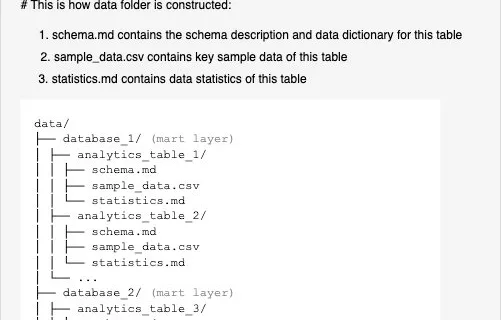
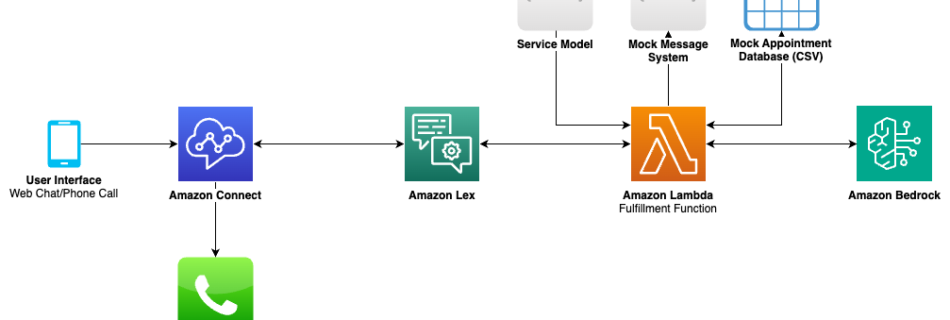
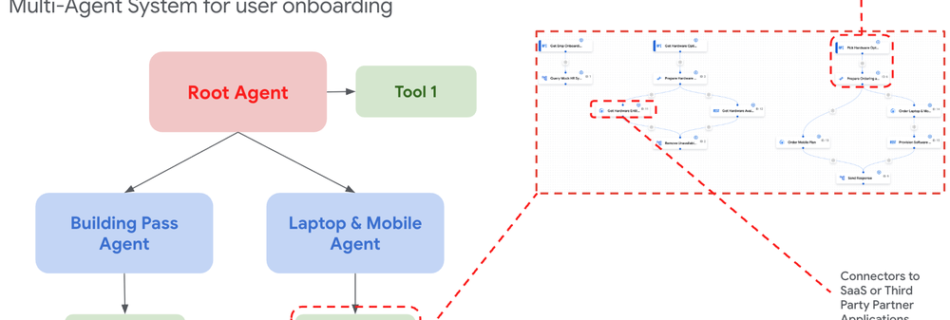
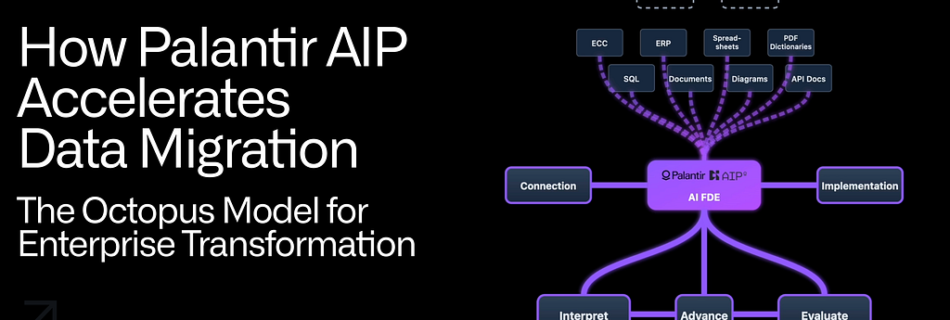
A Reinforcement Learning Based Universal Sequence Design for Polar Codes
To advance Polar code design for 6G applications, we develop a reinforcement learning-based universal sequence design framework that is extensible and adaptable to diverse channel conditions and decoding strategies. Crucially, our method scales to code lengths up to 2048, making it suitable for use in standardization. Across all (N,K)(N, K)(N,K) configurations supported in 5G, our …
Read more “A Reinforcement Learning Based Universal Sequence Design for Polar Codes”