

Editor’s Note: This is the first post in a series exploring how Palantir customizes infrastructure software for reliable operation at scale. Written by the Foundations organization — which owns the foundational technologies backing all our software, including our storage infrastructure — this post details our experience tuning and customizing ES without forking the source code. We have two primary goals: to showcase the work our storage infrastructure teams do to ensure Palantir’s success, and to provide the Elastic community with discussion points for how these modifications might move into the mainline offering or how ES could become more customizable for power users.
Introduction
Underneath any scalable software offering at any business, there is a bedrock of infrastructure that is required for the rest of an ecosystem to function. At Palantir, the Foundations group operates in service to the Foundry, Apollo, Gotham, and AIP platforms to deliver such software at scale. Foundations broadly delivers both the infrastructure backing the building and delivery of other software (think CI, standardization of RPC, etc.), and the storage infrastructure software that can be used for persistence across the platform (think Cassandra, Oracle, Postgres, etc.). It is critical that this infrastructure operates reliably, as there may be cascading effects in the event of a failure at this layer.
Elasticsearch (ES), an open-source distributed search and indexing engine, is one of the technologies that Foundations is responsible for operating and delivering in the context of storage infrastructure. We operate somewhere in the ballpark of at least 300 ES clusters in a variety of environments, including containerized and non-containerized infrastructure, in air-gapped environments, and driving workflows across government and commercial spaces. The Elasticsearch API is powerful, but its flexibility allows engineers to build clients of ES, or clients-of-clients-of-ES, that can interact with the ES API in ways that threaten the platform’s stability. The experience we have had from dealing with such behavioral degradations in the field, and the inability to predict when a new call chain in the service mesh would result in repeating them, motivates us to customize Elasticsearch to make it more defensive accordingly.
When someone mentions the term “defensive programming” in software engineering, perhaps you think of adding more nullability checks, writing SQL-based code that defends against injection attacks, or implementing telemetry so operators can detect anomalous behavior as it occurs and act to prevent an impending outage. All these examples are fair — but what if the application that needs to be more defensive or observable is not authored by your organization?
Palantir holds a high bar for the resilience of its software across the whole stack. Most servers across the platform support mechanisms like attribution and rate-limiting to guard themselves from bad access patterns, as well as detailed telemetry that pipes into our alerting and visualizations infrastructure. We hold the same high bar of resilience for software that we do not author, as far as our capabilities allow.
In this blog post, we share an example of rewriting poorly chosen indexing refresh policies to demonstrate how we accomplished such increased defensiveness in ES via plugins without needing to fork the Elasticsearch source code. We share this example with the hope that some version of this capability could exist in the open-source Elasticsearch project, as well as to share the nature of the work we do in our Foundations Storage Infrastructure development teams at Palantir.
Elasticsearch at Palantir
To understand why we needed to make Elasticsearch more defensive, it’s important to understand how ES fits into Palantir’s architecture and the challenges this creates.
Some of the use cases that end up depending on ES include, but are not limited to:
- Quicksearch to find resources across an organization
- Geospatial analysis and operations in defense workflows
- Batch job orchestration
The Palantir platform is composed of microservices. A small set of these microservices serve as the database client services for the platform, where they expose database-like APIs that are backed by storage software. These services may put data into persistent storage, such as a relational database, and also provide searching capabilities by using Elasticsearch as a secondary index. Database clients may provide Elasticsearch-related parameters on their APIs, which are forwarded to Elasticsearch itself.

These database client services, in turn, may have any number of their own upstream services depending on them. The database clients are often designed with a flexible API to support a wide variety of workflows. It can be difficult to predict when a combination of user-created conditions and interactions between services in the mesh result in suboptimal usage of the ES API. A “bad access pattern” is any usage of an API that leads to degradation, either in the service providing that API (ES in this case) or in the service’s clients.
Furthermore, while the engineers who are operationally responsible for these databases may themselves have some ES expertise, the engineers managing upstream services likely have less due to their limited bandwidth and their specialization in other technologies.

At the lowest level, our storage infrastructure often presents the greatest challenges in terms of maintaining defensiveness and stability. Much of this software is open-source and not authored by us. ES is no exception to this — ES comes with its own opinions around telemetry (backed by Elastic APM) that are incompatible with our telemetry ecosystem, and ES doesn’t place guardrails around nuanced bad access patterns. Our storage infrastructure development teams provide novel solutions to meet our rigorous stability criteria when we see these gaps in such open-source software.
These teams also aim to collaborate with the open-source community. We begin by building these customizations internally in order to deliver our outcomes with high velocity. Ideally, in the long term, many of the improvements we make at this layer can be contributed back to the mainline code. We could also propose making the ES plugin frameworkmore powerful to support our customizations more easily. Where feasible, we aim to avoid forking software due to the cost of keeping such forks up to date with mainline code and to build more trust with the open-source community.
Case Study: Rewriting Poorly-Chosen Indexing Refresh Policies
At its core, Elasticsearch is built around storing (indexing) documents in an index such that the content of these documents may be efficiently searched. We will first cover how we made Elasticsearch resilient to bad access patterns in indexing.
Documents in Elasticsearch are stored in shards that partition the index such that parallel threads can run searches efficiently. A shard in Elasticsearch is persisted as a Lucene index, where each Lucene index is broken down further into segments. What is important to note is that while more segments allow for greater parallelism, tiny segments lead to inefficiency in both indexing and searching.
ES periodically processes batches of writes and converts them into optimally sized segments. To accomplish this, ES first buffers writes into two places:
- An on-disk, write-efficient store called a translog, where the data is persisted, so the write will stick even if the node goes down
- An in-memory indexing buffer, so that conversion into segments does not require reading from the on-disk translog
However, at this point, the data is not yet searchable. Data is periodically transferred from the in-memory indexing buffer into segments to be made visible for search via an operation that ES calls a refresh. The period at which the index will be refreshed in the background is known as the refresh interval, and may be configured via index settings.
Due to the delay in moving data into segments, data that is indexed may not immediately be available for search. ES is fundamentally built on an eventual consistency model. Nevertheless, indexing APIs may be parameterized by one of the following refresh policies that lead to the below post-conditions with regard to the searchability of newly-indexed data:
1. None(the default) – Only persist the data in the in-memory indexing buffer (and the translog) and return immediately. The written data is not guaranteed to be available for search following the write until the shard is next refreshed.

2. true(also called immediate in ES source) – Persist the write into the in-memory indexing buffer (and the translog), then synchronously force a refresh on shards that are modified by the indexing operation. This is typically not recommended outside of testing according to ES documentation, but we still see this being used in practice, primarily for UI-facing workflows (where immediate searchability following indexing is desired).

3. wait_for– Persist the data into the in-memory indexing buffer (and the translog), then register a callback that completes the client API call only when ES has refreshed the index in the background. This guarantees a post-condition that the write is visible in search at the point ES returns, at the cost of making the client wait for up to the configured refresh interval to complete the API call.

One important detail is that only one thread is allowed to run a refresh against a shard at a given time, the refresh code path is guarded by an exclusive lock.
With this background in mind, we can now consider the bad access patterns that are possible with regard to indexing with refresh policies, and that ES does not natively guard against.
Bad Access Pattern #1: Concurrent Synchronous Refresh
The ES documentation rightly explains that using the synchronous refresh code path is an antipattern. We will show that overuse of this option is more than just a cosmetic anti-pattern or a minor performance degradation.
Elasticsearch writes are constrained to running on threads from a fixed-size thread pool, meaning only a specific number of threads are available for writes at a time. Writes parameterized with the synchronous refresh option use the same writer thread from this pool for both the data persistence and the refresh operation. Recall that this refresh is completed under an exclusive lock. All these factors combined make the following scenario possible:
- Suppose shards (S0, S1.. Sn) are shards on a node
- Some shard Sk receives an outsize rate of index writes configured with synchronous refresh. (This is possible with hotspotting of writes to a shard, incorrectly-sharded indices, or indices that are small enough such that it is not worth sharding them in order to avoid the tiny shards anti-pattern)
- Therefore, any such writer thread must block on the refresh lock for Sk
- Consider an incoming write to any other shard S’ on the same node. The write to S’ cannot be allocated a thread because all threads are occupied on writes to Sk
- Result: The write thread pool for this node is exhausted, with all writes waiting for the refresh lock, and no other writes can make progress

Bad Access Pattern #2: wait_for with long refresh intervals
wait_for is a useful feature for avoiding a synchronous refresh that would lead to poorly constructed segments, not to mention avoiding the need to block the write on an exclusive lock. The downside is that the client needs to wait for the background refresh to complete before the API call returns.
Clients should be aware of the refresh interval set on an index, and thus should be able to use the wait_for option with predictable results. Nevertheless, in a complex engineering organization, such awareness of the interaction between the refresh interval and the write refresh policy cannot be taken for granted. The service setting the refresh interval on an index may not be the same service deciding on the refresh policy to use for writes to those indices. Or, someone may author a code change to adjust the refresh policy for index writes, without knowing prior context as to what the refresh interval on the index is set to in production, or latent code paths that may change the refresh interval.
When these scenarios occur, write API calls from one code path can grind to a halt when the refresh interval is lengthened unexpectedly by another code path. If the refresh interval is changed to -1, the write API calls may block indefinitely.
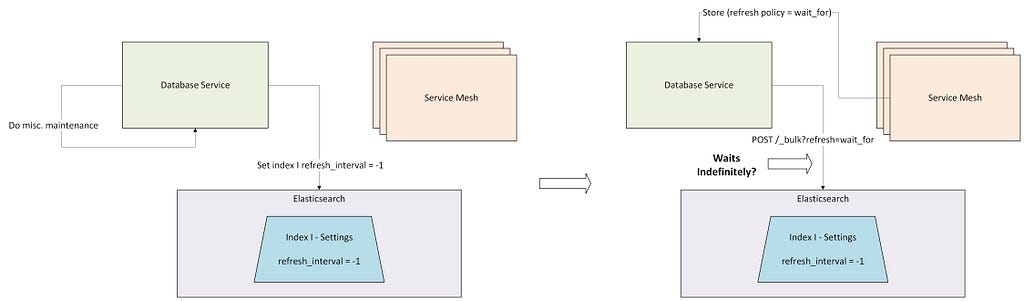
Solution: Change Bad Refresh Policies in a TransportInterceptor
Desired Behavior
It is possible in the short term to patch the code paths through the ES clients to stop these ES API interactions from occurring. However, we do not think this provides sufficient defense in depth. The service mesh must quickly evolve, and new usages of these access patterns are possible at any time.
Here’s the key point: We wanted to build stricter opinions in the storage layer (ES) itself, even if it means changing the behavior of the ES API from underneath the clients. We deemed it worthwhile to accept functionality tradeoffs in exchange for keeping our mission-critical workflows as stable as possible.
Nevertheless, we also don’t want to disable valid usage of immediate and wait_for refresh policies in the near term. If we enforced a ban on these options by always raising an error, the consequences for existing clients would be unpredictable and likely far-reaching. The question then is: How can we guarantee that these options can be used safely?
We first adopted the following invariants that we then made our Elasticsearch installations enforce in order to mitigate the real-world impact of these bad index refresh access patterns:
- There should never be two concurrent attempts to synchronously refresh the same shard. “Immediate” refresh should be allowed, but we never want to contend for the refresh lock amongst multiple writer threads
- There should never be a wait_for refresh policy parameterized on a write that targets an index with a refresh interval that is set to longer than the default, or is set to -1. wait_for refresh is allowed, but its delay time must be bounded to at most 1 second
Therefore, the behavior we want in the end is:
- If we detect an incoming write to a shard parameterized with immediate refresh, and there already exists an in-flight write to the same shard, change the later write’s refresh policy to wait_for
- If we detect an incoming write to a shard parameterized with wait_for refresh (inclusive of any case where we decided to rewrite the refresh policy because of the previously mentioned step), and the refresh interval index setting is longer than the default, then rewrite the refresh policy for the write to this shard to none
It’s worth noting that in both of the above cases, we considered an alternative where we would raise an error instead of trying to change the refresh policy. We decided against this because we believed raising errors would create more instability in production, as workflows would be stopped entirely.
In any situation where the refresh policy is changed, we also emit telemetry to alert us that this is taking place. We would then instruct users of the ES API to change the configured refresh policies on relevant code paths.
Choosing The Plugin Point
We wanted to make these invariants true in Elasticsearch, but we didn’t want to fork the codebase. Therefore, we looked into plugin APIs that would allow us to customize this behavior. The core code of the ES server is relatively small, and most of the ES logic is loaded into plugins or modules. Plugins are effectively “externally-authored” modules, and ES scans its install folder tree to discover plugins and modules to load and bind in-memory. We create our own plugins and ship them with every Elasticsearch installation that we deploy across the fleet.
We had to pick the correct place to add our refresh-rewriting logic. Determining the right ES plugin API to use requires a detailed understanding of the code paths that are called when indexing into ES. A call to the /_bulk endpoint follows this (simplified) control flow:
- The coordinator node receives the request from the client to write a batch of data
- The coordinator node converts this into an ES task that is backed by an ES action. (ES tasks are logical units of work, and actions are the code that implement tasks. At this stage, the TransportBulkAction is the action that is called on the coordinator node)
- [Plugin Point] Before actually entering the action code, zero or more ActionFilters are called that may decorate the execution of the resulting action
- The writes are partitioned to the primary shards, then fanned out to the data nodes holding those shards
- The data nodes receive the request to write to the shard
- [Plugin Point] TransportInterceptors are notified that the node has received a request to perform the write
- The data node creates a task to complete the write on the shard and executes the write on a thread from the write thread pool
- [Plugin Point] Each write proceeds through registered IndexingOperationListeners with minimal parameters
- Then the write actually persists, along with any post-write refresh actions (wait_for or immediate refresh) that need to happen
- If the shard is replicated, the data node propagates writes to replicas. Data nodes holding replica shards repeat 6–9 locally, then propagate the successes / failures back to the primary shard node
- A callback propagates the write completion event back through the coordinator node and eventually out to the client

Steps (3), (6), and (8) are the places where we may hook in via a plugin. We settled on a TransportInterceptor in the end, by process of elimination:
- We cannot use an ActionFilter because we need the detection of concurrent sync-refresh writes to be checked on the data node, but ActionFilters are not invoked on the data node that persists the data on this code path
- We cannot use an IndexingOperationListener because this API doesn’t give us a handle on the write request to change the refresh policy
Algorithm
Thus, our TransportInterceptor implementation may be broken down as follows:
- The interceptor maintains a data structure tracking “shard IDs currently under sync-refresh”
- Upon receiving a shard-level bulk write, check the refresh policy
- If the refresh policy is immediate, see if there’s an outstanding write with the immediate refresh policy on that shard by seeing if the shard is in the data structure from (1). If there is, change the refresh policy to wait_for. If there is not, then begin tracking this outstanding write in the data structure from (1), and remove it from the tracked set after the write completes via a callback
- If the refresh policy is wait_for (possibly from step (3) above), then look up the refresh interval index setting. If the refresh interval is -1 or longer than the default, change the refresh policy to none
As mentioned earlier, any changes to the refresh policy are tracked in our telemetry and are flagged to ES client engineering teams to be reconsidered.

Evaluation
The advantages of the above extension of ES are that now, in any situation, ES is hardened against bad uses of index refresh. This does not mean that we shouldn’t make an effort to improve ES usage to avoid choosing these index refresh policies poorly in the first place. Our telemetry raises the anomalies to us so that we can follow up with ES client engineering teams to improve their ES usage. We would ideally like to move towards only using none as the refresh policy, and making ES clients expect eventual consistency to be the norm.
The tradeoff has some drawbacks:
- TransportInterceptors are provided by extending the deprecated, ES-internal, NetworkPlugin. This plugin may change at any time, and we will need to adapt following an ES version upgrade whenever this breaks.
- As mentioned earlier, we are subtly changing the API semantics of ES from underneath the client. For example, clients reliant on post-write consistency for correctness may handle the rewrite on the backend incorrectly. Moreover, we don’t provide any signal to the client directly that this has occurred. The telemetry we put in place to detect these rewrites is an effort to mitigate this risk.
- We have to ensure the behavior remains correct through ES version upgrades, where the underlying ES code for handling writes and refreshes may evolve over time. We wrote extensive tests using the ES test framework, which is typically meant to be used for Elasticsearch’s own tests, but which is useful for us as we verify our logic at the lower levels of ES. Such tests should catch regressions as we progress through ES upgrades.
Up Next: Expensive Queries
We have shown why it’s important for Palantir to build additional resilience into Elasticsearch to future-proof ES usage against poor access patterns. We demonstrated a novel solution that we constructed by using a TransportInterceptor to monitor and defend against poor choices of indexing refresh policies. Our databases are the core of our workflows, and defensiveness is key to keeping our systems available for mission-critical users at all costs.
In the next blog post in this series, we will discuss how we mitigate the impact of poorly constructed queries in ES.
![]()
Defensive Databases: Optimizing Index-Refresh Semantics was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.