

In recent years, advances in computer vision have enabled researchers, first responders, and governments to tackle the challenging problem of processing global satellite imagery to understand our planet and our impact on it. AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. For more information, refer to Preview: Use Amazon SageMaker to Build, Train, and Deploy ML Models Using Geospatial Data.
Many agencies, including first responders, are using these offerings to gain large-scale situational awareness and prioritize relief efforts in geographical areas that have been struck by natural disasters. Often these agencies are dealing with disaster imagery from low altitude and satellite sources, and this data is often unlabeled and difficult to use. State-of-the-art computer vision models often underperform when looking at satellite images of a city that a hurricane or wildfire has hit. Given the lack of these datasets, even state-of-the-art ML models are often unable to deliver the accuracy and precision required to predict standard FEMA disaster classifications.
Geospatial datasets contain useful metadata such as latitude and longitude coordinates, and timestamps, which can provide context for these images. This is especially helpful in improving the accuracy of geospatial ML for disaster scenes, because these images are inherently messy and chaotic. Buildings are less rectangular, vegetation has sustained damage, and linear roads have been interrupted by flooding or mudslides. Because labeling these massive datasets is expensive, manual, and time-consuming, the development of ML models that can automate image labeling and annotation is critical.
To train this model, we need a labeled ground truth subset of the Low Altitude Disaster Imagery (LADI) dataset. This dataset consists of human and machine annotated airborne images collected by the Civil Air Patrol in support of various disaster responses from 2015-2019. These LADI datasets focus on the Atlantic hurricane seasons and coastal states along the Atlantic Ocean and Gulf of Mexico. Two key distinctions are the low altitude, oblique perspective of the imagery and disaster-related features, which are rarely featured in computer vision benchmarks and datasets. The teams used existing FEMA categories for damage such as flooding, debris, fire and smoke, or landslides, which standardized the label categories. The solution is then able to make predictions on the rest of the training data, and route lower-confidence results for human review.
In this post, we describe our design and implementation of the solution, best practices, and the key components of the system architecture.
Solution overview
In brief, the solution involved building three pipelines:
- Data pipeline – Extracts the metadata of the images
- Machine learning pipeline – Classifies and labels images
- Human-in-the-loop review pipeline – Uses a human team to review results
The following diagram illustrates the solution architecture.
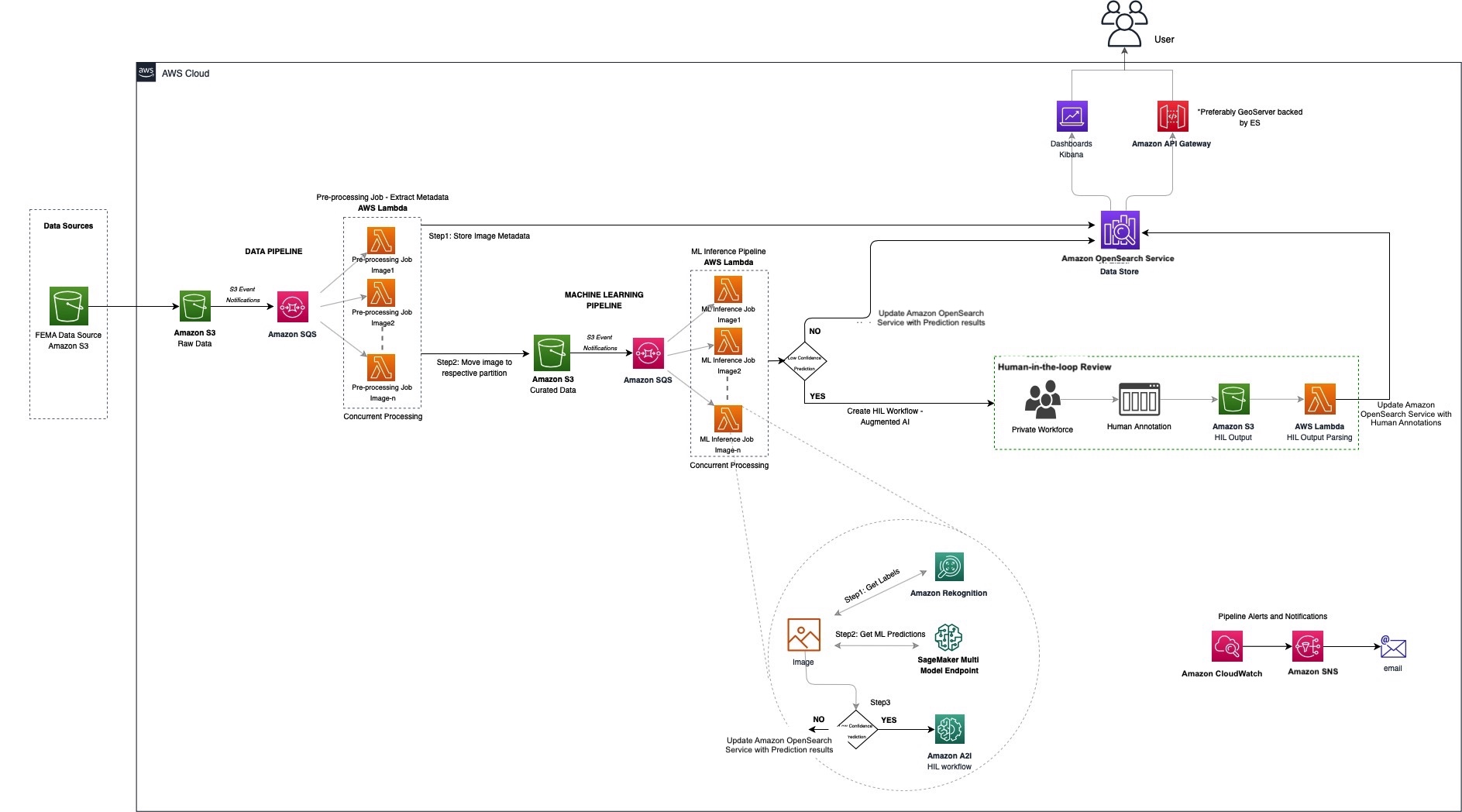
Given the nature of a labeling system like this, we designed a horizontally scalable architecture that would handle ingestion spikes without over-provisioning by using a serverless architecture. We use a one-to-many pattern from Amazon Simple Queue Service (Amazon SQS) to AWS Lambda in multiple spots to support these ingestion spikes, offering resiliency.
Using an SQS queue for processing Amazon Simple Storage Service (Amazon S3) events helps us control the concurrency of downstream processing (Lambda functions, in this case) and handle the incoming spikes of data. Queuing incoming messages also acts as a buffer storage in case of any failures downstream.
Given the highly parallel needs, we chose Lambda to process our images. Lambda is a serverless compute service that lets us run code without provisioning or managing servers, creating workload-aware cluster scaling logic, maintaining event integrations, and managing runtimes.
We use Amazon OpenSearch Service as our central data store to take advantage of its highly scalable, fast searches and integrated visualization tool, OpenSearch Dashboards. It enables us to iteratively add context to the image, without having to recompile or rescale, and handle schema evolution.
Amazon Rekognition makes it easy to add image and video analysis into our applications, using proven, highly scalable, deep learning technology. With Amazon Rekognition, we get a good baseline of detected objects.
In the following sections, we dive into each pipeline in more detail.
Data pipeline
The following diagram shows the workflow of the data pipeline.
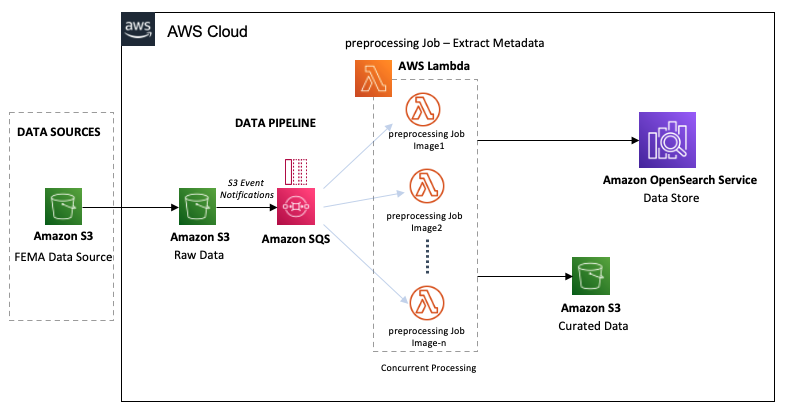
The LADI data pipeline starts with the ingestion of raw data images from the FEMA Common Alerting Protocol (CAP) into an S3 bucket. As we ingest the images into the raw data bucket, they are processed in near-real time in two steps:
- The S3 bucket triggers event notifications for all object creations, creating messages in the SQS queue for each image ingested.
- The SQS queue concurrently invokes the preprocessing Lambda functions on the image.
The Lambda functions perform the following preprocessing steps:
- Compute the UUID for each image, providing a unique identifier for each image. This ID will identify the image for its entire lifecycle.
- Extract metadata such as GPS coordinates, image size, GIS information, and S3 location from the image and persist it into OpenSearch.
- Based on a lookup against FIPS codes, the function moves the image into the curated data S3 bucket. We partition the data by the image’s FIPS-State-code/FIPS-County-code/Year/Month.
Machine learning pipeline
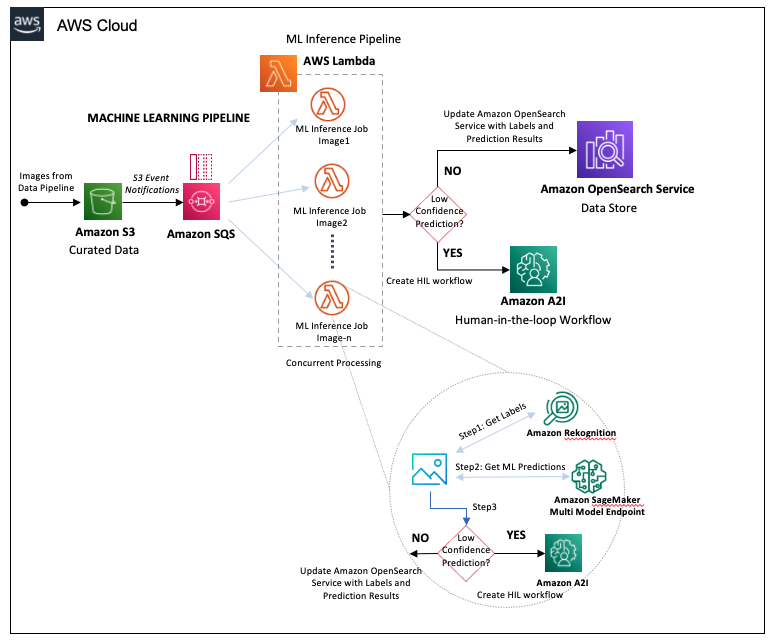
The ML pipeline starts from the images landing in the curated data S3 bucket in the data pipeline step, which triggers the following steps:
- Amazon S3 generates a message into another SQS queue for each object created in the curated data S3 bucket.
- The SQS queue concurrently triggers Lambda functions to run the ML inference job on the image.
The Lambda functions perform the following actions:
- Send each image to Amazon Rekognition for object detection, storing the returned labels and respective confidence scores.
- Compose the Amazon Rekognition output into input parameters for our Amazon SageMaker multi-model endpoint. This endpoint hosts our ensemble of classifiers, which are trained for specific sets of damage labels.
- Pass the results of the SageMaker endpoint to Amazon Augmented AI (Amazon A2I).
The following diagram illustrates the pipeline workflow.
Human-in-the-loop review pipeline
The following diagram illustrates the human-in-the-loop (HIL) pipeline.
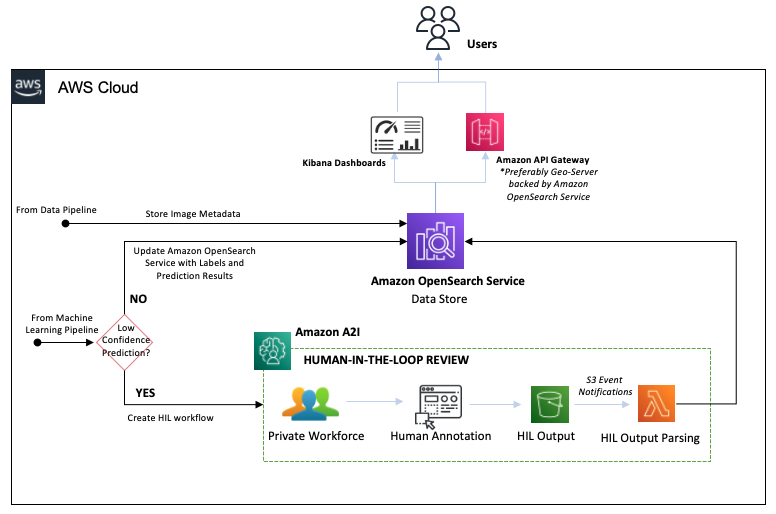
With Amazon A2I, we can configure thresholds that will trigger a human review by a private team when a model yields a low confidence prediction. We can also use Amazon A2I to provide an ongoing audit of our model’s predictions. The workflow steps are as follows:
- Amazon A2I routes high confidence predictions into OpenSearch Service, updating the image’s label data.
- Amazon A2I routes low confidence predictions to the private team to annotate images manually.
- The human reviewer completes the annotation, generating a human annotation output file that is stored in the HIL Output S3 bucket.
- The HIL Output S3 bucket triggers a Lambda function that parses the human annotations output and updates the image’s data in OpenSearch Service.
By routing the human annotation results back to the data store, we can retrain the ensemble models and iteratively improve the model’s accuracy.
With our high-quality results now stored in OpenSearch Service, we’re able to perform geospatial and temporal search via a REST API, using Amazon API Gateway and Geoserver. OpenSearch Dashboard also enables users to search and run analytics with this dataset.
Results
The following code shows an example of our results.

With this new pipeline, we create a human backstop for models that are not yet fully performant. This new ML pipeline has been put into production for use with a Civil Air Patrol Image Filter microservice that allows for filtering of Civil Air Patrol images in Puerto Rico. This enables first responders to view the extent of damage and view images associated with that damage following hurricanes. The AWS Data Lab, AWS Open Data Program, Amazon Disaster Response team, and AWS human-in-the-loop team worked with customers to develop an open-source pipeline that can be used to analyze Civil Air Patrol data stored in the Open Data Program registry on demand following any natural disaster. For more information about the pipeline architecture and an overview of the collaboration and impact, check out the video Focusing on disaster response with Amazon Augmented AI, the AWS Open Data Program and AWS Snowball.
Conclusion
As climate change continues to increase the frequency and intensity of storms and wildfires, we continue to see the importance of using ML to understand the impact of these events on local communities. These new tools can accelerate disaster response efforts and allow us to use the data from these post-event analyses to improve the prediction accuracy of these models with active learning. These new ML models can automate data annotation, which enables us to infer the extent of damage from each of these events as we overlay damage labels with map data. That cumulative data can also help improve our ability to predict damage for future disaster events, which can inform mitigation strategies. This in turn can improve the resilience of communities, economies, and ecosystems by giving decision-makers the information they need to develop data-driven polices to address these emerging environmental threats.
In this blog post we discussed using computer vision on satellite imagery. This solution is meant to be a reference architecture or a quick start guide that you can customize for your own needs.
Give it a whirl and let us know how this solved your use case by leaving feedback in the comments section. For more information, see Amazon SageMaker geospatial capabilities.
About the Authors
 Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening.
Vamshi Krishna Enabothala is a Sr. Applied AI Specialist Architect at AWS. He works with customers from different sectors to accelerate high-impact data, analytics, and machine learning initiatives. He is passionate about recommendation systems, NLP, and computer vision areas in AI and ML. Outside of work, Vamshi is an RC enthusiast, building RC equipment (planes, cars, and drones), and also enjoys gardening.
 Morgan Dutton is a Senior Technical Program Manager with the Amazon Augmented AI and Amazon SageMaker Ground Truth team. She works with enterprise, academic and public sector customers to accelerate adoption of machine learning and human-in-the-loop ML services.
Morgan Dutton is a Senior Technical Program Manager with the Amazon Augmented AI and Amazon SageMaker Ground Truth team. She works with enterprise, academic and public sector customers to accelerate adoption of machine learning and human-in-the-loop ML services.
 Sandeep Verma is a Sr. Prototyping Architect with AWS. He enjoys diving deep into customer challenges and building prototypes for customers to accelerate innovation. He has a background in AI/ML, founder of New Knowledge, and generally passionate about tech. In his free time, he loves traveling and skiing with his family.
Sandeep Verma is a Sr. Prototyping Architect with AWS. He enjoys diving deep into customer challenges and building prototypes for customers to accelerate innovation. He has a background in AI/ML, founder of New Knowledge, and generally passionate about tech. In his free time, he loves traveling and skiing with his family.