Introducing the Gemini 2.5 Computer Use model
Available in preview via the API, our Computer Use model is a specialized model built on Gemini 2.5 Pro’s capabilities to power agents that can interact with user interfaces.
Available in preview via the API, our Computer Use model is a specialized model built on Gemini 2.5 Pro’s capabilities to power agents that can interact with user interfaces.
Video Joint Embedding Predictive Architectures (V-JEPA) learn generalizable off-the-shelf video representation by predicting masked regions in latent space with an exponential moving average (EMA)-updated teacher. While EMA prevents representation collapse, it complicates scalable model selection and couples teacher and student architectures. We revisit masked-latent prediction and show that a frozen teacher suffices. Concretely, we (i) …
Read more “Rethinking JEPA: Compute-Efficient Video SSL with Frozen Teachers”
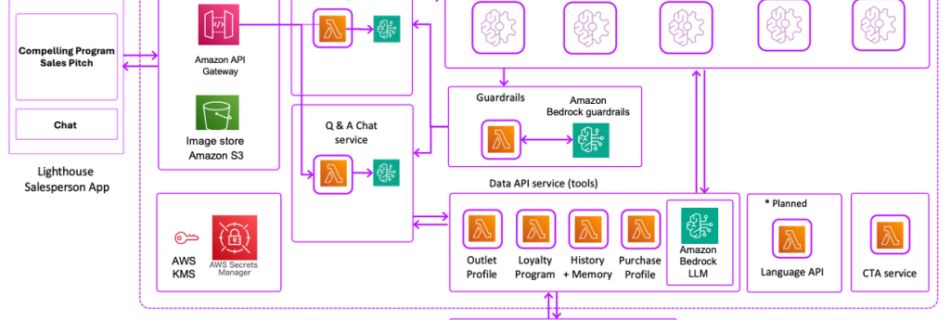
This post was co-written with Cyril Ovely from Vxceed. Consumer packaged goods (CPG) companies face a critical challenge in emerging economies: how to effectively retain revenue and grow customer loyalty at scale. Although these companies invest 15–20% of their revenue in trade promotions and retailer loyalty programs, the uptake of these programs has historically remained …
Read more “Vxceed builds the perfect sales pitch for sales teams at scale using Amazon Bedrock”

Startups are using agentic AI to automate complex workflows, create novel user experiences, and solve business problems that were once considered technically impossible. Still, charting the optimal path forward — especially with the integration of AI agents — often presents significant technical complexity To help startups navigate this new landscape, we’re launching our Startup technical …
Read more “Want to get building production-ready AI agents? Here’s where startups should start.”
Researchers at the University of Illinois Urbana-Champaign and Google Cloud AI Research have developed a framework that enables large language model (LLM) agents to organize their experiences into a memory bank, helping them get better at complex tasks over time. The framework, called ReasoningBank, distills “generalizable reasoning strategies” from an agent’s successful and failed attempts …
Read more “New memory framework builds AI agents that can handle the real world’s unpredictability”
Time is running out—don’t miss Amazon’s fall 2025 Prime Day sale deals on WIRED-tested favorites like Kindles, laptops, Apple Watches, robot vacs, and more.
Most people enjoy receiving praise occasionally, but if it comes from sycophantic chatbots, it could be doing you more harm than good. Computer scientists from Stanford University and Carnegie Mellon University have found that people-pleasing chatbots can have a detrimental impact on our judgment and behavior.
Hi everyone, this is just another attempt at doing a full 360. It has flaws but that’s the best one I’ve been able to do using an open source model like wan 2.2. EDIT: a better one (added here to avoid post spamming) https://i.redd.it/fa04y0e8brtf1.gif submitted by /u/YouYouTheBoss [link] [comments]
One of the claims made by OpenAI regarding its latest model, GPT-5 , is a breakthrough in reasoning for math and logic, with the ability to “think” more deeply when a prompt benefits from careful analysis.
Large language models (LLM) in natural language processing (NLP) have demonstrated great potential for in-context learning (ICL) — the ability to leverage a few sets of example prompts to adapt to various tasks without having to explicitly update the model weights. ICL has recently been explored for computer vision tasks with promising early outcomes. These …
Read more “Stable Diffusion Models are Secretly Good at Visual In-Context Learning”