Amp is a new live radio app from Amazon. With Amp, you can host your own radio show and play songs from the Amazon Music catalog, or tune in and listen to shows other Amp users are hosting. In an environment where content is plentiful and diverse, it’s important to tailor the user experience to each user’s individual taste, so they can easily find shows they like and discover new content they would enjoy.
Amp uses machine learning (ML) to provide personalized recommendations for live and upcoming Amp shows on the app’s home page. The recommendations are computed using a Random Forest model using features representing the popularity of a show (such as listen and like count), popularity of a creator (such as total number of times the recent shows were played), and personal affinities of a user to a show’s topic and creator. Affinities are computed either implicitly from the user’s behavioral data or explicitly from topics of interest (such as pop music, baseball, or politics) as provided in their user profiles.
This is Part 2 of a series on using data analytics and ML for Amp and creating a personalized show recommendation list platform. The platform has shown a 3% boost to customer engagement metrics tracked (liking a show, following a creator, enabling upcoming show notifications) since its launch in May 2022.
Refer to Part 1 to learn how behavioral data was collected and processed using the data and analytics systems.
Solution overview
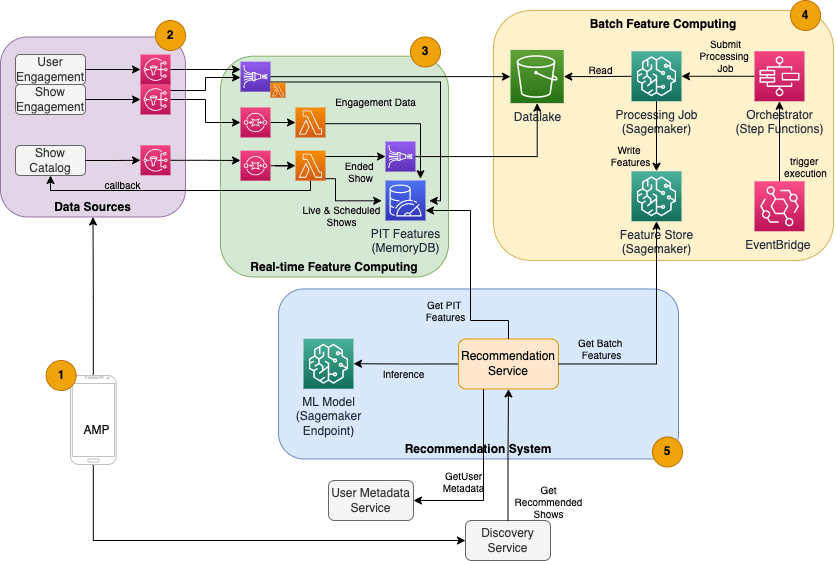
The ML-based show recommender for Amp has five main components, as illustrated in the following architecture diagram:
- The Amp mobile app.
- Back-end services that gather the behavioral data, such as likes and follows, as well as broadcast show-related information such as status updates when shows go live.
- Real-time ingestion of behavioral and show data, and real-time (online) feature computing and storage.
- Batch (offline) feature computing and storage.
- A Recommender System that handles incoming requests from the app backend for getting a list of shows. This includes real-time inference to rank shows based on personalized and non-personalized features.
This post focuses on parts 3, 4, and 5 in an effort to detail the following:
- Real-time data ingestion and transformations using Amazon Kinesis Data Firehose and AWS Lambda.
- Batch data processing via Amazon SageMaker Processing
- Amazon MemoryDB for Redis and Amazon SageMaker Feature Store for storing and serving real-time and batch computed features, respectively
- Real-time ranking via SageMaker inference
The following diagram shows the high-level architecture and its components.

In the following sections, we provide more details regarding real-time feature computing, batch feature computing, real-time inference, operational health, and the outcomes we observed.
Real-time feature computing
Some features, such as like and listen count for a show, need to be streamed in continuously and used as is, whereas others, such as the number of listening sessions longer than 5 minutes, need to also be transformed in real time as raw data for sessions is streamed. These types of features where values need to be computed at inference time are referred as point-in-time (PIT) features. Data for PIT features need to be updated quickly, and the latest version should be written and read with low latency (under 20 milliseconds per user for 1,000 shows). The data also needs to be in a durable storage because missing or partial data may cause deteriorated recommendations and poor customer experience. In addition to the read/write latency, PIT features also require low reflection time. Reflection time is the time it takes for a feature to be available to read after the contributing events were emitted, for example, the time between a listener liking a show and the PIT LikeCount feature being updated.
Sources of the data are the backend services directly serving the app. Some of the data are transformed into metrics that are then broadcasted via Amazon Simple Notification Service (Amazon SNS) to downstream listeners such as the ML feature transformation pipeline. An in-memory database such as MemoryDB is an ideal service for durable storage and ultra-fast performance at high volumes. The compute component that transforms and writes features to MemoryDB is Lambda. App traffic follows daily and weekly patterns of peaks and dips depending on the time and day. Lambda allows for automatic scaling to incoming volume of events. The independent nature of each individual metric transformation also makes Lambda, which is a stateless service on its own, a good fit for this problem. Putting Amazon Simple Queue Service (Amazon SQS) between Amazon SNS and Lambda not only prevents message loss but also acts as a buffer for unexpected bursts of traffic that preconfigured Lambda concurrency limits may not be sufficient to serve.
Batch feature computing
Features that use historical behavioral data to represent a user’s ever-evolving taste are more complex to compute and can’t be computed in real time. These features are computed by a batch process that runs every so often, for example once daily. Data for batch features should support fast querying for filtering and aggregation of data, and may span long periods of time, so will be larger in volume. Because batch features are also retrieved and sent as inputs for real-time inference, they should still be read with low latency.
Collecting raw data for batch feature computing doesn’t have the sub-minute reflection time requirement PIT features have, which makes it feasible to buffer the events longer and transform metrics in batch. This solution utilized Kinesis Data Firehose, a managed service to quickly ingest streaming data into several destinations, including Amazon Simple Storage Service (Amazon S3) for persisting metrics to the S3 data lake to be utilized in offline computations. Kinesis Data Firehose provides an event buffer and Lambda integration to easily collect, batch transform, and persist these metrics to Amazon S3 to be utilized later by the batch feature computing. Batch feature computations don’t have the same low latency read/write requirements as PIT features, which makes Amazon S3 the better choice because it provides low-cost, durable storage for storing these large volumes of business metrics.
Our initial ML model uses 21 batch features computed daily using data captured in the past 2 months. This data includes both playback and app engagement history per user, and grows with the number of users and frequency of app usage. Feature engineering at this scale requires an automated process to pull the required input data, process it in parallel, and export the outcome to persistent storage. The processing infrastructure is needed only for the duration of the computations. SageMaker Processing provides prebuilt Docker images that include Apache Spark and other dependencies needed to run distributed data processing jobs at large scale. The underlying infrastructure for a Processing job is fully managed by SageMaker. Cluster resources are provisioned for the duration of your job, and cleaned up when a job is complete.
Each step in the batch process—data gathering, feature engineering, feature persistence—is part of a workflow that requires error handling, retries, and state transitions in between. With AWS Step Functions, you can create a state machine and split your workflow into several steps of preprocessing and postprocessing, as well as a step to persist the features into SageMaker Feature Store or the other data to Amazon S3. A state machine in Step Functions can be triggered via Amazon EventBridge to automate batch computing to run at a set schedule, such as once every day at 10:00 PM UTC.
After the features are computed, they need to be versioned and stored to be read during inference as well as model retraining. Rather than build your own feature storage and management service, you can use SageMaker Feature Store. Feature Store is a fully managed, purpose-built repository to store, share, and manage features for ML models. It stores history of ML features in the offline store (Amazon S3) and also provides APIs to an online store to allow low-latency reads of most recent features. The offline store can serve the historical data for further model training and experimentation, and the online store can be called by your customer-facing APIs to get features for real-time inference. As we evolve our services to provide more personalized content, we anticipate training additional ML models and with the help of Feature Store, search, discover and reuse features amongst these models.
Real-time inference
Real-time inference usually requires hosting ML models behind endpoints. You could do this using web servers or containers, but this requires ML engineering effort and infrastructure to manage and maintain. SageMaker makes it easy to deploy ML models to real-time endpoints. SageMaker lets you train and upload ML models and host them by creating and configuring SageMaker endpoints. Real-time inference satisfies the low-latency requirements for ranking shows as they are browsed on the Amp home page.
In addition to managed hosting, SageMaker provides managed endpoint scaling. SageMaker inference allows you to define an auto scaling policy with minimum and maximum instance counts and a target utilization to trigger the scaling. This way, you can easily scale in or out as demand changes.
Operational health
The number of events this system handles for real-time feature computing changes accordingly with the natural pattern of app usage (higher or lower traffic based on time of day or day of the week). Similarly, the number of requests it receives for real-time inference scales with the number of concurrent app users. These services also get unexpected peaks in traffic due to self promotions in social media by popular creators. Although it’s important to ensure the system can scale up and down to serve the incoming traffic successfully and frugally, it’s also important to monitor operational metrics and alert for any unexpected operational issues to prevent loss of data and service to customers. Monitoring the health of these services is straightforward using Amazon CloudWatch. Vital service health metrics such as faults and latency of operations as well as utilization metrics such as memory, disk, and CPU usage are available out of the box using CloudWatch. Our development team uses metrics dashboards and automated monitoring to ensure we can serve our clients with high availability (99.8%) and low latency (less than 200 milliseconds end-to end to get recommended shows per user).
Measuring the outcome
Prior to the ML-based show recommender described in this post, a simpler heuristic algorithm ranked Amp shows based on a user’s personal topics of interest that are self-reported on their profile. We set up an A/B test to measure the impact of switching to ML-based recommenders with a user’s data from their past app interactions. We identified improvements in metrics such as listening duration and number of engagement actions (liking a show, following a show creator, turning on notifications) as indicators of success. A/B testing with 50% of users receiving show recommendations ranked for them via the ML-based recommender has shown a 3% boost to customer engagement metrics and a 0.5% improvement to playback duration.
Conclusion
With purpose-built services, the Amp team was able to release the personalized show recommendation API as described in this post to production in under 3 months. The system also scales well for the unpredictable loads created by well-known show hosts or marketing campaigns that could generate an influx of users. The solution uses managed services for processing, training, and hosting, which helps reduce the time spent on day-to-day maintenance of the system. We’re also able to to monitor all these managed services via CloudWatch to ensure the continued health of the systems in production.
A/B testing the first version of the Amp’s ML-based recommender against a rule-based approach (which sorts shows by customer’s topics of interest only) has shown that the ML-based recommender exposes customers to higher-quality content from more diverse topics, which results in a higher number of follows and enabled notifications. The Amp team is continuously working towards improving the models to provide highly relevant recommendations.
For more information about Feature Store, visit Amazon SageMaker Feature Store and check out other customer use cases in the AWS Machine Learning Blog.
About the authors
 Tulip Gupta is a Solutions Architect at Amazon Web Services. She works with Amazon to design, build, and deploy technology solutions on AWS. She assists customers in adopting best practices while deploying solution in AWS, and is a Analytics and ML enthusiast. In her spare time, she enjoys swimming, hiking and playing board games.
Tulip Gupta is a Solutions Architect at Amazon Web Services. She works with Amazon to design, build, and deploy technology solutions on AWS. She assists customers in adopting best practices while deploying solution in AWS, and is a Analytics and ML enthusiast. In her spare time, she enjoys swimming, hiking and playing board games.
 David Kuo is a Solutions Architect at Amazon Web Services. He works with AWS customers to design, build and deploy technology solutions on AWS. He works with Media and Entertainment customers and has interests in machine learning technologies. In his spare time, he wonders what he should do with his spare time.
David Kuo is a Solutions Architect at Amazon Web Services. He works with AWS customers to design, build and deploy technology solutions on AWS. He works with Media and Entertainment customers and has interests in machine learning technologies. In his spare time, he wonders what he should do with his spare time.
 Manolya McCormick is a Sr Software Development Engineer for Amp on Amazon. She designs and builds distributed systems using AWS to serve customer facing applications. She enjoys reading and cooking new recipes at her spare time.
Manolya McCormick is a Sr Software Development Engineer for Amp on Amazon. She designs and builds distributed systems using AWS to serve customer facing applications. She enjoys reading and cooking new recipes at her spare time.
 Jeff Christophersen is a Sr. Data Engineer for Amp on Amazon. He works to design, build, and deploy Big Data solutions on AWS that drive actionable insights. He assists internal teams in adopting scalable and automated solutions, and is a Analytics and Big Data enthusiast. In his spare time, when he is not on a pair of skis you can find him on his mountain bike.
Jeff Christophersen is a Sr. Data Engineer for Amp on Amazon. He works to design, build, and deploy Big Data solutions on AWS that drive actionable insights. He assists internal teams in adopting scalable and automated solutions, and is a Analytics and Big Data enthusiast. In his spare time, when he is not on a pair of skis you can find him on his mountain bike.