The Signal Clone Mike Waltz Was Caught Using Has Direct Access to User Chats
A new analysis of TM Signal’s source code appears to show that the app sends users’ message logs in plaintext. At least one top Trump administration official used the app.
A new analysis of TM Signal’s source code appears to show that the app sends users’ message logs in plaintext. At least one top Trump administration official used the app.
While service robots with male characteristics can be more persuasive when interacting with some women who have a low sense of decision-making power, ‘cute’ design features — such as big eyes and raised cheeks — affect both men and women similarly, according to new research.
What would a behind-the-scenes look at a video generated by an artificial intelligence model be like? You might think the process is similar to stop-motion animation, where many images are created and stitched together, but that’s not quite the case for “diffusion models” like OpenAI’s SORA and Google’s VEO 2.
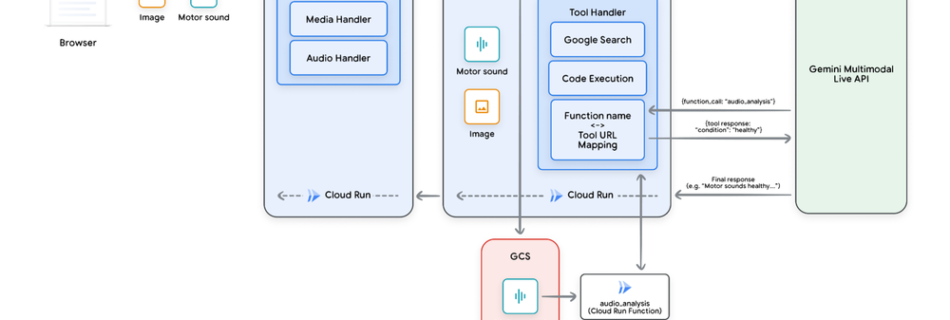
Across industries, enterprises need efficient and proactive solutions. Imagine frontline professionals using voice commands and visual input to diagnose issues, access vital information, and initiate processes in real-time. The Gemini 2.0 Flash Live API empowers developers to create next-generation, agentic industry applications. This API extends these capabilities to complex industrial operations. Unlike solutions relying on …
Read more “Build live voice-driven agentic applications with Vertex AI Gemini Live API”
Cisco’s Foundation-sec-8B LLM & Meta’s AI Defenders redefine cybersecurity with open-source AI for scalable SOCs.Read More
The startup behind ChatGPT is going to remain in nonprofit control, but it still needs regulatory approval.
Computer scientists have developed a new AI text-to-video model that learns real-world physics knowledge from time-lapse videos.
Discovering new, powerful electrolytes is one of the major bottlenecks in designing next-generation batteries for electric vehicles, phones, laptops and grid-scale energy storage.
Humans need to embrace domains where AI still falters, and where human creativity, ethics and emotion emain indispensable.Read More
At the Miami Grand Prix’s driver’s parade, the sport’s biggest stars rode in drivable Lego cars that took eight months to build. It was as awesome as it sounds.