California Voted for Cheaper Uber Rides. It May Have Hurt Drivers
Uber and Lyft spent millions promoting a controversial ballot measure. A new study suggests it has lowered driver wages.
Uber and Lyft spent millions promoting a controversial ballot measure. A new study suggests it has lowered driver wages.
These mobile accessories will make your smartphone a better—and safer—road trip companion.
Nintendo’s latest in its paint-powered “squid game” franchise is just as fun and colorful as before, and is also a refreshing breath of fresh air.
Yes, I got Xbox Game Pass Ultimate and PlayStation Remote Play working on my Steam Deck.
Many associate the ‘America First’ movement with Trump, but its origins—and rebirth—are more complicated.

The challenges of keeping health data private — and why lineage-aware data deletion matters The global COVID-19 crisis, the first pandemic of its kind in recent history, brought about an unprecedented set of challenges. Faced with a public health crisis, governments around the world established far-reaching emergency measures in an attempt to “flatten the curve” and protect citizens. …
Read more “Safeguarding Privacy in Healthcare through Systematic Data Deletion”
Eli Manning was the obvious choice. For the last six years, IBM has been working with ESPN to infuse AI-generated insights into their fantasy football platform. But we needed someone who could help us tell the story; someone who could grab the attention of fantasy football enthusiasts, introduce them to the artificial intelligence of Watson, …
Read more “Eli Manning and the power of AI in ESPN fantasy football”
Organizations are increasingly depending upon artificial intelligence (AI) and Machine Learning (ML) to assist humans in decision making. It’s how top organizations improve customer interactions and accelerate time-to-market for goods and services. But these organizations need to be able to trust their AI/ML models before they can be operationalized and used in crucial business processes. …
Read more “How to enable trustworthy AI with the right data fabric solution”

Posted by Weicheng Kuo and Anelia Angelova, Research Scientists, Google Research, Brain Team Natural language enables flexible descriptive queries about images. The interaction between text queries and images grounds linguistic meaning in the visual world, facilitating a better understanding of object relationships, human intentions towards objects, and interactions with the environment. The research community has …
Read more “FindIt: Generalized Object Localization with Natural Language Queries”
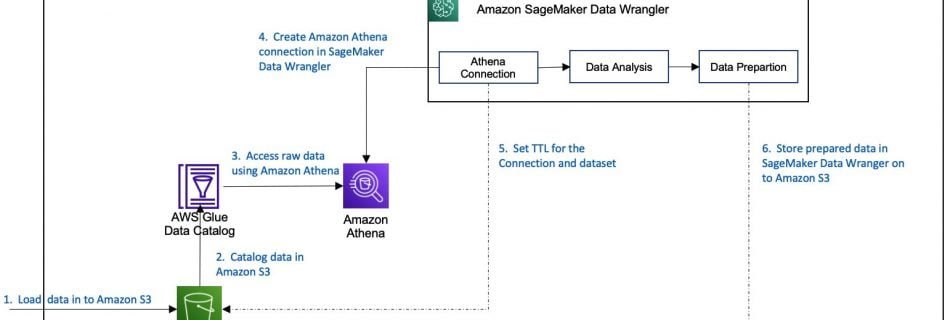
Amazon SageMaker Data Wrangler reduces the time that it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio, the first fully integrated development environment (IDE) for ML. With Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of …