Processing millions of user reviews in real-time, under strict latency and cost constraints, is no easy task. Trustpilot has been doing exactly that with custom machine learning since long before large language models (LLMs) were cool. Now, as the company transitions its core stack to generative AI, here is a look at how we teamed up to build a high-volume streaming pipeline using fine-tuned Gemma models.
Powering deep review intelligence at scale
Trustpilot’s core business relies on delivering deep, actionable review intelligence. As a platform championing transparency and genuine feedback, it must safeguard data integrity and maximize value. This means extracting every drop of metadata from incoming reviews — making LLMs the perfect tool for the job.
These models excel at parsing messy, human-written text to run named entity recognition (NER), categorize business domains, score sentiment, and pinpoint customer intent. But while prompting an LLM for a few reviews is easy, processing millions in real-time without blowing up costs is a massive engineering hurdle.
Why fine-tune an open model?
When pursuing such a big task, why isn’t just plugging into a powerful, off-the-shelf, frontier model like Gemini the right approach? For a pipeline this critical to the core business, closed models are rarely the best option. Instead, by fine-tuning open-weight models like Gemma, Trustpilot takes full ownership of their AI strategy. Here’s how:
Total model independence: By owning its models, Trustpilot ensures it controls the retraining lifecycle, completely freeing it from a third-party vendor’s update schedule or sudden API changes.
Predictable economics: Shifting from a variable per-token pricing model to fixed infrastructure costs makes running millions of predictions financially viable and optimizable.
Expanding MLOps capabilities: Building these models in-house enables Trustpilot to bake in the “secret sauce” of its review intelligence while building competencies on open-weight models.
Architectural continuity: Standardizing on an open-weight lineage preserves the company’s ability to leverage the future iterations of the base model. This enables performance gains with minimal engineering overhead.
Rather than deploying one massive model, Trustpilot built a suite of highly specialized models using the lightweight google/gemma-2-9b as a base.
To get heavy-weight performance from a small footprint, the company employed a consensus annotation over a stratified sample of the Trustpilot review corpus, using a selection of teacher models from the Gemini 2.0/2.5 Pro/Flash family. This process generated high quality training datasets for specialized tasks like topic classification, NER, and sentiment extraction.
The datasets were subsequently used to fine-tune a targeted lineup of custom models that considerably outperformed the legacy solution and delivered accuracy just a couple percentage points lower than the teacher models’ consensus.
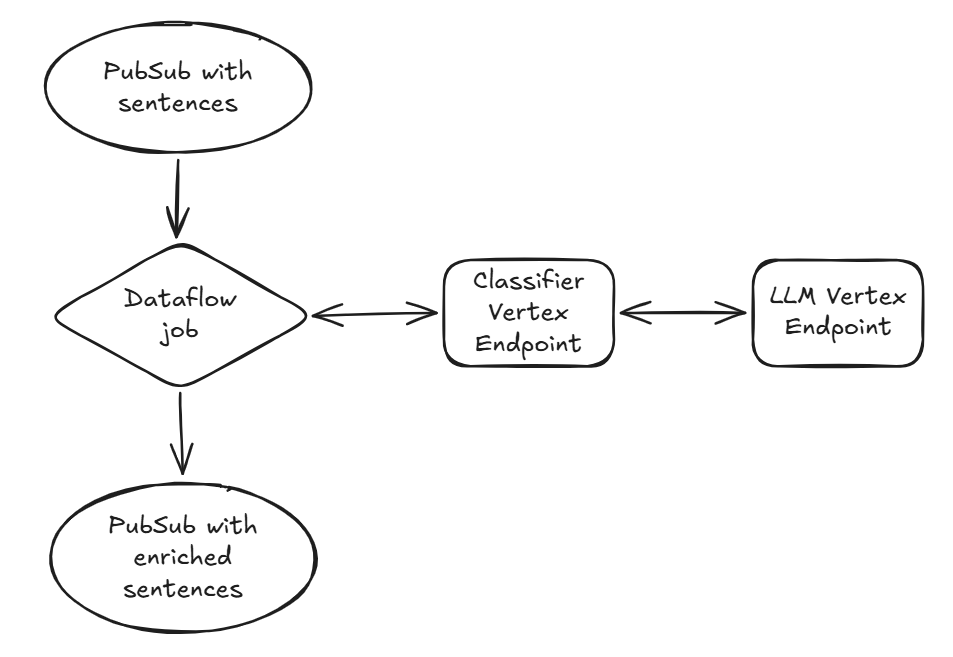
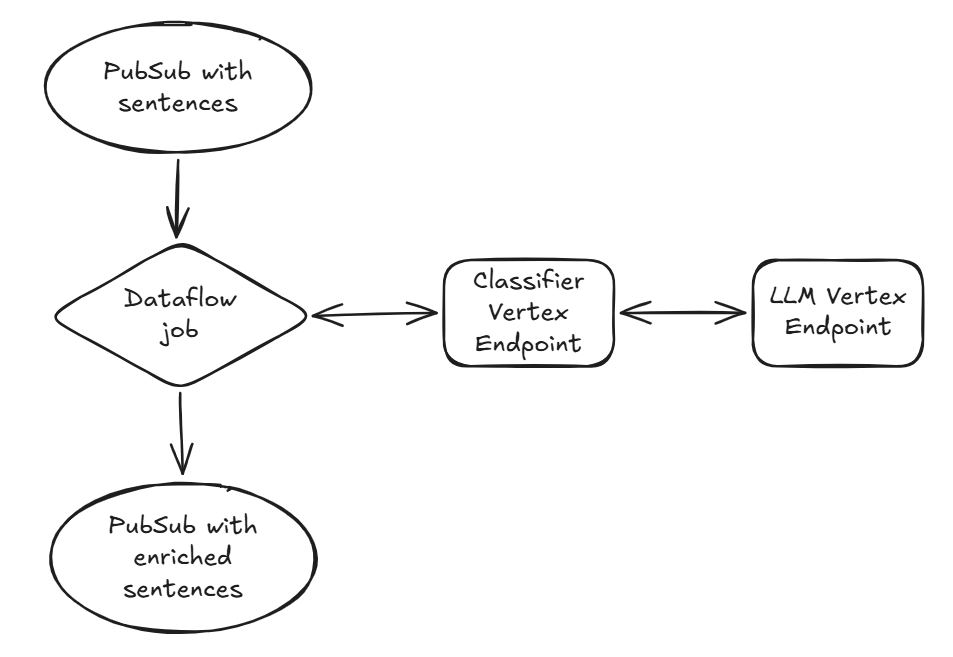
System architecture
This architecture was built on top of Dataflow and Gemini Enterprise Agent Platform Endpoints, which play together very nicely because of the out-of-the-box VertexAIModelHandlerJSON.
We decoupled business logic and raw LLM inference by creating two separate endpoints:
The classifier: a FastAPI-based endpoint that handles the messy stuff, pre/post-processing, prompt templating, and chaining.
The LLM: A separate Agent Platform endpoint dedicated strictly to serving the Gemma model via vLLM.
This approach keeps the Dataflow job clean and ensures the LLM endpoint sticks to what it does best: generating text. Plus, it allows Trustpoint to scale them independently based on the traffic.
Performance tuning
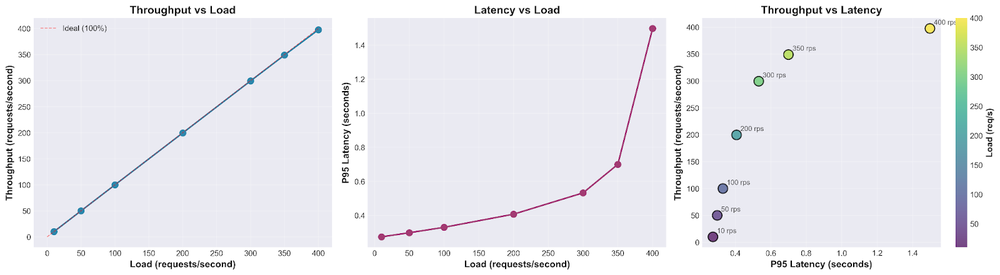
To get the most out of the vLLM-based Agent Platform endpoints, Trustpilot focused on squeezing every bit of performance out of the entire pipeline, especially from the A2 VMs using A100 GPUs. It also leveraged the customized and optimized version of vLLM maintained by Gemini Enterprise Agent Platform.
A focus of our performance tuning involved optimizing the vLLM backend configuration to prevent processing bottlenecks. By carefully adjusting the engine parameters, selecting the appropriate data type, and enabling useful settings such as prefix caching, we ensured the models could smoothly handle high streaming volumes.
Together, we also created a reusable load testing framework to find the optimal serving capacity for a vLLM inference server and to sketch its performance profile. This enabled setting a baseline for needed infrastructure, and tuning the auto-scaling setup using the request count-based metric. In addition, a new metric using vLLM number of requests waiting could be even better for this.
Challenges
While building this setup, Trustpilot encountered a few notable hurdles:
Private networking: The architecture aimed to be fully isolated by using private endpoints and Private Service Connect, but this wasn’t possible because there was no native support for direct private communication between distinct endpoints.
Deployment observability and reliability: Endpoint deployments can be slow or opaque, which occasionally requires extra troubleshooting when entering an unhealthy state. Trustpilot is still working closely with the Gemini Enterprise Agent Platform product team to help shape future observability features and platforms.
GPU Scarcity: Securing A100 GPUs in the EU region is tough, so on-demand VMs are often a no-go. Instead, leveraging reservations is preferable but balancing them between development, production, training, inference, and experiments can be quite challenging.
The results
Together with Google Cloud, Trustpilot leveraged the full potential of Gemma on Gemini Enterprise Agent Platform to process millions of reviews a day in near real-time. In doing so, they achieved Gemini-like performance for a fraction of the cost. This ultimately allowed the Trustpilot Business Platform to turn millions of everyday customer reviews into instant, actionable insights. You can read more on the Trustpilot Medium blog post.
This blog post was written by Assulan Nurkas (Trustpilot), Subu Ramasubramanian (Trustpilot), Konrad Stanek (Trustpilot), Dario Banfi (Google) and Michael Cohen Hjertén (Google) based on the work done during the joint project at the end of 2025.