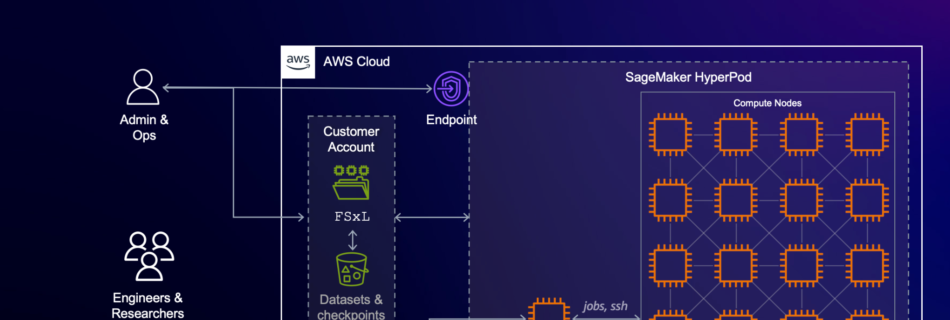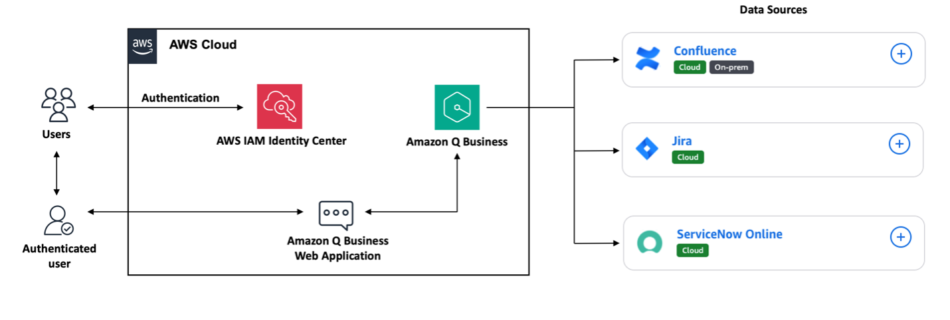
Build a generative AI enabled virtual IT troubleshooting assistant using Amazon Q Business
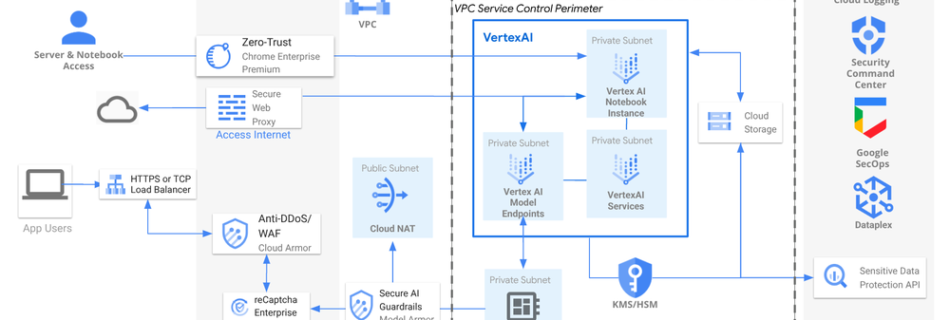
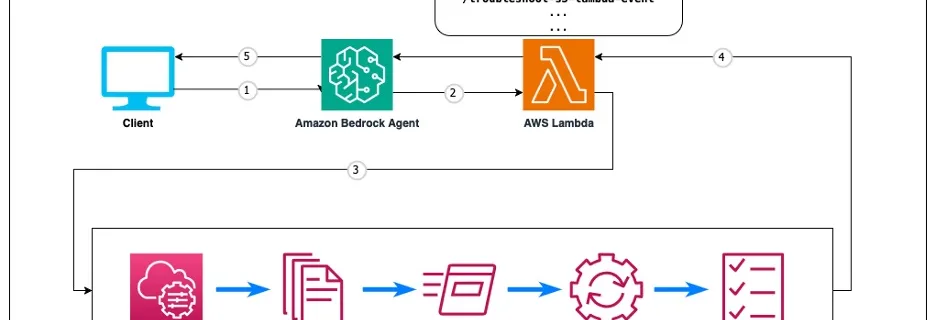
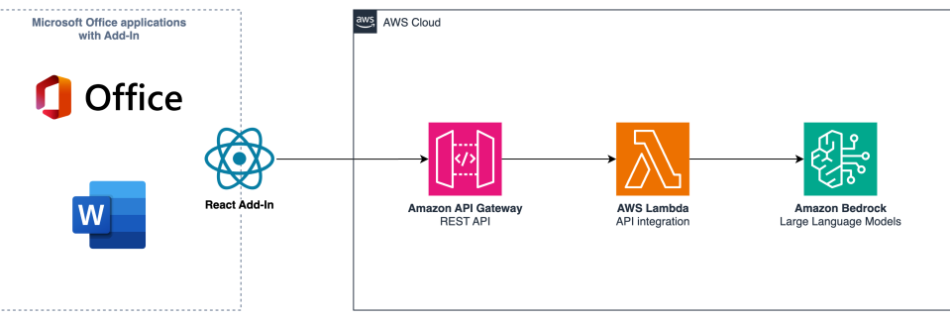
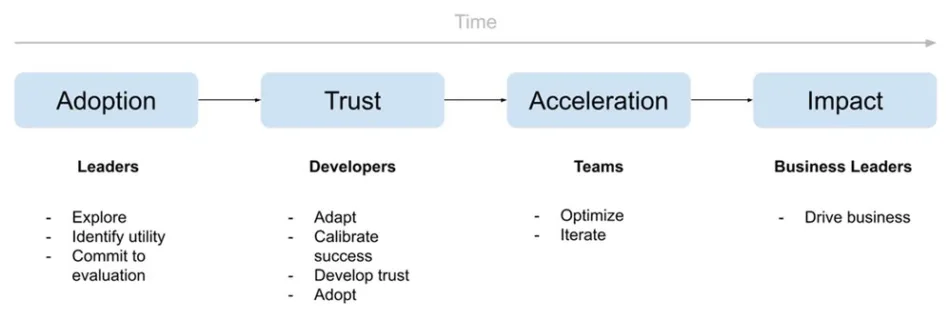
Today’s organizations face a critical challenge with the fragmentation of vital information across multiple environments. As businesses increasingly rely on diverse project management and IT service management (ITSM) tools such as ServiceNow, Atlassian Jira and Confluence, employees find themselves navigating a complex web of systems to access crucial data. This isolated approach leads to several …