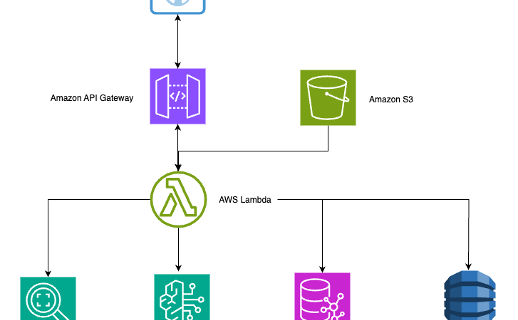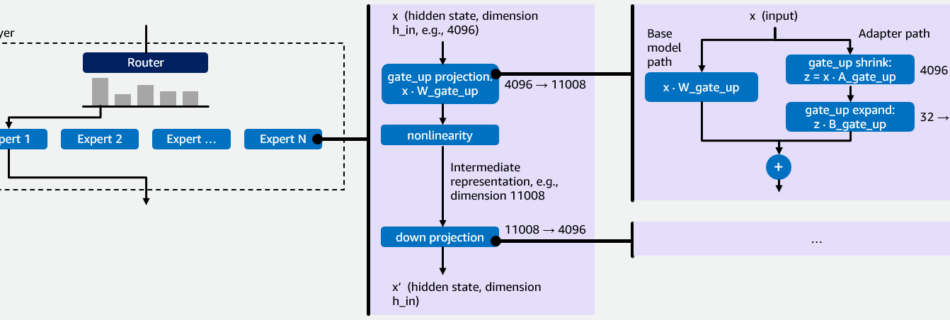
Efficiently serve dozens of fine-tuned models with vLLM on Amazon SageMaker AI and Amazon Bedrock
Organizations and individuals running multiple custom AI models, especially recent Mixture of Experts (MoE) model families, can face the challenge of paying for idle GPU capacity when the individual models don’t receive enough traffic to saturate a dedicated compute endpoint. To solve this problem, we have partnered with the vLLM community and developed an efficient …