by Chad Wahlquist, Palantir Forward Deployed Architect
Welcome to another installment of our Building with AIP series, where Palantir engineers and architects take you through how to build end-to-end workflows using our Artificial Intelligence Platform (AIP). In this video, we’re continuing our dive into Ontology Augmented Generation (OAG) — this time, with logic tools.
Refresher on RAG/OAG
For those who haven’t seen our first post on RAG/OAG, OAG is a more expansive, decision-centric version of Retrieval Augmented Generation (RAG).
RAG enables LLMs to leverage (and cite) context-specific outside sources as they generate responses, reducing the risk of hallucinations and promoting trust. OAG takes RAG to the next level by grounding LLMs in the operational reality of a given enterprise via the decision-centric Ontology, which brings together the three constituent elements of decision-making — data, logic, and actions — in a single system. You can read more about the Ontology in this blog post.
Introduction to OAG Logic Tools
In the previous video, we built an application that enabled our fictional medical supplies company, Titan Industries, to prevent shortages for its customers in the wake of a fire at one of its distribution centers. AIP helped us surface customer orders impacted by the fire, identify distribution centers with sufficient inventory to make up for shortages, and update the relevant customer orders accordingly.
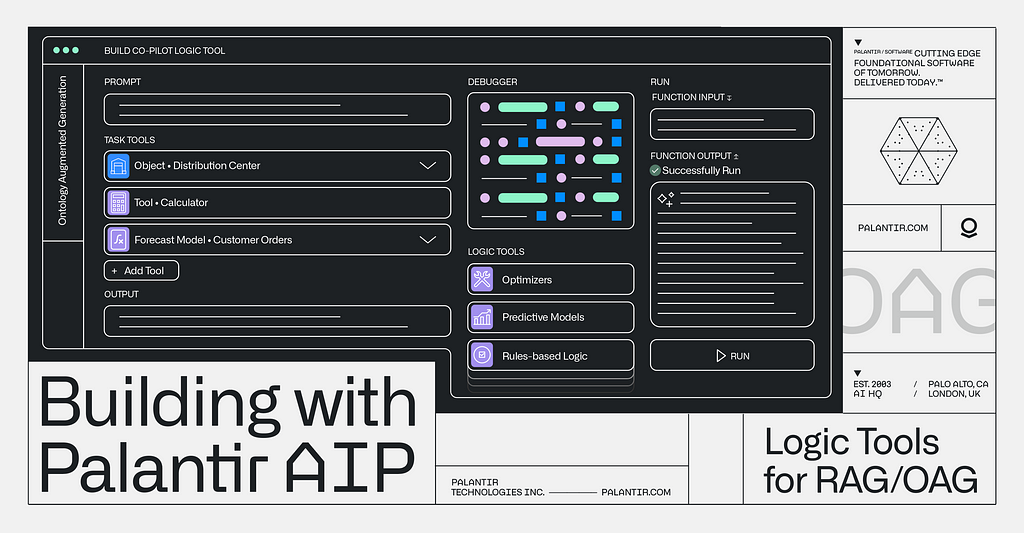
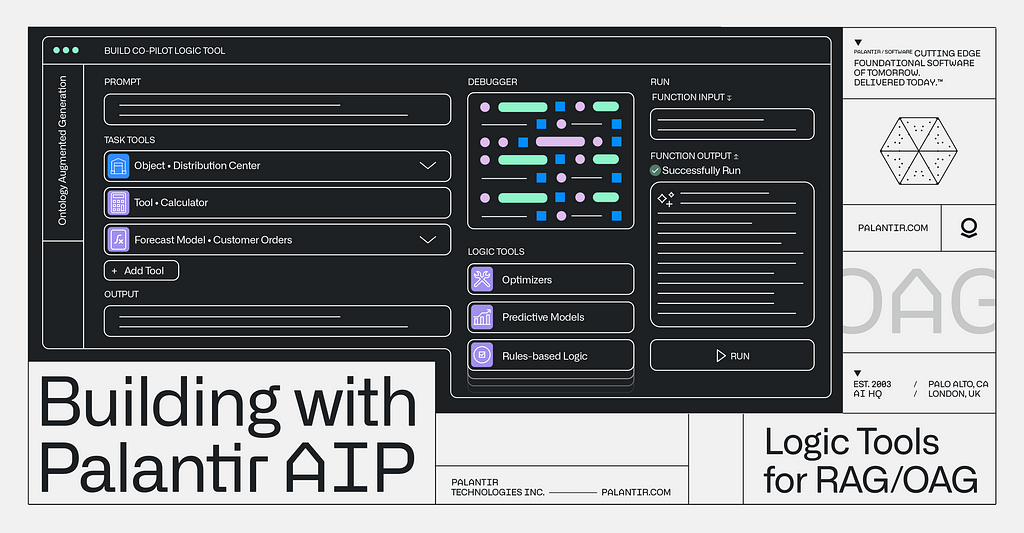
This time, we’ll expand the tools paradigm beyond data, and into logic. We’ll take our application and focus on enabling the LLM to leverage logic tools; in this case, a forecasting model that will help Titan manage its inventory and supply chain by predicting customer orders as it continues to recover from the fire at the distribution center.
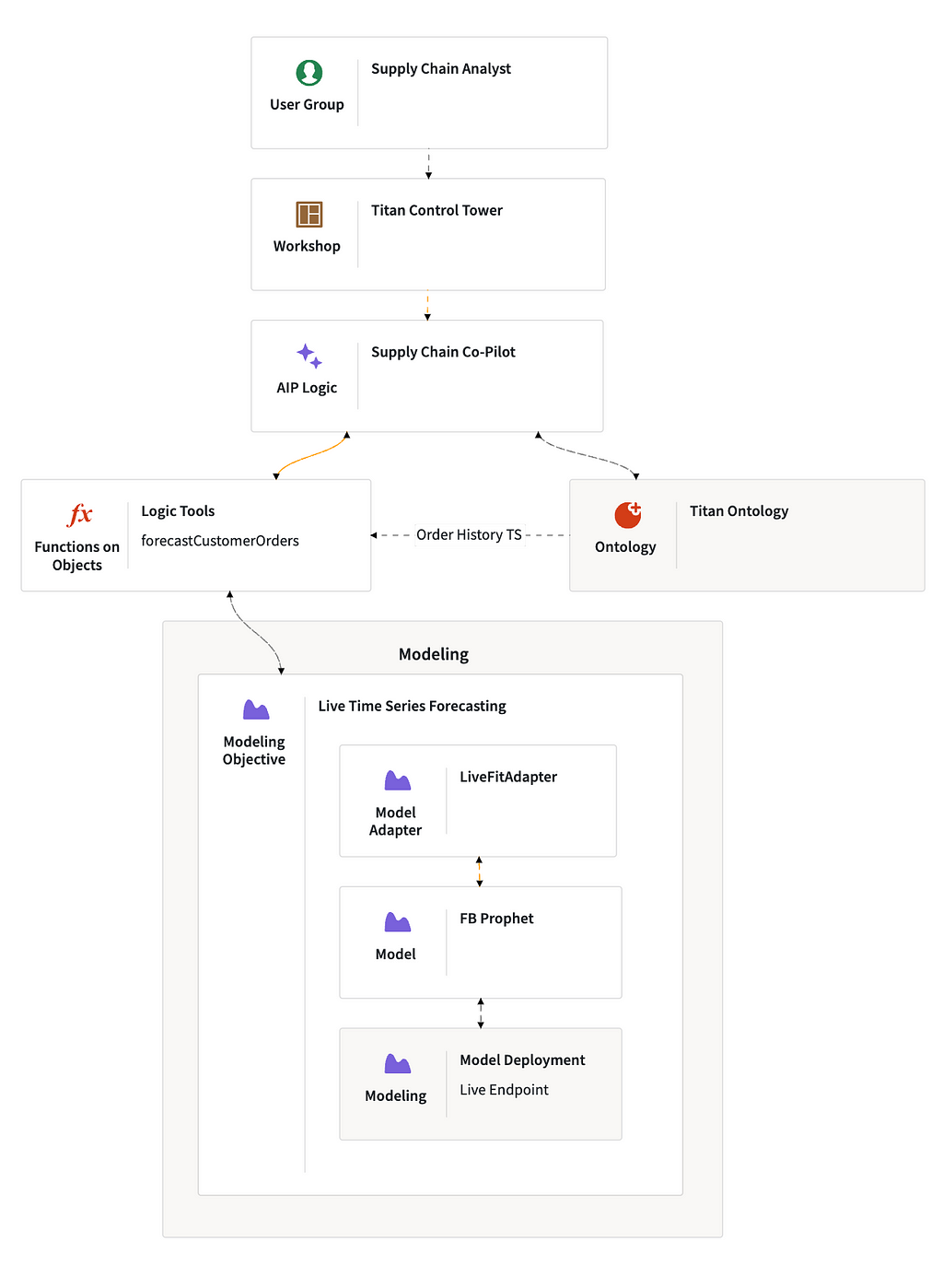
Why is this so powerful?
While LLMs are great at a lot of things — like contextual reasoning — they’re not great at traditional types of computation, like forecasting or linear optimization. By creating logic tools for LLMs to use in AIP, we’re able to combine the power of forecasting models, optimizers, and other types of logic assets across the enterprise with the reasoning capabilities of LLMs and other forms of generative AI. Ultimately, this means enterprises can equip AIP with their logic assets — regardless of where they are developed — and create increasingly powerful applications that leverage these assets, without sacrificing trust.
Let’s build!
Modeling Objectives, Evaluation, and Deployment
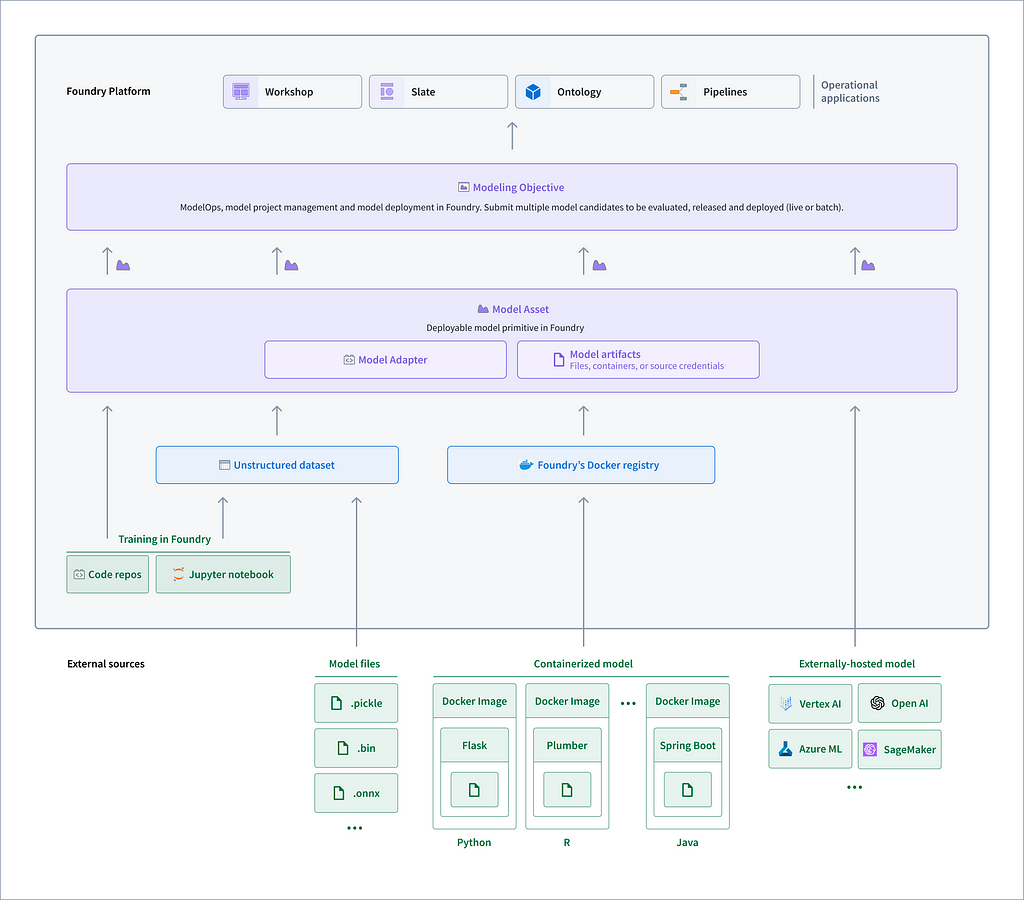
Within the platform, models encapsulate any functional logic, including machine learning, forecasting, optimization, physical models, and business rules. Models can be leveraged to do everything from generating indicators and recommendations to inform decisions to enabling scenario analysis and simulation.
We start by walking through how we integrate, evaluate, and deploy models within AIP. The platform implements the complete ModelOps lifecycle, spanning problem definition, development of one or more candidate solutions, evaluation of these solutions, deployment, monitoring, and iteration.
Modeling Objectives
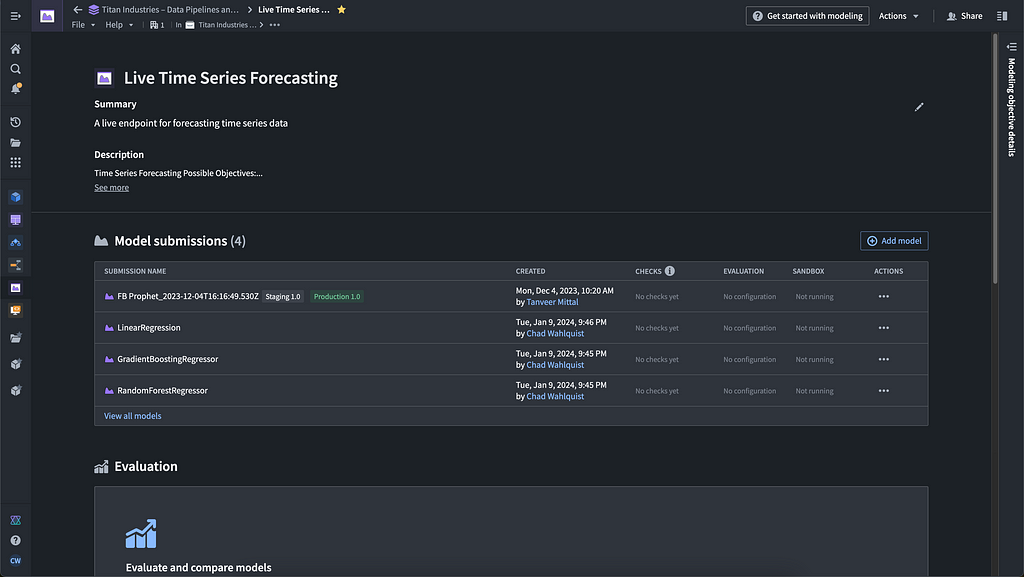
In AIP, we set out with a modeling objective, which we can think of as the model’s end goal, or the problem it is trying to solve. In our application, it is forecasting customer orders for Titan Industries, but for this modeling walkthrough, we’ll look at a model that predicts the probability of a machine breaking down.
Modeling objectives effectively serve as the “mission control” for models in the platform; the communication hub for the modeling ecosystem, and the system of record for evaluating, reviewing, and operationalizing model solutions over time. Beyond a convenient user interface, they provide a governance and permissions layer, an automation layer (e.g., uniform evaluation of model candidates), and a CI/CD layer for models.
A modeling objective has many model assets, which are in turn made up of model artifacts (e.g., the model file, a container, or a pointer to a third-party endpoint) and model adapters, which essentially standardize model outputs so that they can be leveraged by other tools in the platform.
How do we get models into the platform? Models can be developed within the platform or built externally and imported. We can train them on data that’s already in the platform using Code Repositories or Code Workspaces, or we can import models that have been developed elsewhere. AIP also allows for externally hosted models — if a customer has a model endpoint running with another cloud provider or a third party, or has paid to have access to a model endpoint, they can register it as a model artifact in the platform.
Evaluation and Deployment
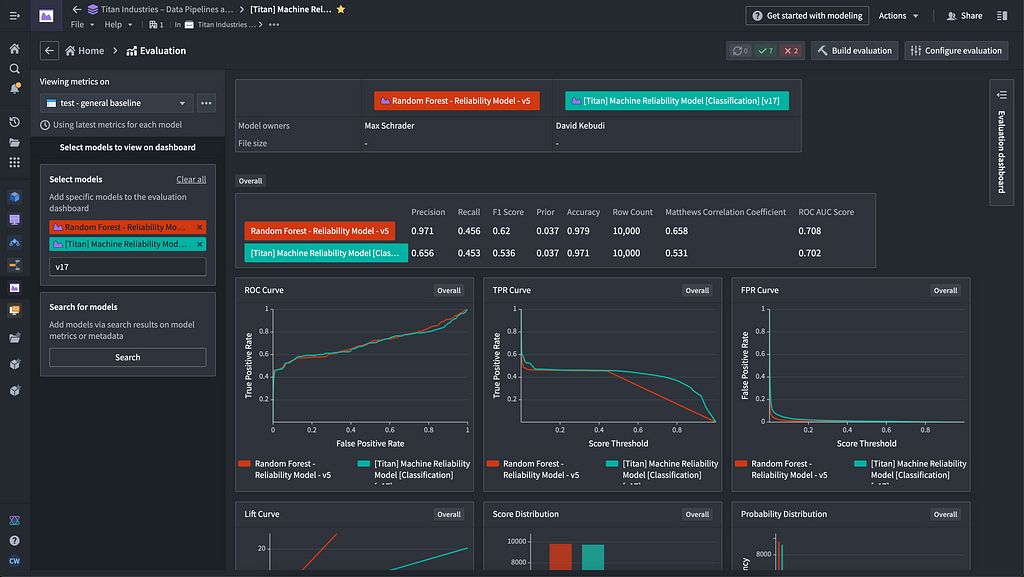
Getting models to a point where they are actually being used can be challenging; too often we see data science teams building models that never get to a productive state. In the video, we start with an example modeling objective — finding the probability of a machine breaking down — and walk through the steps to operationalizing it.
We start by looking at a production deployment within this modeling objective; i.e., an endpoint that’s actually hosting the model and enabling delivery to consumers — e.g., applications, pipelines, etc. Models can be deployed into managed batch inference pipelines or live API endpoints that provide real-time inferences.
Within the modeling objective, we can also dig into the logs and metrics. This enables us to not only understand the model’s performance, but also the performance of the inference server (and therefore make decisions regarding the resource profile).
As we touched on above, modeling objectives provide a CI/CD layer for models — we’re able move from a sandbox environment to a staging environment to production, with the right controls and checks in place along the way (e.g., requiring intentional upgrades via tagged and version releases, as well as an auditable model version history for production pipelines).
To decide which models to release, we need to evaluate them. To do that, we use the evaluation dashboard, where we can pick evaluation datasets, evaluation libraries, evaluation subsets (to see how models perform across differing domains, e.g., on data from different geographic locations). In the dashboard, we can easily compare the performance of two or more different models across a variety of dimensions.
There are 27 models under this one modeling objective in this example. For all of these models, we are able to implement review gates, granularly track the current status, and perform testing before releasing them to staging.
Tool Factory: Auto ML
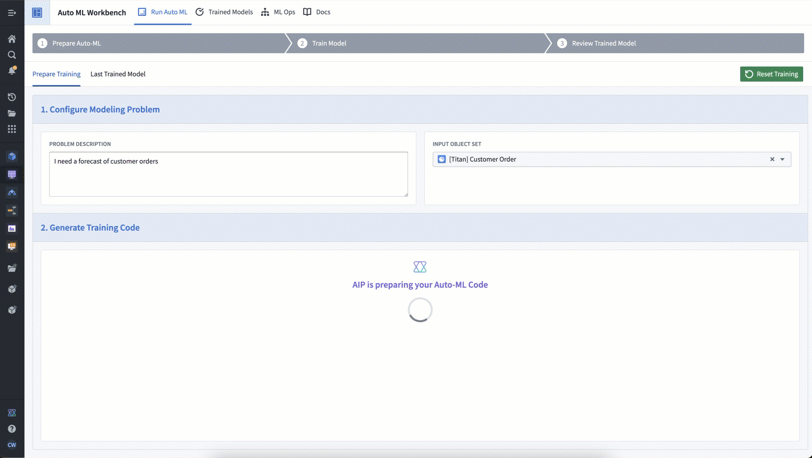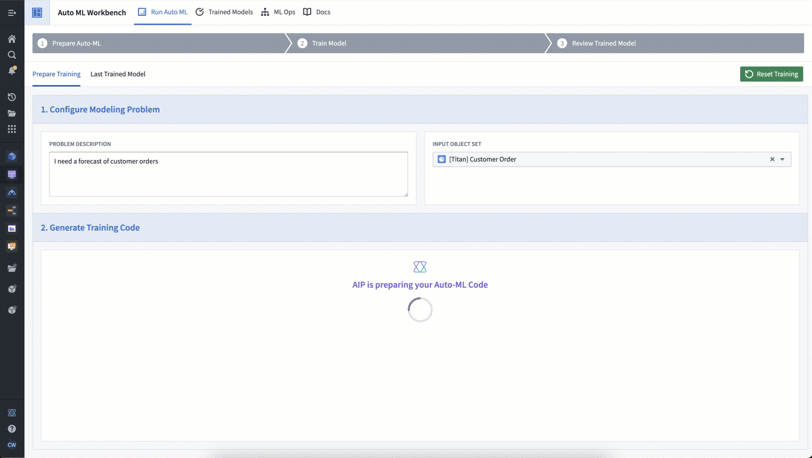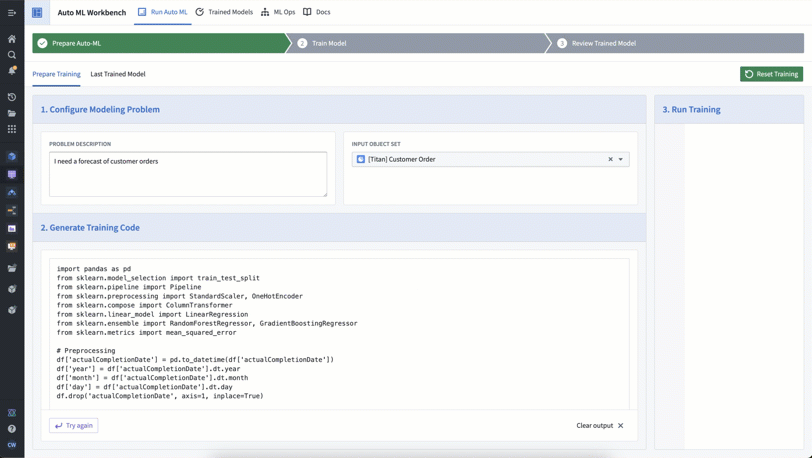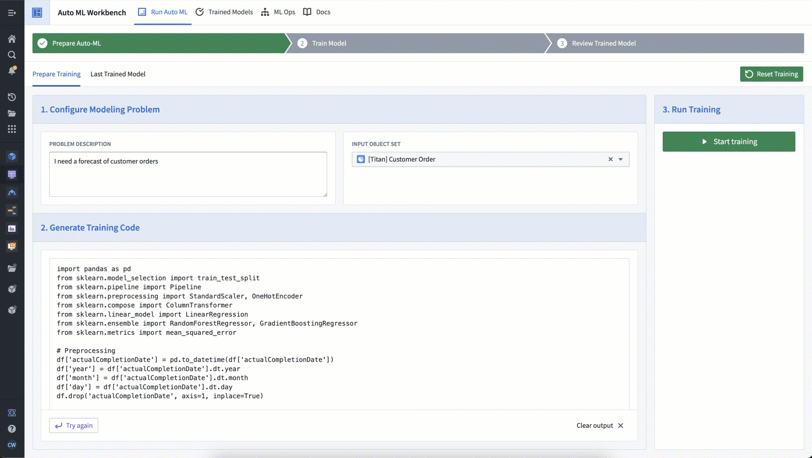
Auto ML is a Workshop app that leverages generative AI to help us produce model training code more efficiently. With Auto ML, we can input a description of the problem we want to solve — in this case, forecasting customer orders for Titan — and the relevant Ontology object set — here, it’s the customer order object.
Auto ML then uses an LLM-backed function (authored in AIP Logic) to generate the model training code, which we can then use to build models to achieve our modeling objective.
This is yet another example of how we can use AIP as a tool factory — in essence, leveraging AI to build a range of tools that can help us accomplish specific tasks (like writing model training code) more efficiently.
Logic Tools
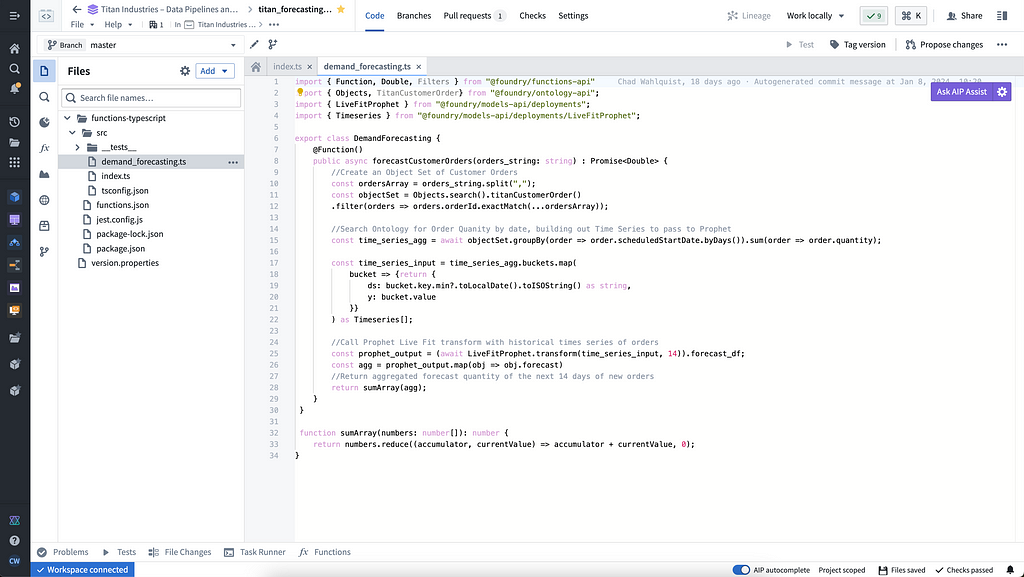
We now want to add in our AIP Logic function to ensure we have the right inventory in the right place at the right time.
Within the Workshop app we built in the last video, we have our supply chain co-pilot that navigates Titan’s ontology, surfacing the impacted customer orders along with proposed solutions. We’re now augmenting this application to forecast customer orders and help Titan manage this disruption over a longer time horizon. To do this, we’re creating another tool — this time, a logic tool to enable the LLM pull an accurate forecast of customer orders.
We already have a times series forecasting objective from our work in Auto ML, and we’ll use Meta’s Prophet framework to create a regressive model that will take this time series data on customer orders from Titan’s ontology and use it to generate a forecast.
Since we’re using a live endpoint of Prophet, we can connect it to AIP through a model adapter. Setting up the adapter is straightforward in AIP; we’re quickly able to get a 14-day forecast of customer orders.
LLMs Integrating with Forecast Models
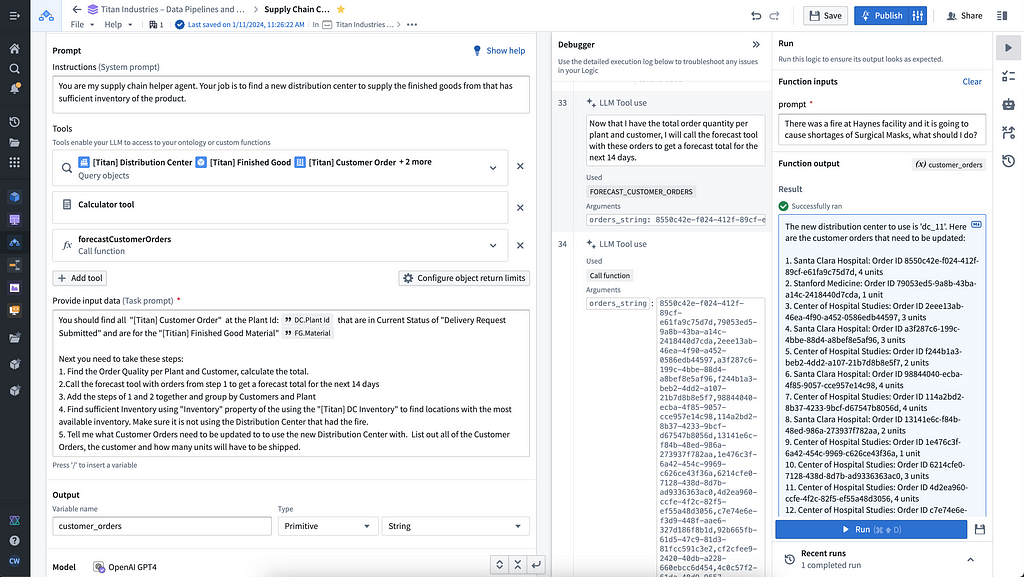
In AIP Logic, we can integrate our LLM with the forecasting model for use in our end application.
As a reminder, AIP Logic enables us to create AI-powered functions in a no-code environment that simplifies the integration of advanced LLMs with the Ontology. Last time, we demonstrated how AIP Logic allows us to equip the LLM with an Ontology-driven data tool.
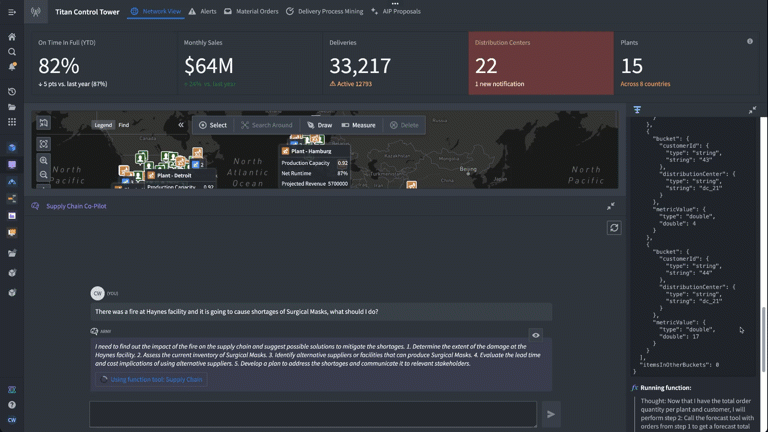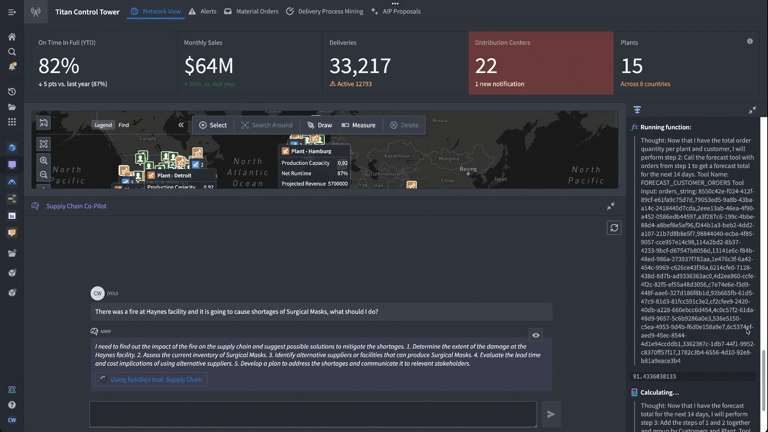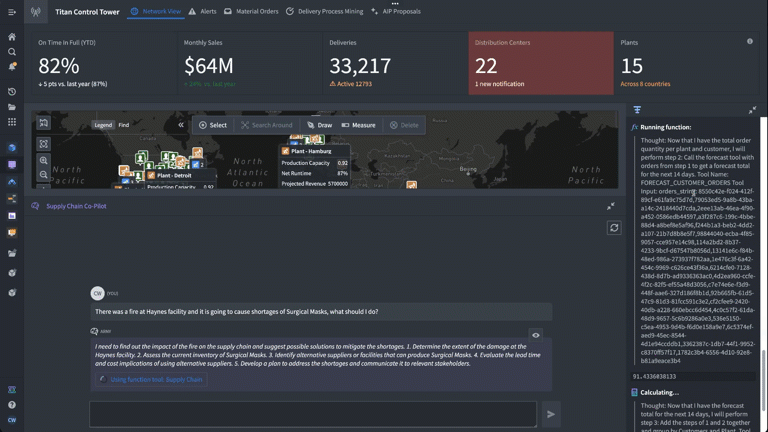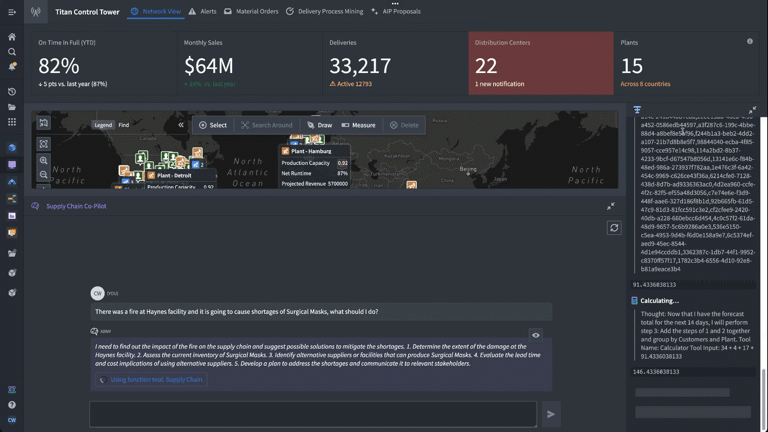
Based on the prompt (“there was a fire at Haynes facility and it is going to cause shortages of surgical masks, what should I do?”) we have set up our logic blocks to have the LLM find the appropriate finished good and distribution center in the Ontology, identify distribution centers with adequate supply of the necessary materials to fill the gaps, and return a list of affected orders and suggested remediations.
This time, we have added a calculator and the forecasting customer orders logic function we just built. We set up the task prompt as if we were giving a new analyst instructions, providing a step-by-step walkthrough of how to complete this task. Specifically, we tell the LLM when and how to use the forecasting tool we have equipped it with to generate a forecasted total for impacted orders over the next 14 days.
As we look through the debugger to ensure that everything is working as expected, we can see that in real time, we’re generating forecasts triggered by an LLM using the Ontology.
AIP Co-Pilot Using Logic Tools
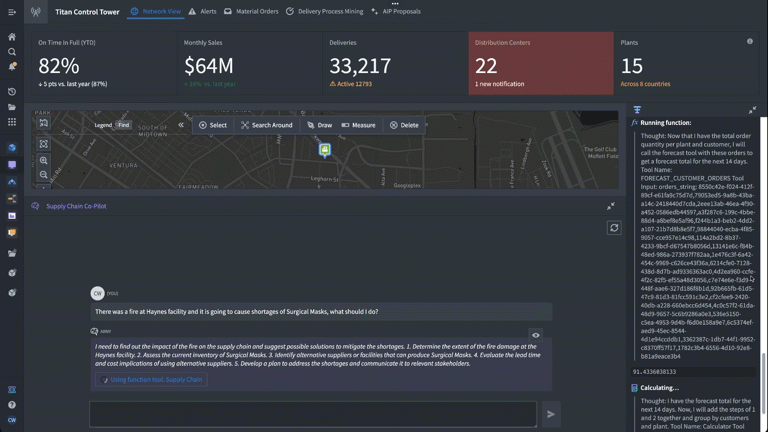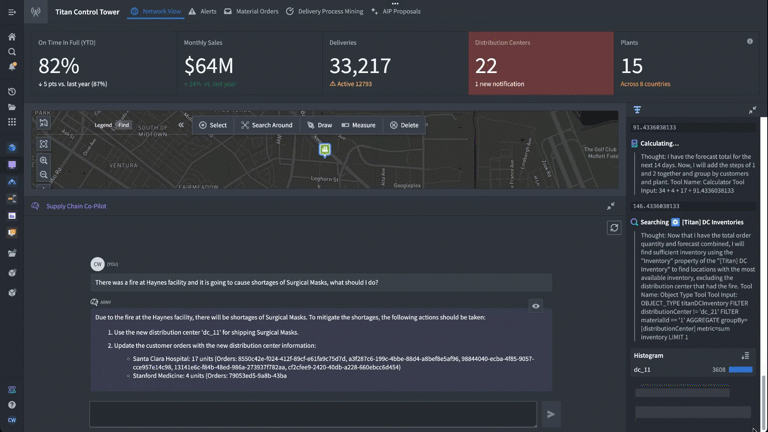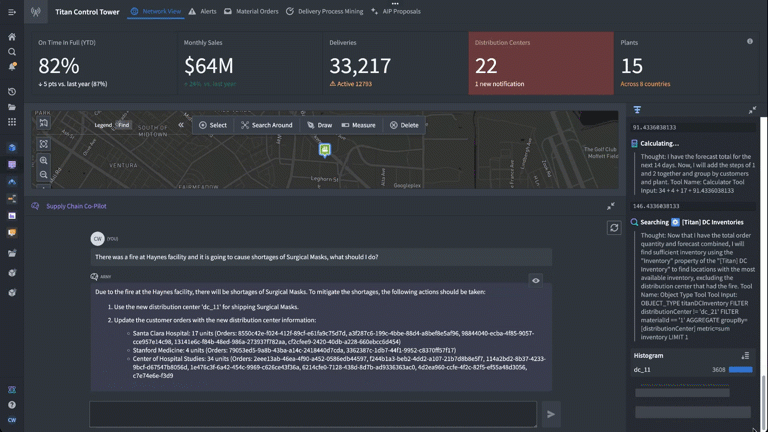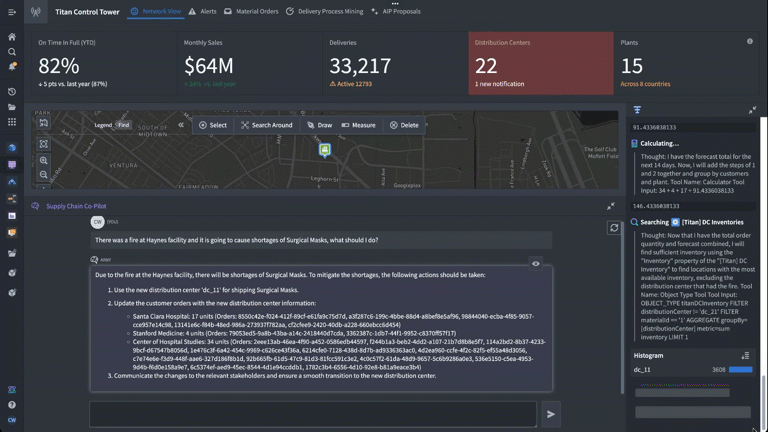
Now that we’ve integrated the forecasting model into our LLM function in AIP Logic, we can see it in action.
The application shows the Chain of Thought (CoT) reasoning steps that the LLM is taking, including accessing objects in the Ontology and running the forecasting function we added in. We have complete visibility into not only the LLM’s reasoning, but also how it is deploying the different data and logic tools we’ve equipped it with to generate accurate, reliable responses grounded in the operational reality of the enterprise.
Next time, we’ll delve into actions.
Conclusion
If you’re ready to unlock the power of full spectrum AI with AIP, sign up for an AIP Bootcamp today. Your team will learn from Palantir experts, and more importantly, get hands-on experience with AIP and walk away having assembled real workflows in a production environment.
Let’s Build!
Chad
![]()
Building with Palantir AIP: Logic Tools for RAG/OAG was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.