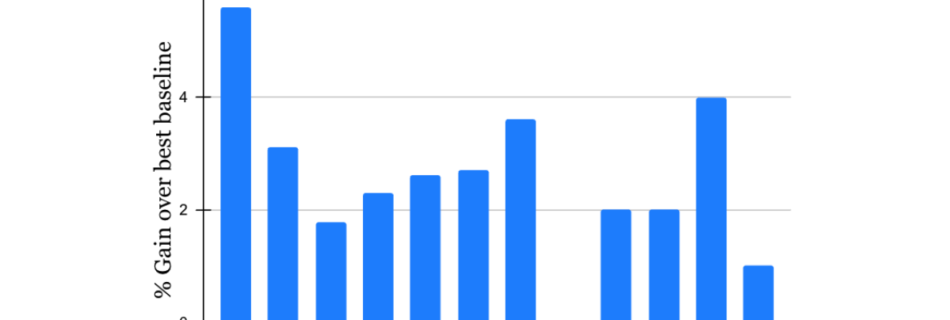
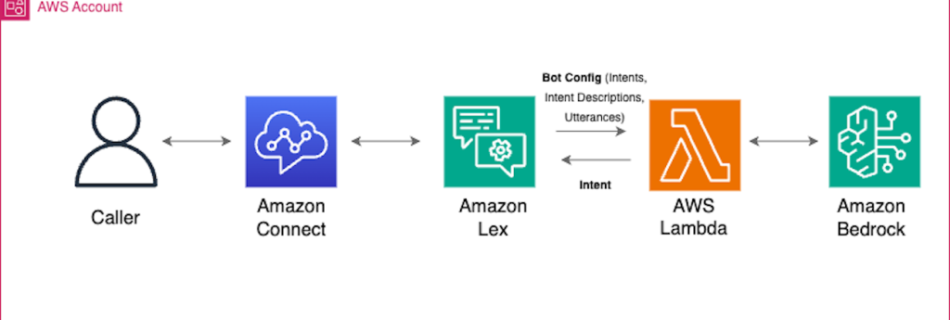
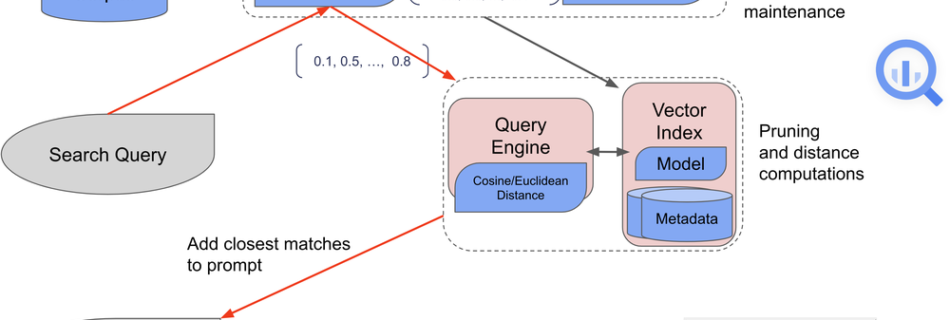
Veterans Affairs & Palantir
How data-driven acquisition identified over $90M in savings for VA in 6 months Editor’s Note: This post was written jointly with the U.S. Department of Veterans Affairs. Intro The U.S. Department of Veterans Affairs (VA) is one of the largest integrated health care systems in the United States, providing care at 1,298 health care facilities to over …