
This post focuses on showcasing the technical details to support this design paradigm. We’ll first describe how we implemented this abstraction with Switchboard, a centralized routing service, and then discuss the operational challenges we encountered at scale and how they led us to the Lightbulb architecture.
ML Model Serving Platform Principles
We envisioned a central model serving platform for all of Netflix’s member-facing ML Model serving needs. This ambitious effort required principled thinking to provide the right level of abstraction for both the researchers and client applications. The following ideas, which are relevant to the topic of this blog post, ensured that the platform acts as an enabler of rapid ML innovation and limits the exposure of ML model iterations to the client apps:
- Model innovation independent of client apps: There should be only a one-time integration effort by the calling app with the ML serving platform for a new use case. After that, almost all model iterations, including intermediate model A/B experiments, should be mostly opaque to the calling apps. This implies that the platform should handle tasks such as model selection based on a user’s A/B allocation, fetching additional data needed by experimental models, logging for further training or observability, and more. This also benefits the ML researcher, as they only need to coordinate with one platform for model innovation.
- Decouple clients from model sharding: Models are distributed across multiple serving compute cluster shards, each with its own Virtual IP (VIP) Address. Various factors, such as traffic patterns, SLAs, model architecture, and CPU/Memory availability, affect model-to-cluster mapping, and changes to this mapping result in changes to the VIP address at which a model is reachable. The serving platform should make clients agnostic to such frequent VIP address changes while ensuring high availability.
- Flexible traffic routing rules: Support flexible mechanisms to introduce new traffic routing rules. This includes supporting traffic routing based on A/B experiments, providing a knob to slowly shift traffic to new models and VIP addresses, and allowing client overrides.
Introducing Switchboard
Standard out-of-the-box API Gateway solutions (such as AWS API Gateway, a standalone Service Mesh proxy) did not meet all our requirements. In particular, we needed first-class integration with Netflix’s experimentation platform, the ability to expose gRPC endpoints to clients, and the ability to use rich domain-specific context for routing customizations, which generic proxies were not designed to handle. Furthermore, the platform required customizations to model-specific lifecycle stages (shadow mode, canaries, rollbacks) to enable safe rollouts and migrations.
Hence, we embarked on building a custom service that serves as a flexible proxy layer for all traffic, handling over 1 million requests per second while maintaining high availability and reliability. We named it Switchboard.
Switchboard serves as the central entry point for the system, acting as a mandatory interface for all clients to access the appropriate model based on their context. Its role is to perform context-aware routing and to apply any configured context enrichment to the model inputs.
Here is a visual representation of the request flow from different clients to different serving clusters:

Objective Abstraction
To support this system design, we introduce the concept of an “Objective”. It’s an Enumeration defined by the serving platform that every request into the system must provide. It has three key purposes:

In short, an Objective is the serving platform’s name for a specific business use case (e.g., ContinueWatchingRanking), which decouples clients from concrete models and guides the platform’s routing and model selection decisions.
Key Capabilities of Switchboard
To summarize, these are the key capabilities of Switchboard:
- Common Client Abstraction: Switchboard provides a single point of contact for all our clients’ model needs. When clients wish to consume additional models for new ML applications addressing the same business need, there is no new service dependency to introduce or new clients to manage to make requests to the models. From an ML Ops perspective, this also gives us knobs to control client rate limits across model versions and manage central concurrency limits to deal with bad clients.
- Context-Aware Routing: Switchboard can route a request based on a rich set of contextual features, such as the user’s current device, locale, ranking surface type (e.g., home page vs. search results), or the current A/B test a user is in.
- Dynamic Traffic Splitting: It enables real-time traffic splitting for canary deployments and experimentation. This allows engineers to safely roll out a new model version to a small, controlled percentage of users before a full launch.
- Model Versioning and Lifecycle Management: Switchboard inherently manages concurrent request traffic to multiple versions of the same model. This is crucial for:
- Shadow Mode Testing: Routing production traffic to a new model version without affecting the user experience, enabling performance comparisons.
- Instant Rollback: Immediate switching of traffic away from a problematic new model version back to a stable one.
But is this the whole story? Not quite. Introducing this routing layer adds complexity to our model deployment cycles. In addition, we need a mechanism to collect the context-based routing information from the researchers when they choose to deploy model variants.
The Glue — Switchboard Rules
Given that Objectives serve as the contract between clients and the serving platform, we needed a way for researchers to attach model variants, experiments, and traffic splits to those Objectives without changing client code. This is where Switchboard Rules comes in.
The primary UX for model researchers to define models associated with an objective in a flexible manner is a JavaScript configuration, which we call Switchboard Rules. It’s used to produce a set of rules (typically a JSON file) that primarily dictate the following things to the serving platform:
- The default model to use for a given Objective
- A/B experiments to configure for a set of Objectives and the corresponding models to load for those experiments
- Customizations to gradually shift traffic to a new model
Here is an example of an A/B test rule in the context of the Continue Watching row:
/**
Configuration rule written by a Model Researcher to add an A/B experiment in the Model Serving system.
Cell 1: Uses the default, currently productized model
Cell 2 and Cell 3: Use different experimental (candidate) models
**/
function defineAB12345Rule() {
const abTestId = 12345;
const objectives = Objectives.ContinueWatchingRanking;
const abTestCellToModel = {
1: {name: "netflix-continue-watching-model-default"},
2: {name: "netflix-continue-watching-model-cell-2"},
3: {name: "netflix-continue-watching-model-cell-3"}
};
return {
cellToModel: abTestCellToModel,
abTestId: abTestId,
targetObjectives: [objectives],
modelInputType: constants.TITLE_INPUT_TYPE,
modelType: 'SCORER'
};
}
These rules are consumed by both the Switchboard and the Model Serving clusters. Given these rules, the serving platform components can take various actions, some detailed below:
Control Plane Flow:
- Assignment: Produce model-to-cluster shard assignment.
- Validation: Load all specified models into the Serving Cluster Shard and validate model dependencies to ensure successful execution.
- Mapping: Provide the model-to-shard VIP address mapping to Switchboard.
Data Plane Flow:
- Allocation: If the request is for Objective=ContinueWatchingRanking, query the Experimentation Platform for the userId’s cell allocation.
- Model Selection: Use the allocation and A/B test rule to select the appropriate model.
- Request Routing: Route the request to the serving cluster shard with the selected model and context.
- Model Execution (on the serving host): Run the model workflow steps and return the response.
A key highlight of this setup is the decoupling of the experimentation config from the serving platform code. This includes having an independent release cycle for the rules, separate from the code deployments. Netflix’s Gutenberg system provides an excellent ecosystem that enables a flexible pub-sub architecture, facilitating proper versioning, dynamic loading, easy rollbacks, and more. Both Switchboard and the Serving Cluster Host subscribe to the same Switchboard Rules configuration.
To prevent race conditions and ensure proper sync of the dynamic Switchboard Rules configuration, the following flow is considered:

Evolving Challenges
Switchboard solved the primary problem of improving model iteration and innovation velocity, and provided an excellent ML serving abstraction to over 30 service clients. However, as the system scale increased, a few challenges and problems with this design became apparent:
- Single point of failure: The presence of Switchboard in the critical request path clearly highlights the risks of shutting down access to all serving hosts in extreme cases, such as unintentional bugs or noisy neighbors sending excessive traffic.
- Why this matters: Switchboard became a shared dependency whose failure would degrade or disable multiple ML-powered experiences at Netflix.
- Added latency due to additional network hop: Switchboard in the request path adds between 10–20ms of latency due to serialization-deserialization operations, depending on payload size. Additionally, it further exposes a request to tail latency amplification.
- Why this matters: The added latency is unacceptable for some latency-sensitive clients, resulting in end-user impact due to service timeouts.
- Reduced Client flexibility: Switchboard obscures visibility into client request origins from the serving clusters. Consequently, distinguishing data logged for real vs artificial traffic, which is essential for model training, is difficult and requires ongoing customization and increased MLOps overhead.
- Why this matters: It makes it harder to do tenant separation and test traffic isolation.
What Next? — Lightbulb
The aforementioned challenges of operating Switchboard at scale forced us to rethink the core implementation while retaining its key features. Our goal was not to throw away Switchboard’s design, but to refactor where and how its responsibilities were executed, keeping the benefits while reducing risk and latency. Particularly:
- Common Client Abstraction
- Decouple clients from model sharding
- Flexible traffic routing rules
- Lightweight system client
- Single place to define model and experimentation config
- Fast experimentation config propagation
- Fallback and client-side caching in case of failures
However, we did want to address some of the previous design choices to move forward with:
- Remove the routing service from the direct request path: Having a single service in the active request path introduces another failure mode and limits fallback flexibility. While routing rules change infrequently, maintaining consistency comes at the cost of increased availability risks.
- Separate model inputs from the request metadata: In certain cases, the request payload could be quite large. Needing to deserialize and then re-serialize the payload as it flowed through Switchboard to make a routing decision was a significant contributor to latency and increased serving costs.
- Provide better isolation for the routing layer: Consolidating multiple use cases (tenants) into a single routing cluster poses two main challenges. First, error propagation posed a risk, as a surge of problematic requests from one tenant could cascade errors back to Switchboard, potentially impacting other users. Second, the cluster had to accommodate diverse latency requirements because the requests from different use cases varied significantly in complexity.
This required some changes in our setup flow: While it largely remained unchanged, however, we created separate components for Routing and Model Selection (Lightbulb):

We now take the rules for an Objective and break them into distinct sets of configuration:
- Model Serving Configuration: This allows us to determine which model should be used at request time, along with the required metadata
- Routing Rules: Given a model we want to serve at request time, this tells us which VIP the request should be routed to.
The Data Plane changes also reflect this separation, as we now rely on Envoy to take care of the routing details:

Envoy is already used for all egress communication between apps at Netflix, and it can route requests to different clusters (VIPs) based on the configurable Routing Rules published from our control plane. However, it lacks the information needed to make routing decisions and the ability to enrich the request body with additional serving parameters required for A/B testing model variants. We introduced Lightbulb to cover this gap:
- Lightbulb consumes the minimal request context, which contains use-case information, and provides the metadata mapping required for routing at the Envoy layer.
- Lightbulb resolves the request context to determine a routingKey configuration along with the ObjectiveConfig — this is where we place the model id along with other request-specific configurations required for model execution. This is done to separate the config resolution associated with the request from the placement and routing information needed to reach it on the inference cluster.
- While the routingKey is added to the headers for Envoy proxy to consume, the client adds the ObjectiveConfig parameters to the request itself. This is done to avoid bloating the request headers while passing additional parameters for the model to process the request appropriately.
- The routing of the actual request is performed by the Envoy proxy, which has the metadata to map the routingKey to the actual cluster VIP running the model. Because the routingKey is in a header, this determination can be made with minimal overhead.
These changes retain the advantages of Switchboard, such as a single integration point, abstraction of model id from use case, context-aware routing, while addressing the challenges we observed over time.
Conclusion
The evolution from Switchboard to Lightbulb marks a significant architectural refinement in our ML model serving infrastructure. While Switchboard provided the initial abstraction layer critical for rapid innovation, its latency and single-point-of-failure risk posed scaling hurdles. The subsequent adoption of Lightbulb, a decoupled service focused solely on routing metadata, and its integration with Envoy successfully resolved these challenges. This sophisticated new architecture preserves the key benefits — seamless client integration and flexible experimentation — while ensuring reliable, efficient, and scalable delivery of personalized member experiences, positioning us well for future ML growth.
In future posts in this series, we’ll dive deeper into other aspects of our ML serving platform, including inference and feature fetching, and how they interact with the routing architecture described here.
Special thanks to Sura Elamurugu, Sri Krishna Vempati, Ed Maddox, and Sreepathi Prasanna for their invaluable feedback and partnership in iterating on this idea and bringing this blog post to life.
![]()
State of Routing in Model Serving was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.