Rethinking AI: DeepSeek’s playbook shakes up the high-spend, high-compute paradigm
DeepSeek’s advancements were inevitable, but the company brought them forward a few years earlier than would have been possible otherwise.Read More
DeepSeek’s advancements were inevitable, but the company brought them forward a few years earlier than would have been possible otherwise.Read More
The alleged shooter is a 57-year-old white male; according to his ministry’s website, he “sought out militant Islamists in order to share the gospel and tell them that violence wasn’t the answer.”
Over the past decades, computer scientists have introduced increasingly sophisticated machine learning-based models, which can perform remarkably well on various tasks. These include multimodal large language models (MLLMs), systems that can process and generate different types of data, predominantly texts, images and videos.
submitted by /u/SysPsych [link] [comments]
We partnered with Darren Aronofsky, Eliza McNitt and a team of more than 200 people to make a film using Veo and live-action filmmaking.
We’re excited to announce that Amazon Bedrock Custom Model Import now supports Qwen models. You can now import custom weights for Qwen2, Qwen2_VL, and Qwen2_5_VL architectures, including models like Qwen 2, 2.5 Coder, Qwen 2.5 VL, and QwQ 32B. You can bring your own customized Qwen models into Amazon Bedrock and deploy them in a fully managed, serverless environment—without having to …
Read more “Deploy Qwen models with Amazon Bedrock Custom Model Import”
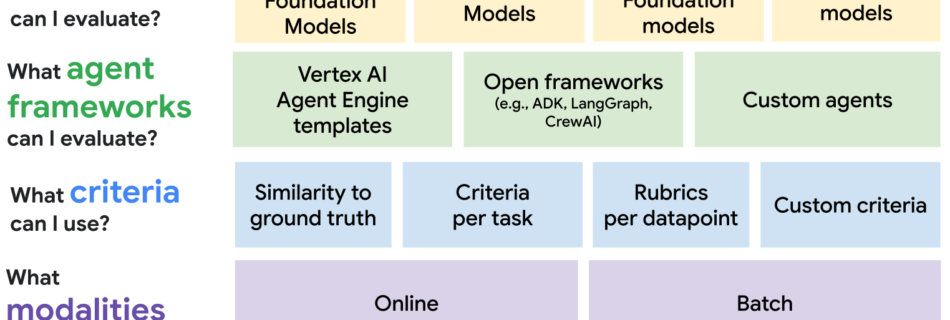
As AI moves from promising experiments to landing core business impact, the most critical question is no longer “What can it do?” but “How well does it do it?”. Ensuring the quality, reliability, and safety of your AI applications is a strategic imperative. To guide you, evaluation must be your North Star—a constant process that …
Read more “How good is your AI? Gen AI evaluation at every stage, explained”
Patients using chatbots to assess their own medical conditions may end up with worse outcomes than conventional methods, according to a new Oxford study.Read More
Your membership gets you more than free two-day shipping. Here’s what you may be missing ahead of Amazon Prime Day 2025.
A new explainable AI technique transparently classifies images without compromising accuracy. The method, developed at the University of Michigan, opens up AI for situations where understanding why a decision was made is just as important as the decision itself, like medical diagnostics.