Stumbling and Overheating, Most Humanoid Robots Fail to Finish Half Marathon in Beijing
Only four of the 21 robots in the race crossed the finish line, highlighting just how far humanoids are from keeping up with their real human counterparts.
Only four of the 21 robots in the race crossed the finish line, highlighting just how far humanoids are from keeping up with their real human counterparts.
Step by mechanical step, dozens of humanoid robots took to the streets of Beijing early Saturday, joining thousands of their flesh-and-blood counterparts in a world-first half marathon showcasing China’s drive to lead the global race in cutting-edge technology.
This post is divided into three parts; they are: • Building a Semantic Search Engine • Document Clustering • Document Classification If you want to find a specific document within a collection, you might use a simple keyword search.
Using llama.
Scaling the input image resolution is essential for enhancing the performance of Vision Language Models (VLMs), particularly in text-rich image understanding tasks. However, popular visual encoders such as ViTs become inefficient at high resolutions due to the large number of tokens and high encoding latency. At different operational resolutions, the vision encoder of a VLM …
Read more “FastVLM: Efficient Vision encoding for Vision Language Models”
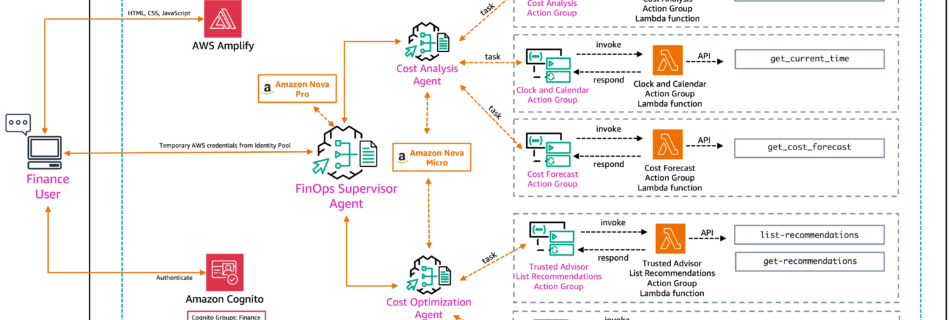
AI agents are revolutionizing how businesses enhance their operational capabilities and enterprise applications. By enabling natural language interactions, these agents provide customers with a streamlined, personalized experience. Amazon Bedrock Agents uses the capabilities of foundation models (FMs), combining them with APIs and data to process user requests, gather information, and execute specific tasks effectively. The …
NOV’s CIO led a cyber strategy fusing Zero Trust, AI, and airtight identity controls to cut threats by 35x and eliminating reimaging.Read More
Our top picks keep everything in place, even if your workout is just a walk to the fridge.
AI models often rely on “spurious correlations,” making decisions based on unimportant and potentially misleading information. Researchers have now discovered these learned spurious correlations can be traced to a very small subset of the training data and have demonstrated a technique that overcomes the problem. The work has been published on the arXiv preprint server.
Machine learning models are trained on historical data and deployed in real-world environments.