Recently, differential privacy (DP) has emerged as a mathematically robust notion of user privacy for data aggregation and machine learning (ML), with practical deployments including the 2022 US Census and in industry. Over the last few years, we have open-sourced libraries for privacy-preserving analytics and ML and have been constantly enhancing their capabilities. Meanwhile, new algorithms have been developed by the research community for several analytic tasks involving private aggregation of data.
One such important data aggregation method is the heatmap. Heatmaps are popular for visualizing aggregated data in two or more dimensions. They are widely used in many fields including computer vision, image processing, spatial data analysis, bioinformatics, and more. Protecting the privacy of user data is critical for many applications of heatmaps. For example, heatmaps for gene microdata are based on private data from individuals. Similarly, a heatmap of popular locations in a geographic area are based on user location check-ins that need to be kept private.
Motivated by such applications, in “Differentially Private Heatmaps” (presented at AAAI 2023), we describe an efficient DP algorithm for computing heatmaps with provable guarantees and evaluate it empirically. At the core of our DP algorithm for heatmaps is a solution to the basic problem of how to privately aggregate sparse input vectors (i.e., input vectors with a small number of non-zero coordinates) with a small error as measured by the Earth Mover’s Distance (EMD). Using a hierarchical partitioning procedure, our algorithm views each input vector, as well as the output heatmap, as a probability distribution over a number of items equal to the dimension of the data. For the problem of sparse aggregation under EMD, we give an efficient algorithm with error asymptotically close to the best possible.
Algorithm description
Our algorithm works by privatizing the aggregated distribution (obtained by averaging over all user inputs), which is sufficient for computing a final heatmap that is private due to the post-processing property of DP. This property ensures that any transformation of the output of a DP algorithm remains differentially private. Our main contribution is a new privatization algorithm for the aggregated distribution, which we will describe next.
The EMD measure, which is a distance-like measure of dissimilarity between two probability distributions originally proposed for computer vision tasks, is well-suited for heatmaps since it takes the underlying metric space into account and considers “neighboring” bins. EMD is used in a variety of applications including deep learning, spatial analysis, human mobility, image retrieval, face recognition, visual tracking, shape matching, and more.
To achieve DP, we need to add noise to the aggregated distribution. We would also like to preserve statistics at different scales of the grid to minimize the EMD error. So, we create a hierarchical partitioning of the grid, add noise at each level, and then recombine into the final DP aggregated distribution. In particular, the algorithm has the following steps:
- Quadtree construction: Our hierarchical partitioning procedure first divides the grid into four cells, then divides each cell into four subcells; it recursively continues this process until each cell is a single pixel. This procedure creates a quadtree over the subcells where the root represents the entire grid and each leaf represents a pixel. The algorithm then calculates the total probability mass for each tree node (obtained by adding up the aggregated distribution’s probabilities of all leaves in the subtree rooted at this node). This step is illustrated below.

In the first step, we take the (non-private) aggregated distribution (top left) and repeatedly divide it to create a quadtree. Then, we compute the total probability mass is each cell (bottom). - Noise addition: To each tree node’s mass we then add Laplace noise calibrated to the use case.
- Truncation: To help reduce the final amount of noise in our DP aggregated distribution, the algorithm traverses the tree starting from the root and, at each level, it discards all but the top w nodes with highest (noisy) masses together with their descendants.
- Reconstruction: Finally, the algorithm solves a linear program to recover the aggregated distribution. This linear program is inspired by the sparse recovery literature where the noisy masses are viewed as (noisy) measurements of the data.

 |
| In step 2, noise is added to each cell’s probability mass. Then in step 3, only top-w cells are kept (green) whereas the remaining cells are truncated (red). Finally, in the last step, we write a linear program on these top cells to reconstruct the aggregation distribution, which is now differentially private. |
Experimental results
We evaluate the performance of our algorithm in two different domains: real-world location check-in data and image saliency data. We consider as a baseline the ubiquitous Laplace mechanism, where we add Laplace noise to each cell, zero out any negative cells, and produce the heatmap from this noisy aggregate. We also consider a “thresholding” variant of this baseline that is more suited to sparse data: only keep top t% of the cell values (based on the probability mass in each cell) after noising while zeroing out the rest. To evaluate the quality of an output heatmap compared to the true heatmap, we use Pearson coefficient, KL-divergence, and EMD. Note that when the heatmaps are more similar, the first metric increases but the latter two decrease.
The locations dataset is obtained by combining two datasets, Gowalla and Brightkite, both of which contain check-ins by users of location-based social networks. We pre-processed this dataset to consider only check-ins in the continental US resulting in a final dataset consisting of ~500,000 check-ins by ~20,000 users. Considering the top cells (from an initial partitioning of the entire space into a 300 x 300 grid) that have check-ins from at least 200 unique users, we partition each such cell into subgrids with a resolution of ∆ × ∆ and assign each check-in to one of these subgrids.
In the first set of experiments, we fix ∆ = 256. We test the performance of our algorithm for different values of ε (the privacy parameter, where smaller ε means stronger DP guarantees), ranging from 0.1 to 10, by running our algorithms together with the baseline and its variants on all cells, randomly sampling a set of 200 users in each trial, and then computing the distance metrics between the true heatmap and the DP heatmap. The average of these metrics is presented below. Our algorithm (the red line) performs better than all versions of the baseline across all metrics, with improvements that are especially significant when ε is not too large or small (i.e., 0.2 ≤ ε ≤ 5).
 |
| Metrics averaged over 60 runs when varying ε for the location dataset. Shaded areas indicate 95% confidence interval. |
Next, we study the effect of varying the number n of users. By fixing a single cell (with > 500 users) and ε, we vary n from 50 to 500 users. As predicted by theory, our algorithms and the baseline perform better as n increases. However, the behavior of the thresholding variants of the baseline are less predictable.
We also run another experiment where we fix a single cell and ε, and vary the resolution ∆ from 64 to 256. In agreement with theory, our algorithm’s performance remains nearly constant for the entire range of ∆. However, the baseline suffers across all metrics as ∆ increases while the thresholding variants occasionally improve as ∆ increases.
 |
| Effect of the number of users and grid resolution on EMD. |
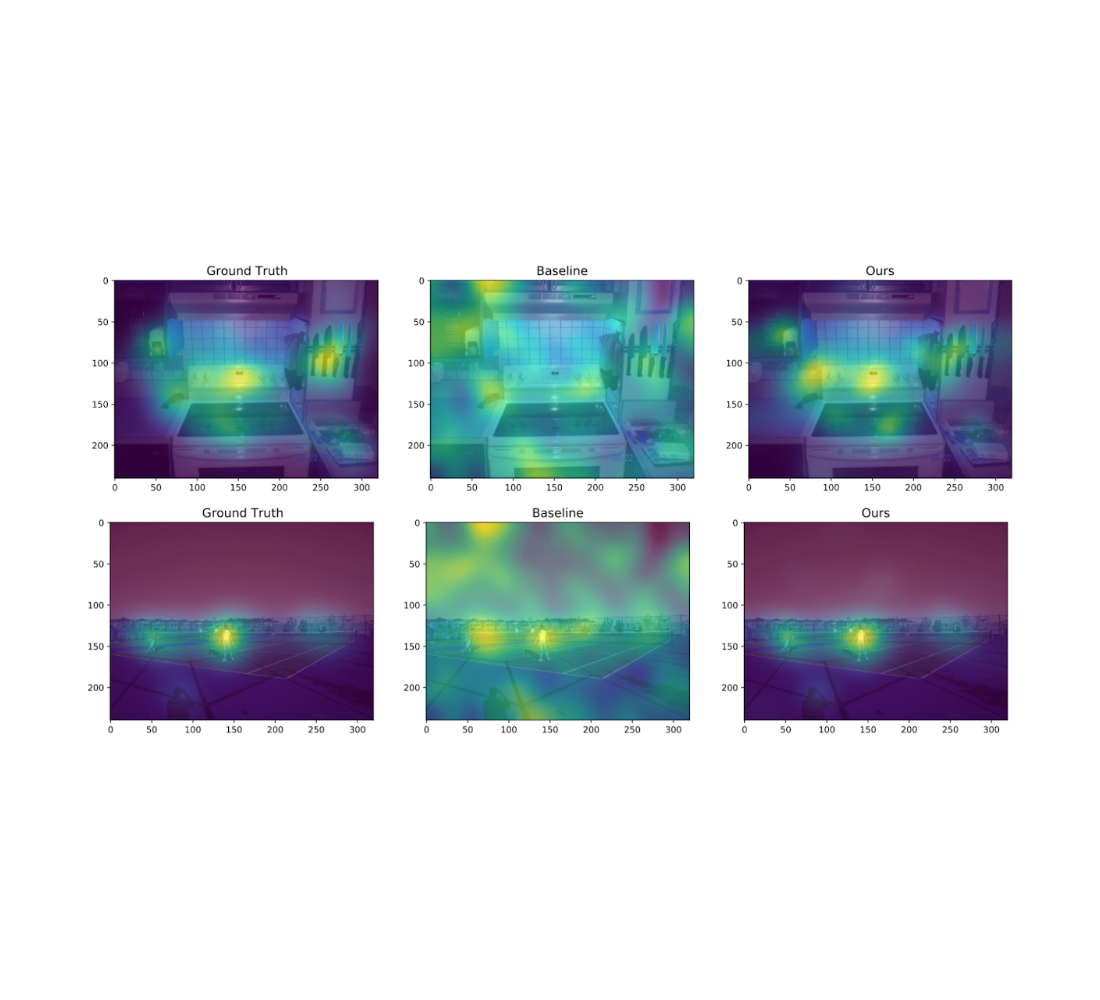
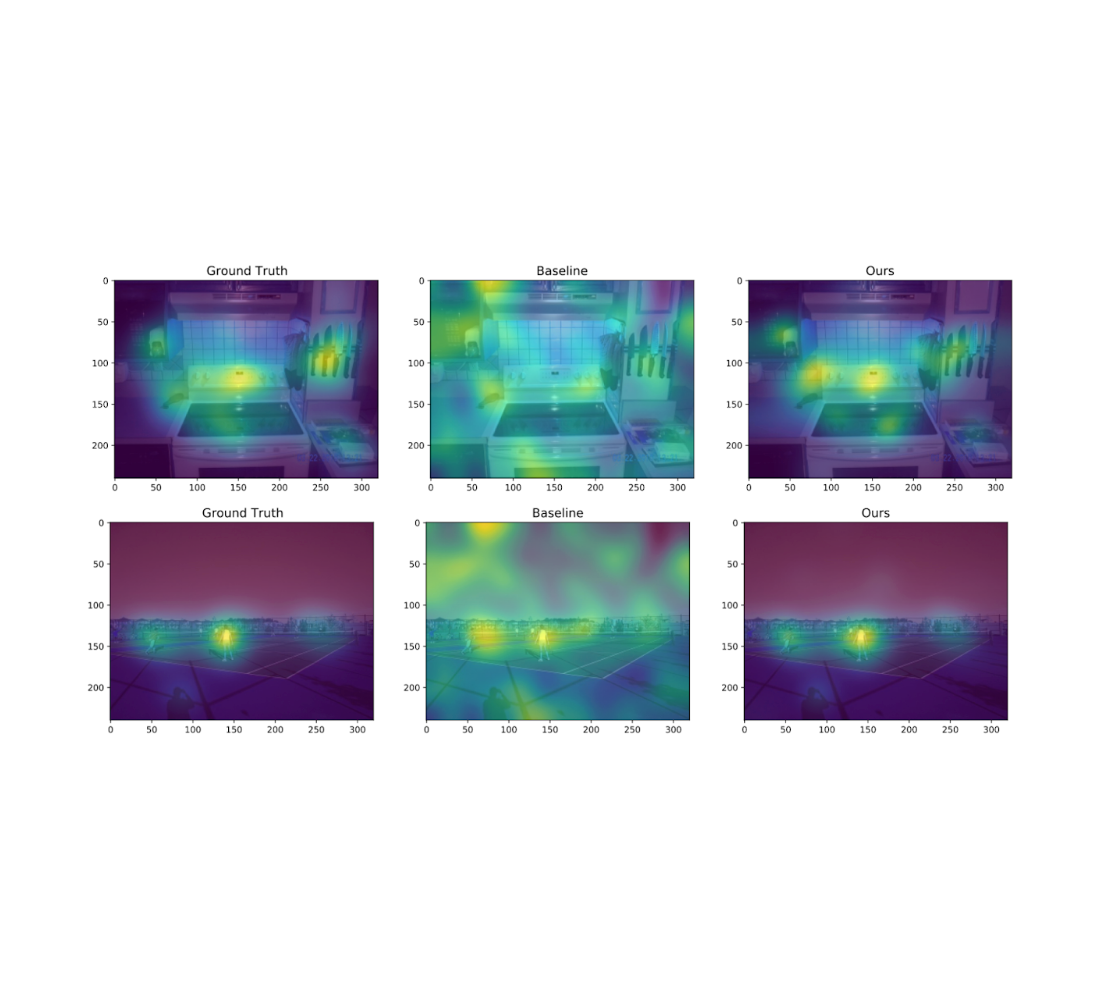
We also experiment on the Salicon image saliency dataset (SALICON). This dataset is a collection of saliency annotations on the Microsoft Common Objects in Context image database. We downsized the images to a fixed resolution of 320 × 240 and each [user, image] pair consists of a sequence of coordinates in the image where the user looked. We repeat the experiments described previously on 38 randomly sampled images (with ≥ 50 users each) from SALICON. As we can see from the examples below, the heatmap obtained by our algorithm is very close to the ground truth.
 |
| Example visualization of different algorithms for two different natural images from SALICON for ε = 10 and n = 50 users. The algorithms from left to right are: original heatmap (no privacy), baseline, and ours. |
Additional experimental results, including those on other datasets, metrics, privacy parameters and DP models, can be found in the paper.
Conclusion
We presented a privatization algorithm for sparse distribution aggregation under the EMD metric, which in turn yields an algorithm for producing privacy-preserving heatmaps. Our algorithm extends naturally to distributed models that can implement the Laplace mechanism, including the secure aggregation model and the shuffle model. This does not apply to the more stringent local DP model, and it remains an interesting open question to devise practical local DP heatmap/EMD aggregation algorithms for “moderate” number of users and privacy parameters.
Acknowledgments
This work was done jointly with Junfeng He, Kai Kohlhoff, Ravi Kumar, Pasin Manurangsi, and Vidhya Navalpakkam.