Context vs. Memory Engineering in Agentic AI Systems
Compression on Arrival Tool outputs should be compressed after a call returns, not after the window fills.
Compression on Arrival Tool outputs should be compressed after a call returns, not after the window fills.
I’ve been quiet since November because I’ve been building. Over the past few months, AI has moved so quickly that the barrier between an idea and a high-powered system has essentially vanished. Even as a non-developer, I’ve found that working with AI is like having a small team of A-level developers who work for $40 …
Multi-agent LLM systems are increasingly deployed as autonomous collaborators, where agents interact freely rather than execute fixed, pre-specified workflows. In such settings, effective coordination cannot be fully designed in advance and must instead emerge through interaction. However, most prior work enforces coordination through fixed roles, workflows, or aggregation rules, leaving open the question of how …

Editor’s Note: This is the fourth post in a series exploring how Palantir customizes infrastructure software for reliable operation at scale. The following is a guest contribution to the Foundations series from the Gotham Core Platform organization, which builds and maintains the bedrock for mission-critical applications within the Gotham ecosystem. This blog post by Kevin Liang, …
Read more “Managing Elasticsearch Reindex at Scale: Performance, Reliability, and Observability”

Authors: Lequn Wang, Jiangwei Pan, and Linas Baltrunas Figure 1. Autoregressive homepage generation. GenPage builds a Netflix homepage one row or entity at a time, each one conditioned on what’s already on the page and the user’s context. Introduction The Netflix homepage is the first thing users see when they open the app and the primary …
Read more “GenPage: Towards End-to-End Generative Homepage Construction at Netflix”
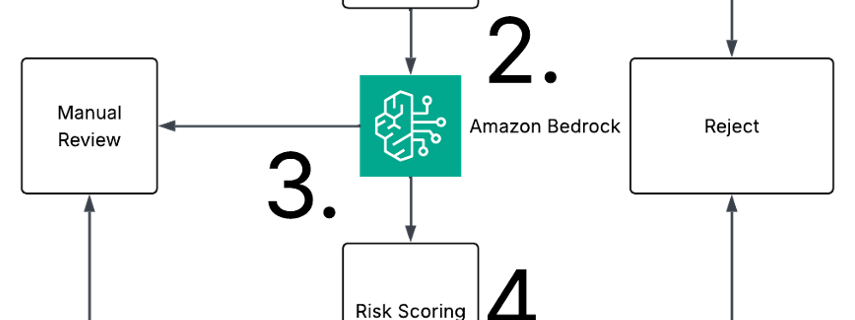
Social engineering through phishing remains one of the most common tactics for launching cyberattacks. AI-generated phishing email messages now pose a new challenge for security teams managing email systems, significantly raising the risk because of their advanced sophistication. Modern social engineers use generative AI and open source intelligence (OSINT) to craft thousands of unique messages …
Read more “How Amazon Bedrock catches AI-generated phishing”
The satirical site is fighting to officially take over Infowars. In the meantime, CEO Ben Collins says the new show will mock “how fucking stupid” conspiratorial brain rot has become.

Congratulations to the Berkeley Artificial Intelligence Research (BAIR) Lab class of 2026! This year, BAIR celebrates another remarkable group of Ph.D. graduates whose curiosity, creativity, and perseverance have pushed the frontiers of artificial intelligence and machine learning. Their work spans the breadth of modern AI — robotics and embodied intelligence, large language models and reasoning, …

Government agencies running workloads in AWS GovCloud (US) need AI capabilities that keep pace with the commercial sector. At the same time, they can’t compromise the security and compliance controls their missions require. As open-weight foundation models (FMs) move from experimentation into mission systems, two requirements shape every model decision. First, the model must deliver …
Read more “Run NVIDIA Nemotron and OpenAI GPT OSS models on Amazon Bedrock in AWS GovCloud (US)”

AlloyDB is an AI-native database—it isn’t just a passive data store, it intelligently understands and processes your data. With AlloyDB, you get industry-leading vector and hybrid search, near 100% accurate natural language-to-SQL capabilities to build conversational agents, tools to enable you to build with your agentic IDEs of choice, and the ability to bring the …
Read more “AlloyDB AI Functions – now with revolutionary performance boosts and cost savings”