Today, ML-driven innovation is fundamentally transforming computing, enabling entirely new classes of internet services. For example, recent state-of-the-art lage models such as PaLM and Chinchilla herald a coming paradigm shift where ML services will augment human creativity. All indications are that we are still in the early stages of what will be the next qualitative step function in computing. Realizing this transformation will require democratized and affordable access through cloud computing where the best of compute, networking, storage, and ML can be brought to bear seamlessly on ever larger-scale problem domains.
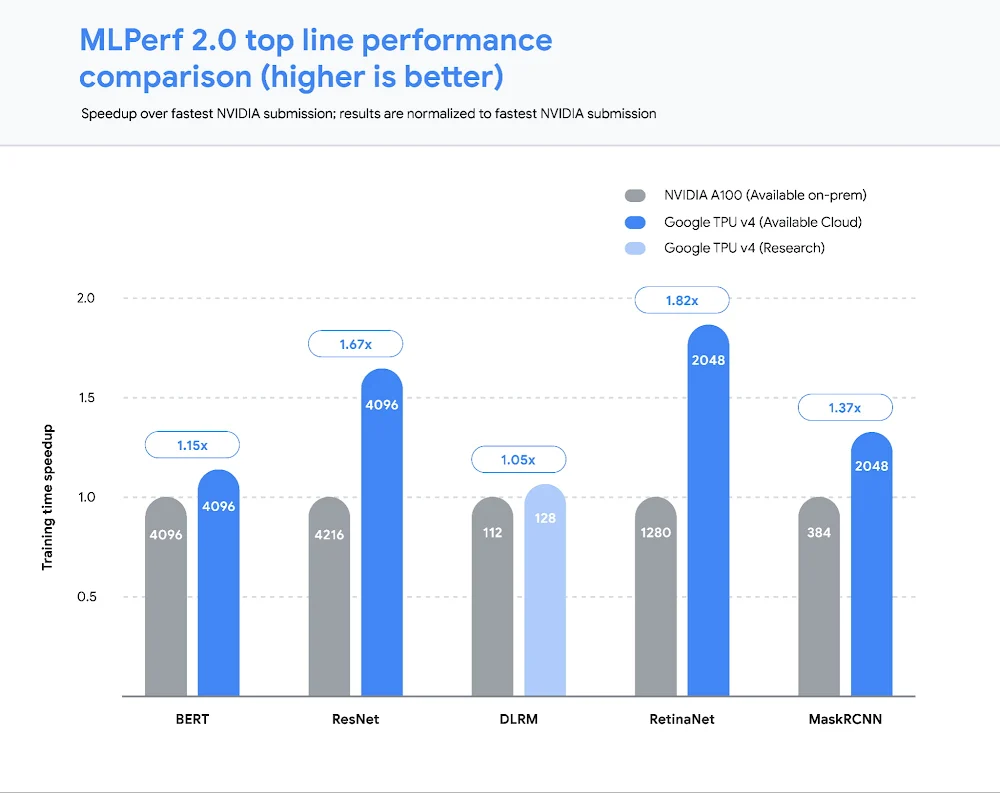
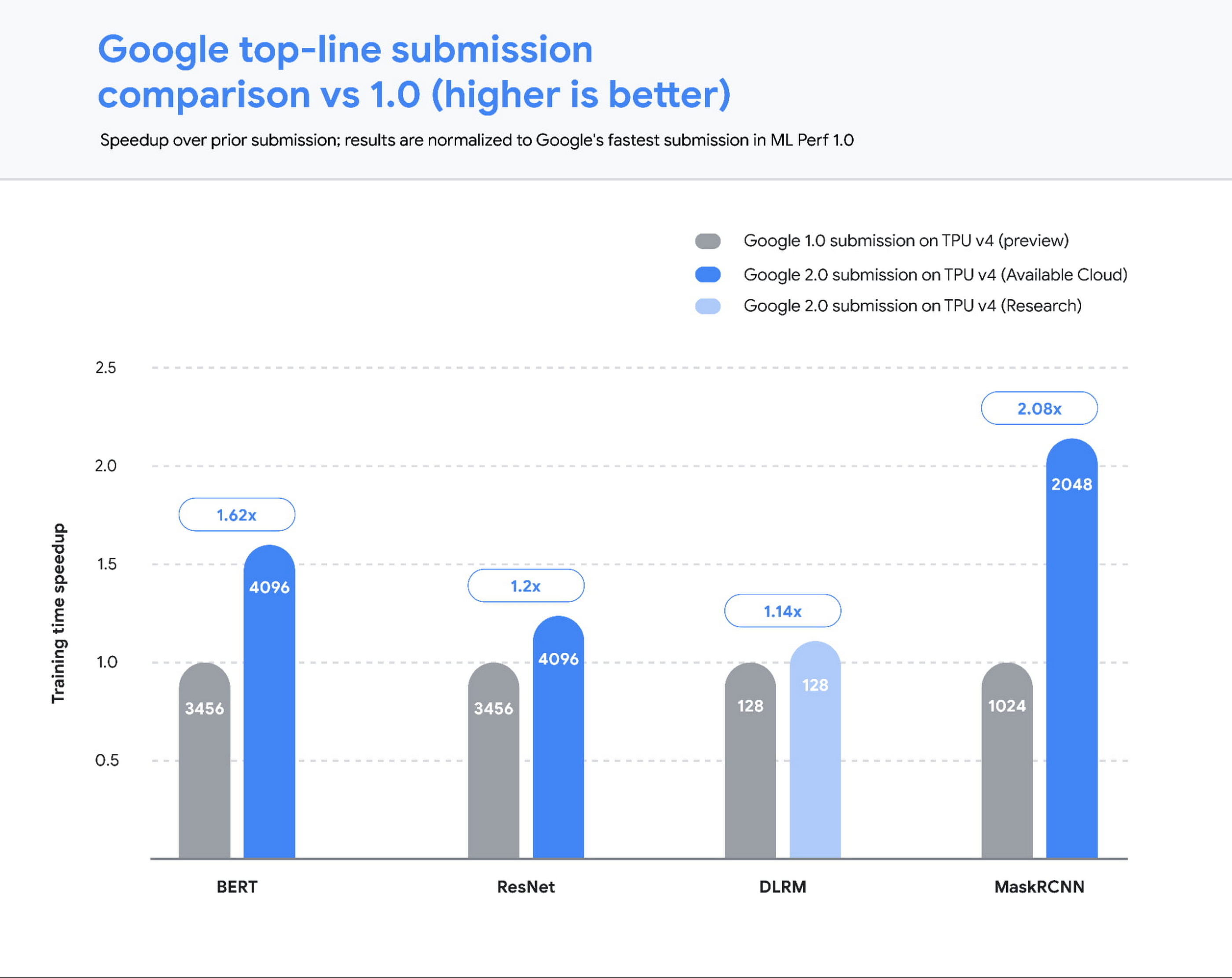
Today’s release of MLPerf™ 2.0 results from the MLCommons® Association highlights the public availability of the most powerful and efficient ML infrastructure anywhere. Google’s TPU v4 ML supercomputers set performance records on five benchmarks, with an average speedup of 1.42x over the next fastest non-Google submission, and 1.5x vs our MLPerf 1.0 submission. Even more compelling — four of these record runs were conducted on the publicly available Google Cloud ML hub that we announced at Google I/O. ML Hub runs out of our Oklahoma data center, which uses over 90% carbon-free energy.
Let’s take a closer look at the results.
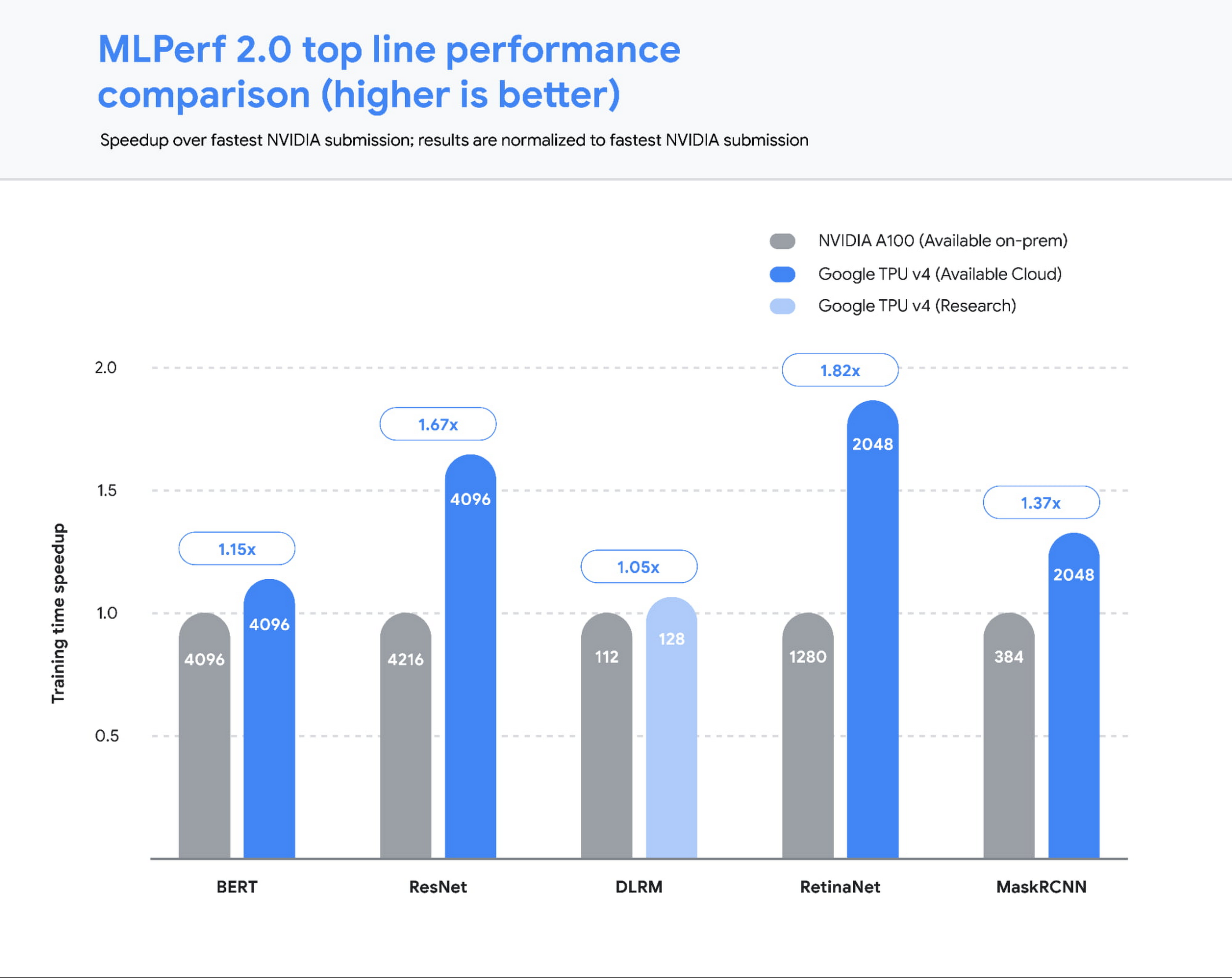
Performance at scale…and in the public cloud
Our 2.0 submissions1, all running on TensorFlow, demonstrated leading performance across all five benchmarks. We scaled two of our submissions to run on full TPU v4 Pods. Each Cloud TPU v4 Pod consists of 4096 chips connected together via an ultra-fast interconnect network with an industry-leading 6 terabits per second (Tbps) of bandwidth per host, enabling rapid training for the largest models.
Hardware aside, these benchmark results were made possible in no small part by our work to improve the TPU software stack. Scalability and performance optimizations in the TPU compiler and runtime, including faster embedding lookups and improved model weight distribution across the TPU pod, enabled much of these improvements, and are now widely available to TPU users. For example, we made a number of performance improvements to the virtualization stack to fully utilize the compute power of both CPU hosts and TPU chips to achieve peak performance on image and recommendation models. These optimizations reflect lessons from Google’s cutting-edge internal ML use cases across Search, YouTube, and more. We are excited to bring the benefits of this work to all Google Cloud users as well.
Translating MLPerf wins to customer wins
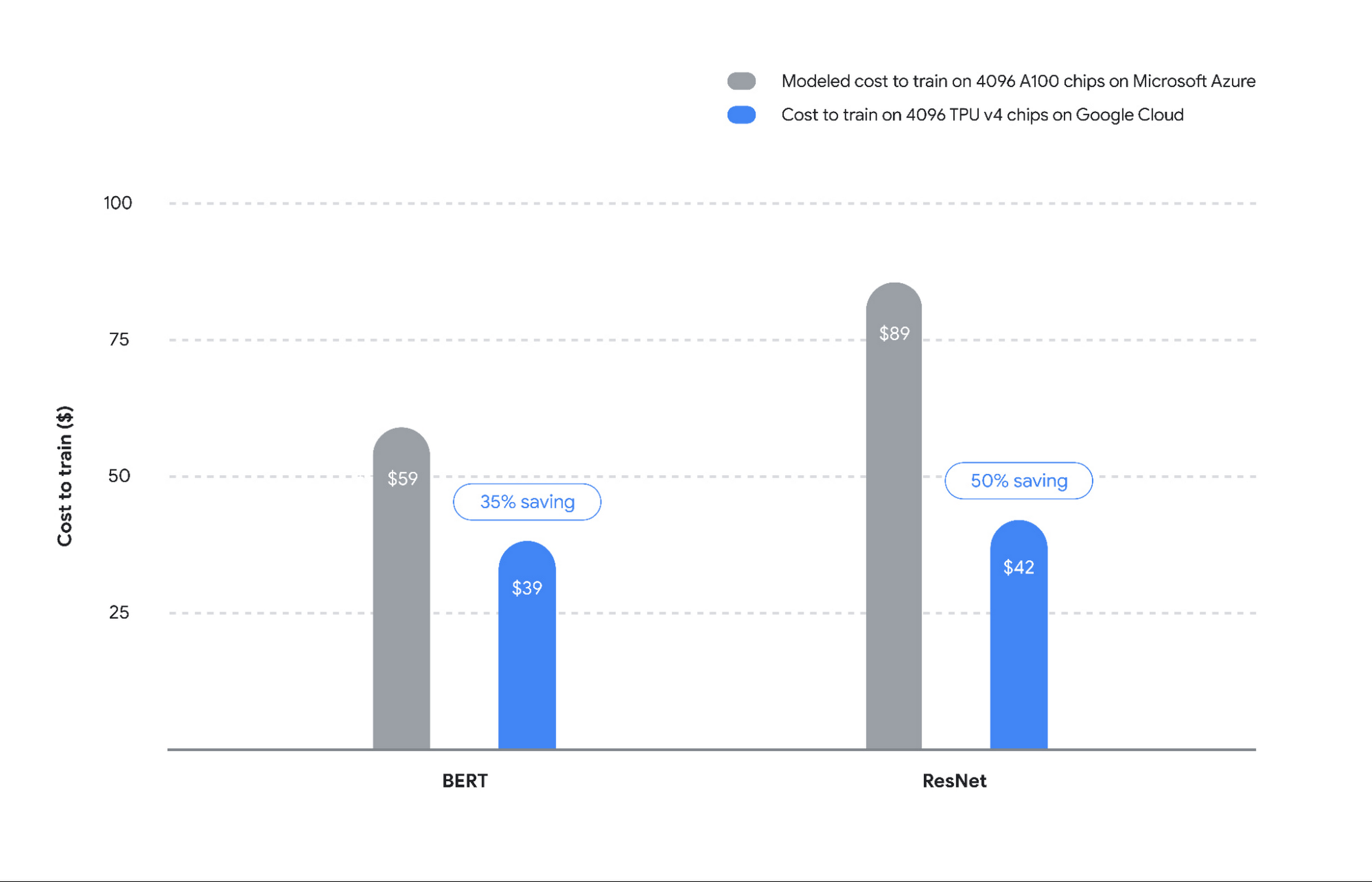
Cloud TPU’s industry-leading performance at scale also translates to cost savings for customers. Based on our analysis summarized in Figure 3, Cloud TPUs on Google Cloud provide ~35-50% savings vs A100 on Microsoft Azure (see Figure 3). We employed the following methodology to calculate this result:2
We compared the end-to-end times of the largest-scale MLPerf submissions, namely ResNet and BERT, from Google and NVIDIA. These submissions make use of a similar number of chips — upwards of 4000 TPU and GPU chips. Since performance does not scale linearly with chip count, we compared two submissions with roughly the same number of chips.
To simplify the 4216-chip A100 comparison for ResNet vs our 4096-chip TPU submission, we made an assumption in favor of GPUs that 4096 A100 chips would deliver the same performance as 4216 chips.
For pricing, we compared our publicly available Cloud TPU v4 on-demand prices ($3.22 per chip-hour) to Azure’s on-demand prices for A1003 ($4.1 per chip-hour). This once again favors the A100s since we assume zero virtualization overhead in moving from on-prem (NVIDIA’s results) to Azure Cloud.
The savings are especially meaningful given that real-world models such as GPT-3 and PaLM are much larger than the BERT and ResNet models used in the MLPerf benchmark: PaLM is a 540 billion parameter model, while the BERT model used in the MLPerf benchmark has only 340 million parameters — a 1000x difference in scale. Based on our experience, the benefits of TPUs will grow significantly with scale and make the case all the more compelling for training on Cloud TPU v4.
Have your cake and eat it too — a continued focus on sustainability
Performance at scale must take environmental concerns as a primary constraint and optimization target. The Cloud TPU v4 pods powering our MLPerf results run with 90% carbon-free energy and a Power Usage Efficiency of 1.10, meaning that less than 10% of the power delivered to the data center is lost through conversion, heat, or other sources of inefficiency. The TPU v4 chip delivers 3x the peak FLOPs per watt relative to the v3 generation. This combination of carbon-free energy and extraordinary power delivery and computation efficiency makes Cloud TPUs among the most efficient in the world.4
Making the switch to Cloud TPUs
There has never been a better time for customers to adopt Cloud TPUs. Significant performance and cost savings at scale as well as a deep-rooted focus on sustainability are why customers such as Cohere, LG AI Research, Innersight Labs, and Allen Institute have made the switch. If you are ready to begin using Cloud TPUs for your workloads, please fill out this form. We are excited to partner with ML practitioners around the world to further accelerate the incredible rate of ML breakthroughs and innovation with Google Cloud’s TPU offerings.
- 1 Innersight Labs.jpg
- 2 Allen Institute.jpg
- 3 Cohere.jpg
- 4 LG AI Research.jpg
1. MLPerf™ v2.0 Training Closed. Retrieved from https://mlcommons.org/en/training-normal-20/ 29 June 2022, results 2.0-2010, 2.0-2012, 2.0-2098, 2.0-2099, 2.0-2103, 2.0-2106, 2.0-2107, 2.0-2120. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
2. MLPerf v1.0 and v2.0 Training Closed. Retrieved from https://mlcommons.org/en/training-normal-20/ 29 June 2022, results 1.0-1088, 1.0-1090, 1.0-1092, 2.0-2010, 2.0-2012, 2.0-2120.
3. ND96amsr A100 v4 Azure VMs, powered by eight 80 GB NVIDIA Ampere A100 GPUs (Azure’s flagship Deep Learning and Tightly Coupled HPC GPU offering with CentOS or Ubuntu Linux) is used for this benchmarking
4. Cost to train is not an official MLPerf metric and is not verified by MLCommons Association. Azure performance is a favorable estimate as described in the text, not an MLPerf result. Computations are based on results from MLPerf v2.0 Training Closed. Retrieved from https://mlcommons.org/en/training-normal-20/ 29 June 2022, results 2.0-2012, 2.0-2106, 2.0-2107.