The 28 Best Deals From REI’s July 4 Outdoor Gear Sale (2025)
Whether you need a tent, sleeping pad, rain jacket, or new pack, REI’s Independence Day sale has something for everyone.
Whether you need a tent, sleeping pad, rain jacket, or new pack, REI’s Independence Day sale has something for everyone.
You can find the workflow by scrolling down on this page: https://comfyanonymous.github.io/ComfyUI_examples/flux/ submitted by /u/comfyanonymous [link] [comments]
Machine learning practitioners spend countless hours on repetitive tasks: monitoring model performance, retraining pipelines, data quality checks, and experiment tracking.
This post is divided into four parts; they are: • Why Attention Masking is Needed • Implementation of Attention Masks • Mask Creation • Using PyTorch’s Built-in Attention In the
Artificial intelligence (AI) is an umbrella computer science discipline focused on building software systems capable of mimicking human or animal intelligence capabilities to solve a task.
With advances in generative AI, there is increasing work towards creating autonomous agents that can manage daily tasks by operating user interfaces (UIs). While prior research has studied the mechanics of how AI agents might navigate UIs and understand UI structure, the effects of agents and their autonomous actions—particularly those that may be risky or …
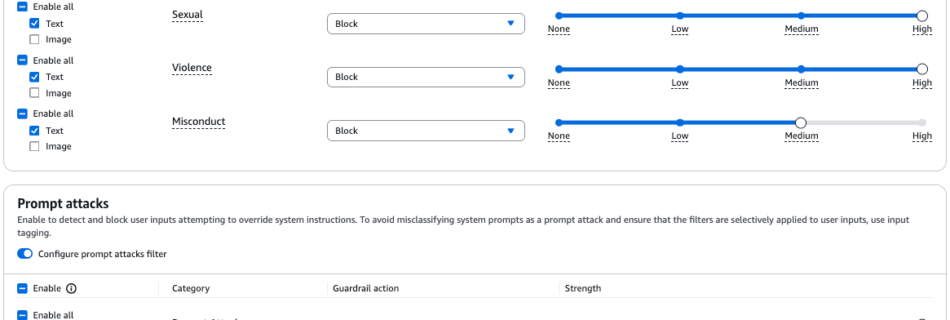
Amazon Bedrock Guardrails provides configurable safeguards to help build trusted generative AI applications at scale. It provides organizations with integrated safety and privacy safeguards that work across multiple foundation models (FMs), including models available in Amazon Bedrock, as well as models hosted outside Amazon Bedrock from other model providers and cloud providers. With the standalone …
Read more “Tailor responsible AI with new safeguard tiers in Amazon Bedrock Guardrails”
A great story doesn’t just tell you, it shows you. With Veo 3, we’ve leapt forward in combining video and audio generation to take storytelling to the next level. Today, we’re excited to share that Veo 3 is now available for all Google Cloud customers and partners in public preview on Vertex AI. Why this …
Enterprise teams hit a scaling wall when managing AI agents across departments. Writer’s May Habib explains why traditional software development fails for agents and what Fortune 500 companies are doing instead.Read More
Edward “Big Balls” Coristine’s placement at the SSA comes after a White House official told WIRED on Tuesday that the 19-year-old had resigned from his position in government.