The Stability AI team is proud to release as an open model SDXL 1.0, the next iteration in the evolution of text-to-image generation models. Following the limited, research-only release of SDXL 0.9, the full version of SDXL has been improved to be the world’s best open image generation model.
SDXL 1.0 launch, made with forthcoming image control from Stability AI.
The best image model from Stability AI
SDXL 1.0 is the flagship image model from Stability AI and the best open model for image generation. We’ve tested it against various other models, and the results are conclusive – people prefer images generated by SDXL 1.0 over other open models. This research results from weeks of preference data captured from generations of experimental models on our Discord and from external testing.
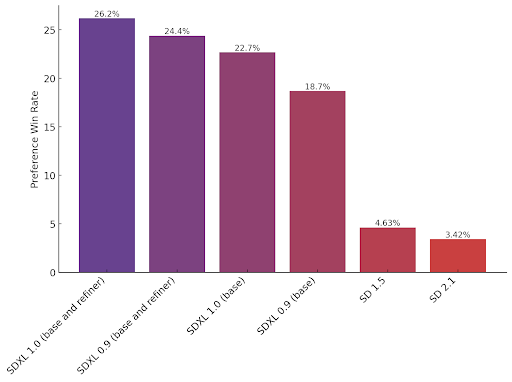
Better artwork for challenging concepts and styles
SDXL generates images of high quality in virtually any art style and is the best open model for photorealism. Distinct images can be prompted without having any particular ‘feel’ imparted by the model, ensuring absolute freedom of style. SDXL 1.0 is particularly well-tuned for vibrant and accurate colors, with better contrast, lighting, and shadows than its predecessor, all in native 1024×1024 resolution.
In addition, SDXL can generate concepts that are notoriously difficult for image models to render, such as hands and text or spatially arranged compositions (e.g., a woman in the background chasing a dog in the foreground).
Better spatial configuration and style control, including photorealism.
More intelligent with simpler language
SDXL requires only a few words to create complex, detailed, and aesthetically pleasing images. Users no longer need to invoke qualifier terms like “masterpiece” to get high-quality images. Furthermore, SDXL can understand the differences between concepts like “The Red Square” (a famous place) vs a “red square” (a shape).
Simple prompts, quality outputs.
The largest open image model
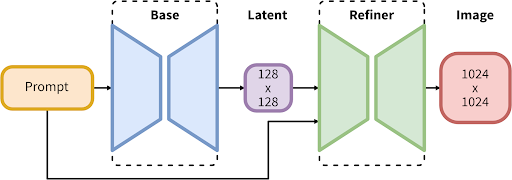
SDXL 1.0 has one of the largest parameter counts of any open access image model, built on an innovative new architecture composed of a 3.5B parameter base model and a 6.6B parameter refiner.
The full model consists of a mixture-of-experts pipeline for latent diffusion: In the first step, the base model generates (noisy) latents, which are then further processed with a refinement model specialized for the final denoising steps. Note that the base model can also be used as a standalone module.
This two-stage architecture allows for robustness in image generation without compromising on speed or requiring excess compute resources. SDXL 1.0 should work effectively on consumer GPUs with 8GB VRAM or readily available cloud instances.
Fine-tuning and advanced control
With SDXL 1.0, fine-tuning the model to custom data is easier than ever. Custom LoRAs or checkpoints can be generated with less need for data wrangling. The Stability AI team is building the next generation of task-specific structure, style, and composition controls, with T2I / ControlNet specialized for SDXL. These features are currently in beta preview but stay tuned for updates on fine-tuning.
Image control on SDXL is forthcoming.
{kind=link}
View fullsize

{kind=link}
View fullsize

{kind=link}
View fullsize

{kind=link}
View fullsize

Get started with SDXL
There are several ways to get started with SDXL 1.0:
SDXL 1.0 is live on Clipdrop. Follow this link.
The weights of SDXL 1.0 and the associated source code have been released on the Stability AI GitHub page.
SDXL 1.0 is also being released for API on the Stability AI Platform.
SDXL 1.0 is available on AWS Sagemaker and AWS Bedrock.
The Stable Foundation Discord is open for live testing of SDXL models.
DreamStudio has SDXL 1.0 available for image generation as well.
Generate high-quality images on a variety of platforms.
License
SDXL 1.0 is released under the CreativeML OpenRAIL++-M License. Details on this license can be found here.
Contact
For more information or to provide feedback:
Contact research@stability.ai to connect with the research team and
For press, please contact press@stability.ai.
Join our Discord community to stay up to date and to experiment with our latest models.