Identifying, collecting, and transforming data is the foundation for machine learning (ML). According to a Forbes survey, there is widespread consensus among ML practitioners that data preparation accounts for approximately 80% of the time spent in developing a viable ML model.
In addition, many of our customers face several challenges during the model operationalization phase to accelerate the journey from model conceptualization to productionization. Quite often, models are built and deployed using poor-quality, under-representative data samples, which leads to more iterations and more manual effort in data inspection, which in turn makes the process more time consuming and cumbersome.
Because your models are only as good as your training data, expert data scientists and practitioners spend an enormous time understanding the data and generating valuable insights prior to building the models. If we view our ML models as an analogy to cooking a meal, the importance of high-quality data for an advanced ML system is similar to the relationship between high-quality ingredients and a successful meal. Therefore, before rushing into building the models, make sure you’re spending enough time getting high-quality data and extracting relevant insights.
The tools and technologies to assist with data preprocessing have been growing over the years. Now we have low-code and no-code tools like Amazon SageMaker Data Wrangler, AWS Glue DataBrew, and Amazon SageMaker Canvas to assist with data feature engineering.
However, a lot of these processes are still currently done manually by a data engineer or analyst who analyzes the data using these tools. If their the knowledge of the tools is limited, the insights generated prior to building the models won’t do justice to all the steps that can be performed. Additionally, we won’t be able to make an informed decision post-analysis of those insights prior to building the ML models. For instance, the models can turn out to be biased due to lack of detailed insights that you received using AWS Glue or Canvas, and you end up spending a lot of time and resources building the model training pipeline, to eventually receive an unsatisfactory prediction.
In this post, we introduce a novel intelligent framework for data and model operationalization that provides automated data transformations and optimal model deployment. This solution can accelerate accurate and timely inspection of data and model quality checks, and facilitate the productivity of distinguished data and ML teams across your organization.
Overview of solution
Our solution demonstrates an automated end-to-end approach to perform exploratory data analysis (EDA) with a human in the loop to determine the model quality thresholds and approve the optimal and qualified data to be pushed into Amazon SageMaker Pipelines in order to push the final data into Amazon SageMaker Feature Store, thereby speeding up the executional framework.
Furthermore, the approach includes deploying the best candidate model and creating the model endpoint on the transformed dataset that was automatically processed as new data arrives in the framework.
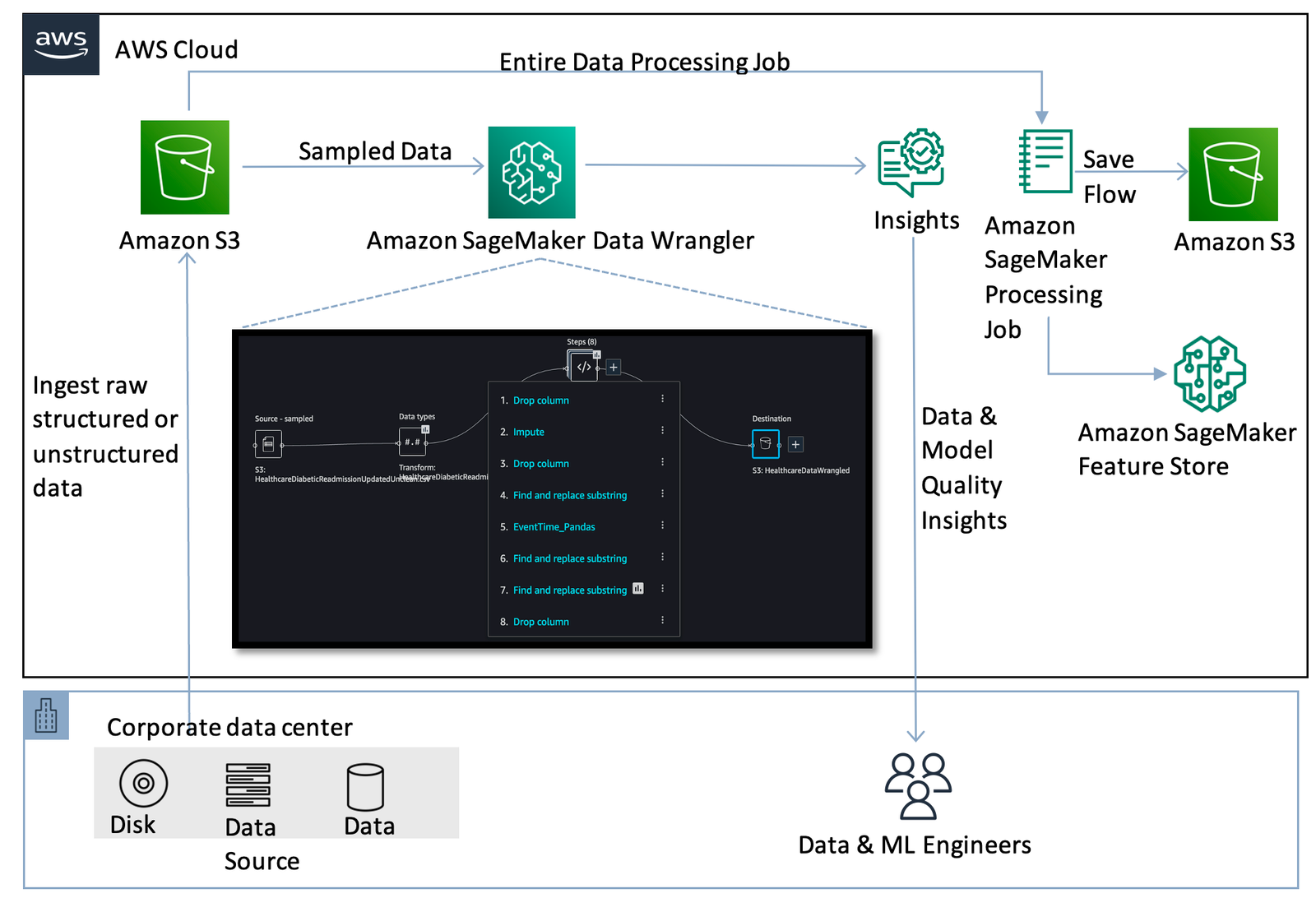
The following diagram illustrates the initial setup for the data preprocessing step prior to automating the workflow.

This step comprises the data flow initiation to process the raw data stored in an Amazon Simple Storage Service (Amazon S3) bucket. A sequence of steps in the Data Wrangler UI are created to perform feature engineering on the data (also referred to as a recipe). The data flow recipe consists of preprocessing steps along with a bias report, multicollinearity report, and model quality analysis.
Then, an Amazon SageMaker Processing job is run to save the flow to Amazon S3 and store the transformed features into Feature Store for reusable purposes.
After the flow has been created, which includes the recipe of instructions to be run on the data pertaining to the use case, the goal is to automate the process of creating the flow on any new incoming data, and initiate the process of extracting model quality insights using Data Wrangler. Then, the information regarding the transformations performed on the new data is parsed to an authorized user to inspect the data quality, and the pipeline waits for approval to run the model building and deployment step automatically.
The following architecture showcases the end-to-end automation of data transformation followed by human in the loop approval to facilitate the steps of model training and deployment.

The steps consist of an end-to-end orchestration for automated data transformation and optimal model deployment (with a human in the loop) using the following sequence of steps:
- A new object is uploaded into the S3 bucket (in our case, our training data).
- An AWS Lambda function is triggered when the object is uploaded in Amazon S3, which invokes AWS Step Functions and notifies the authorized user via a registered email.The following steps occur within the Step Functions orchestration:
- The Data Wrangler Flow Creation Lambda function fetches the Data Wrangler flow and processes the new data to be ingested into the Data Wrangler flow. It creates a new flow, which, when imported into the Data Wrangler UI, includes all the transformations, along with a model quality report and bias report. The function saves this latest flow in a new destination bucket.
- The User Callback Approval Lambda function sends a trigger notification via Amazon Simple Notification Service (Amazon SNS) to the registered persona via email to review the analyzed flow created on new unseen data information. In the email, the user has the option to accept or reject the data quality outcome and feature engineering flow.
- The next step is based on the approver’s decision:
- If the human in the loop approved the changes, the Lambda function initiates the SageMaker pipeline in the next state.
- If the human in the loop rejected the changes, the Lambda function doesn’t initiate the pipeline, and allows the user to look into the steps within the flow to perform additional feature engineering.
- The SageMaker Pipeline Execution Lambda function runs the SageMaker pipeline to create a SageMaker Processing job, which stores the feature engineered data in Feature Store. Another pipeline is created in parallel to save the transformed data to Amazon S3 as a CSV file.
- The AutoML Model Job Creation and Deployment Lambda function initiates an Amazon SageMaker Autopilot job to build and deploy the best candidate model and create a model endpoint, which authorized users can invoke for inference.
A Data Wrangler flow is available in our code repository that includes a sequence of steps to run on the dataset. We use Data Wrangler within our Amazon SageMaker Studio IDE, which can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization from a single visual interface.
Dataset
To demonstrate the orchestrated workflow, we use an example dataset regarding diabetic patient readmission. This data contains historical representations of patient and hospital outcomes, wherein the goal involves building an ML model to predict hospital readmission. The model has to predict whether the high-risk diabetic patients are likely to be readmitted to the hospital after a previous encounter within 30 days or after 30 days. Because this use case deals with multiple outcomes, this is a multi-class classification ML problem. You can try out the approach with this example and experiment with additional data transformations following similar steps with your own datasets.
The sample dataset we use in this post is a sampled version of the Diabetes 130-US hospitals for years 1999-2008 Data Set (Beata Strack, Jonathan P. DeShazo, Chris Gennings, Juan L. Olmo, Sebastian Ventura, Krzysztof J. Cios, and John N. Clore, “Impact of HbA1c Measurement on Hospital Readmission Rates: Analysis of 70,000 Clinical Database Patient Records,” BioMed Research International, vol. 2014, Article ID 781670, 11 pages, 2014.). It contains historical data including over 15 features with patient and hospital outcomes. The dataset contains approximately 69,500 rows. The following table summarizes the data schema.
| Column Name | Data Type | Data Description |
race | STRING | Caucasian, Asian, African American, or Hispanic. |
time_in_hospital | INT | Number of days between admission and discharge (length of stay). |
number_outpatient | INT | Number of outpatient visits of the patient in a given year before the encounter. |
number_inpatient | INT | Number of inpatient visits of the patient in a given year before the encounter. |
number_emergency | INT | Number of emergency visits of the patient in a given year before the encounter. |
number_diagnoses | INT | Number of diagnoses entered in the system. |
num_procedures | INT | Number of procedures (other than lab tests) performed during the encounter. |
num_medications | INT | Number of distinct generic medicines administrated during the encounter. |
num_lab_procedures | INT | Number of lab tests performed during the encounter. |
max_glu_serum | STRING | The range of result or if the test wasn’t taken. Values include >200, >300, normal, and none (if not measured). |
gender | STRING | Values include Male, Female and Unknown/Invalid. |
diabetes_med | INT | Indicates if any diabetes medication was prescribed. |
change | STRING | Indicates if there was a change in diabetes medications (ether dosage or generic name). Values are change or no change. |
age | INT | Age of patient at the time of encounter. |
a1c_result | STRING | Indicates the range of the result of blood sugar levels. Values include >8, >7, normal, and none. |
readmitted | STRING | Days to inpatient readmission. Values include <30 if patient was readmitted in less than 30 days, >30 if patient was readmitted after 30 days of encounter, and no for no record of readmission. |
Prerequisites
This walkthrough includes the following prerequisites:
- An AWS account
- A Studio domain managed policy attached to the AWS Identity and Access Management (IAM) execution role. For instructions on assigning permissions to the role, refer to Amazon SageMaker API Permissions: Actions, Permissions, and Resources Reference. In this case, you need to assign permissions as allocated to Amazon Augmented AI (Amazon A2I). For more information, refer to Amazon SageMaker Identity-Based Policy Examples.
- An S3 bucket. For instructions, refer to Creating a bucket.
- For this post, you use the AWS Cloud Development Kit (AWS CDK) using Python. Follow the instructions in Getting Started for AWS CDK to set up your local environment setup and bootstrap your development account.
Upload the historical dataset to Amazon S3
The first step is to download the sample dataset and upload it into an S3 bucket. In our case, our training data (diabetic-readmission.csv) is uploaded.
Data Wrangler initial flow
Prior to automating the Step Functions workflow, we need to perform a sequence of data transformations to create a data flow.
If you want to create the Data Wrangler steps manually, refer to the readme in the GitHub repo.
To import the flow to automate the Data Wrangler steps, complete the following steps:
- Download the flow from the GitHub repo and save it in your system.
- Open Studio and import the Data Wrangler flow.You need to update the location of where it needs to import the latest dataset. In your case, this is the bucket you defined with the respective prefix.
- Choose the plus sign next to Source and choose Edit dataset.

- Point to the S3 location of the dataset you downloaded.

- Inspect all the steps in the transformation and make sure they align with the sequence steps.






Save data flow to Feature Store
To save the data flow to Feature Store, complete the following steps:
- Choose the plus sign next to Steps and choose Export to.

- Choose SageMaker Feature Store (via Jupyter Notebook).
SageMaker generates a Jupyter notebook for you and opens it in a new tab in Studio. This notebook contains everything you need to run the transformations over our historical dataset and ingest the resulting features into Feature Store.This notebook uses Feature Store to create a feature group, runs your Data Wrangler flow on the entire dataset using a SageMaker processing job, and ingests the processed data to Feature Store.
- Choose the kernel Python 3 (Data Science) on the newly opened notebook tab.
- Read through and explore the Jupyter notebook.
- In the Create Feature Group section of the generated notebook, update the following fields for the event time and record identifier with the column names we created in the previous Data Wrangler step:
- Choose Run and then choose Run All Cells.

- Enter
flow_name = "HealthCareUncleanWrangler". - Run the following cells to create your feature group name.
 After running a few more cells in the code, the feature group is successfully created.
After running a few more cells in the code, the feature group is successfully created. - Now that the feature group is created, you use a processing job to process your data at scale and ingest the transformed data into this feature group.
If we keep the default bucket location, the flow will be saved in a SageMaker bucket located in the specific Region where you launched your SageMaker domain. With
With Feature_store_offline_S3_uri, Feature Store writes the data in theOfflineStoreof aFeatureGroupto an Amazon S3 location owned by you.Wait for the processing job to finish. If it finishes successfully, your feature group should be populated with the transformed feature values. In addition, the raw parameters used by the processing job are printed.It takes 10–15 minutes to run the processing job to create and run the Data Wrangler flow on the entire dataset and save the output flow in the respective bucket within the SageMaker session. - Next, run the
FeatureStoreAutomation.ipynbnotebook by importing it in Studio from GitHub and running all the cells. Follow the instructions in the notebook. - Copy the following variables from the Data Wrangler generated output from the previous step and add them to the cell in the notebook:
- Run the rest of the code following the instructions in the notebook to create a SageMaker pipeline to automate the storing of features to Feature Store in the feature group that you created.
- Next, similar to the previous step in the Data Wrangler export option, choose the plus sign and choose Export to.
- Choose SageMaker Pipelines (via Jupyter Notebook).
- Run all the cells to create a CSV flow as an output to be stored to Amazon S3.That pipeline name is invoked in a Lambda function later to automate the pipeline on a new flow.
- Within the code, whenever you see the following instance count, change
instance_countto 1: - Otherwise, your account may hit the service quota limits of running an m5.4x large instance for processing jobs being run within the notebook. You have to request an increase in service quota if you want more instances to run the job.
- As you walk through the pipeline code, navigate to Create SageMaker Pipeline, where you define the pipeline steps.
- In the Output Amazon S3 settings cell, change the location of the Amazon S3 output path to the following code (commenting the output prefix):
- Locate the following code:
- Replace it with the following:
- Remove the following cell:
- Continue running the next steps until you reach the Define a Pipeline of Parameters section with the following code. Append the last line
input_flowto the code segment: - Also, add the
input_flowas an additional parameter to the next cell: - In the section Submit the pipeline to SageMaker and start execution, locate the following cell:
- Replace it with the following code:
- Copy the name of the pipeline you just saved.
This will be yourS3_Pipeline_Namevalue that is added as the environment variable stored inDataWrangler Flow CreationLambda Function. - Replace
S3_Pipeline_Namewith the name of the pipeline that you just created after running the preceding notebook.
Now, when a new object is uploaded in Amazon S3, a SageMaker pipeline runs the processing job of creating the Data Wrangler flow on the entire dataset and stores the transformed dataset in Amazon S3 as a CSV file. This object is used in the next step (the Step Functions workflow) for model training and endpoint deployment.We have created and stored a transformed dataset in Amazon S3 by running the preceding notebook. We also created a feature group in Feature Store for storing the respective transformed features for later reuse. - Update both pipeline names in the Data Wrangler Flow Creation Lambda function (created with the AWS CDK) for the Amazon S3 pipeline and Feature Store pipeline.



 After running a few more cells in the code, the feature group is successfully created.
After running a few more cells in the code, the feature group is successfully created. With
With Step Functions orchestration workflow
Now that we have created the processing job, we need to run these processing jobs on any incoming data that arrives in Amazon S3. We initiate the data transformation automatically, notify the authorized user of the new flow created, and wait for the approver to approve the changes based on data and model quality insights. Then, the Step Functions callback action is triggered to initiate the SageMaker pipeline and start the model training and optimal model deployment endpoint in the environment.
The Step Functions workflow includes a series of Lambda functions to run the overall orchestration. The Step Functions state machine, S3 bucket, Amazon API Gateway resources, and Lambda function codes are stored in the GitHub repo.
The following figure illustrates our Step Function workflow.

Run the AWS CDK code located in GitHub to automatically set up the stack containing the components needed to run the automated EDA and model operationalization framework. After setting up the AWS CDK environment, run the following command in the terminal:
Create a healthcare folder in the bucket you named via your AWS CDK script. Then upload flow-healthcarediabetesunclean.csv to the folder and let the automation happen!
In the following sections, we walk through each step in the Step Functions workflow in more detail.
Data Wrangler Flow Creation
As new data is uploaded into the S3 bucket, a Lambda function is invoked to trigger the Step Functions workflow. The Data Wrangler Flow Creation Lambda function fetches the Data Wrangler flow. It runs the processing job to create a new Data Wrangler flow (which includes data transformations, model quality report, bias report, and so on) on the ingested dataset and pushes the new flow to the designated S3 bucket.
This Lambda function parses the information to the User Callback Approval Lambda function and sends the trigger notification via Amazon SNS to the registered email with the location of the designated bucket where the flow has been saved.
User Callback Approval
The User Callback Approval step initiates the Lambda function that receives the updated flow information and sends a notification to the authorized user with the approval/rejection link to approve or reject the new flow. The user can review the analyzed flow created on the unseen data by downloading the flow from the S3 bucket and uploading it in the Data Wrangler UI.
After the user reviews the flow, they can go back to the email to approve the changes.
Manual Approval Choice
This Lambda function is waiting for the authorized user to approve or reject the flow.
If the answer received is yes (the user approved the flow), the SageMaker Pipeline Execution Lambda function initiates the SageMaker pipeline for storing the transformed features in Feature Store. Another SageMaker pipeline is initiated in parallel to save the transformed features CSV to Amazon S3, which is used by the next state (the AutoML Model Job Creation & Model Deployment Lambda function) for model training and deployment.
If the answer received is no (the user rejected the flow), the Lambda function doesn’t initiate the pipeline to run the flow. The user can look into the steps within the flow to perform additional feature engineering. Later, the user can rerun the entire sequence after adding additional data transformation steps in the flow.
SageMaker Pipeline Execution
This step initiates a Lambda function that runs the SageMaker pipeline to store the feature engineered data in Feature Store. Another pipeline in parallel saves the transformed data to Amazon S3.
You can monitor the two pipelines in Studio by navigating to the Pipelines page.

You can choose the graph to inspect the input, output, logs, and information.

Similarly, you can inspect the information of the other pipeline, which saves the transformed features CSV to Amazon S3.

AutoML Model Job Creation & Model Deployment
This step initiates a Lambda function that starts an Autopilot job to ingest the CSV from the previous Lambda function, and build and deploy the best candidate model. This step creates a model endpoint that can be invoked by authorized users. When the AutoML job is complete, you can navigate to Studio, choose Experiment and trials, and view the information associated with your job.

As all of these steps are run, the SageMaker dashboard reflects the processing job, batch transform job, training job, and hyperparameter tuning job that are being created in the process and the creation of the endpoint that can be invoked when the overall process is complete.

Clean up
To avoid ongoing charges, make sure to delete the SageMaker endpoint and stop all the notebooks running in Studio, including the Data Wrangler instances. Also, delete the output data in Amazon S3 you created while running the orchestration workflow via Step Functions. You have to delete the data in the S3 buckets before you can delete the buckets.
Conclusion
In this post, we demonstrated an end-to-end approach to perform automated data transformation with a human in the loop to determine model quality thresholds and approve the optimal qualified data to be pushed to a SageMaker pipeline to push the final data into Feature Store, thereby speeding up the executional framework. Furthermore, the approach includes deploying the best candidate model and creating the model endpoint on the final feature engineered data that was automatically processed when new data arrives.
References
For further information about Data Wrangler, Feature Store, SageMaker pipelines, Autopilot, and Step Functions, we recommend the following resources:
- Amazon SageMaker Pipelines Brings DevOps Capabilities to your Machine Learning Projects
- Step Functions for feature transformation
- Introducing SageMaker Data Wrangler, a Visual Interface to Prepare Data for Machine Learning
- Building machine learning workflows with Amazon SageMaker Processing jobs and AWS Step Functions
- Unified data preparation and model training with Amazon SageMaker Data Wrangler and Amazon SageMaker Autopilot
About the Author(s)
 Shikhar Kwatra is an AI/ML Specialist Solutions Architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 400 patents in the AI/ML and IoT domains. He has over 8 years of industry experience from startups to large-scale enterprises, from IoT Research Engineer, Data Scientist, to Data & AI Architect. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for organizations and supports GSI partners in building strategic industry solutions on AWS.
Shikhar Kwatra is an AI/ML Specialist Solutions Architect at Amazon Web Services, working with a leading Global System Integrator. He has earned the title of one of the Youngest Indian Master Inventors with over 400 patents in the AI/ML and IoT domains. He has over 8 years of industry experience from startups to large-scale enterprises, from IoT Research Engineer, Data Scientist, to Data & AI Architect. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for organizations and supports GSI partners in building strategic industry solutions on AWS.
 Sachin Thakkar is a Senior Solutions Architect at Amazon Web Services, working with a leading Global System Integrator (GSI). He brings over 22 years of experience as an IT Architect and as Technology Consultant for large institutions. His focus area is on data and analytics. Sachin provides architectural guidance and supports GSI partners in building strategic industry solutions on AWS.
Sachin Thakkar is a Senior Solutions Architect at Amazon Web Services, working with a leading Global System Integrator (GSI). He brings over 22 years of experience as an IT Architect and as Technology Consultant for large institutions. His focus area is on data and analytics. Sachin provides architectural guidance and supports GSI partners in building strategic industry solutions on AWS.