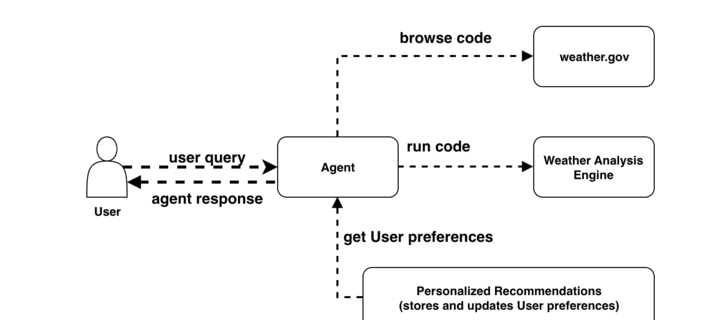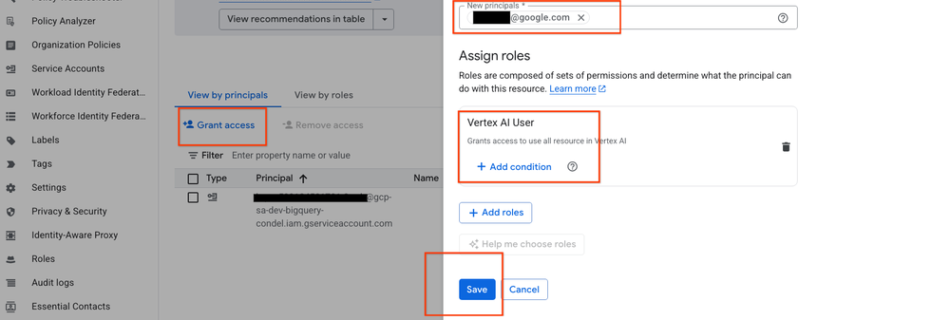
BigQuery AI supports Gemini 3.0, simplified embedding generation and new similarity function
The digital landscape is flooded with unstructured data — images, videos, audio, and documents — that often remain untapped. To help you unlock this data’s potential with minimal friction, we have integrated Gemini and other Vertex AI models directly into BigQuery, simplifying how you work with generative AI and embedding models using BigQuery SQL.New launches …