In this post, we introduce a new analysis in the Data Quality and Insights Report of Amazon SageMaker Data Wrangler. This analysis assists you in validating textual features for correctness and uncovering invalid rows for repair or omission.
Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes. You can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization, from a single visual interface.
Solution overview
Data preprocessing often involves cleaning textual data such as email addresses, phone numbers, and product names. This data can have underlying integrity constraints that may be described by regular expressions. For example, to be considered valid, a local phone number may need to follow a pattern like [1-9][0-9]{2}-[0-9]{4}, which would match a non-zero digit, followed by two more digits, followed by a dash, followed by four more digits.
Common scenarios resulting in invalid data may include inconsistent human entry, for example phone numbers in various formats (5551234 vs. 555 1234 vs. 555-1234) or unexpected data, such as 0, 911, or 411. For a customer call center, it’s important to omit numbers such as 0, 911, or 411, and validate (and potentially correct) entries such as 5551234 or 555 1234.
Unfortunately, although textual constraints exist, they may not be provided with the data. Therefore, a data scientist preparing a dataset must manually uncover the constraints by looking at the data. This can be tedious, error prone, and time consuming.
Pattern learning automatically analyzes your data and surfaces textual constraints that may apply to your dataset. For the example with phone numbers, pattern learning can analyze the data and identify that the vast majority of phone numbers follow the textual constraint [1-9][0-9]{2}-[0-9][4]. It can also alert you that there are examples of invalid data so that you can exclude or correct them.
In the following sections, we demonstrate how to use pattern learning in Data Wrangler using a fictional dataset of product categories and SKU (stock keeping unit) codes.
This dataset contains features that describe products by company, brand, and energy consumption. Notably, it includes a feature SKU that is ill-formatted. All the data in this dataset is fictional and created randomly using random brand names and appliance names.
Prerequisites
Before you get started using Data Wrangler, download the sample dataset and upload it to a location in Amazon Simple Storage Service (Amazon S3). For instructions, refer to Uploading objects.
Import your dataset
To import your dataset, complete the following steps:
- In Data Wrangler, choose Import & Explore Data for ML.

- Choose Import.

- For Import data, choose Amazon S3.

- Locate the file in Amazon S3 and choose Import.




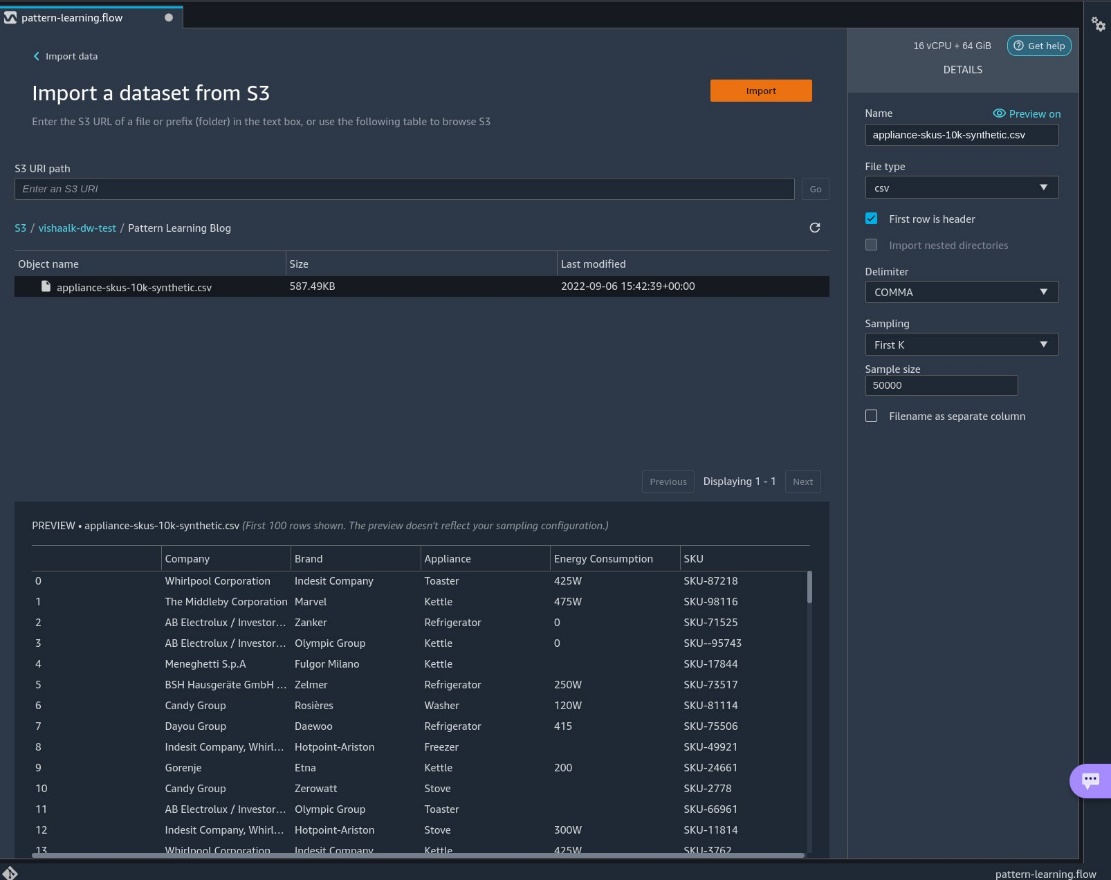
After importing, we can navigate to the data flow.
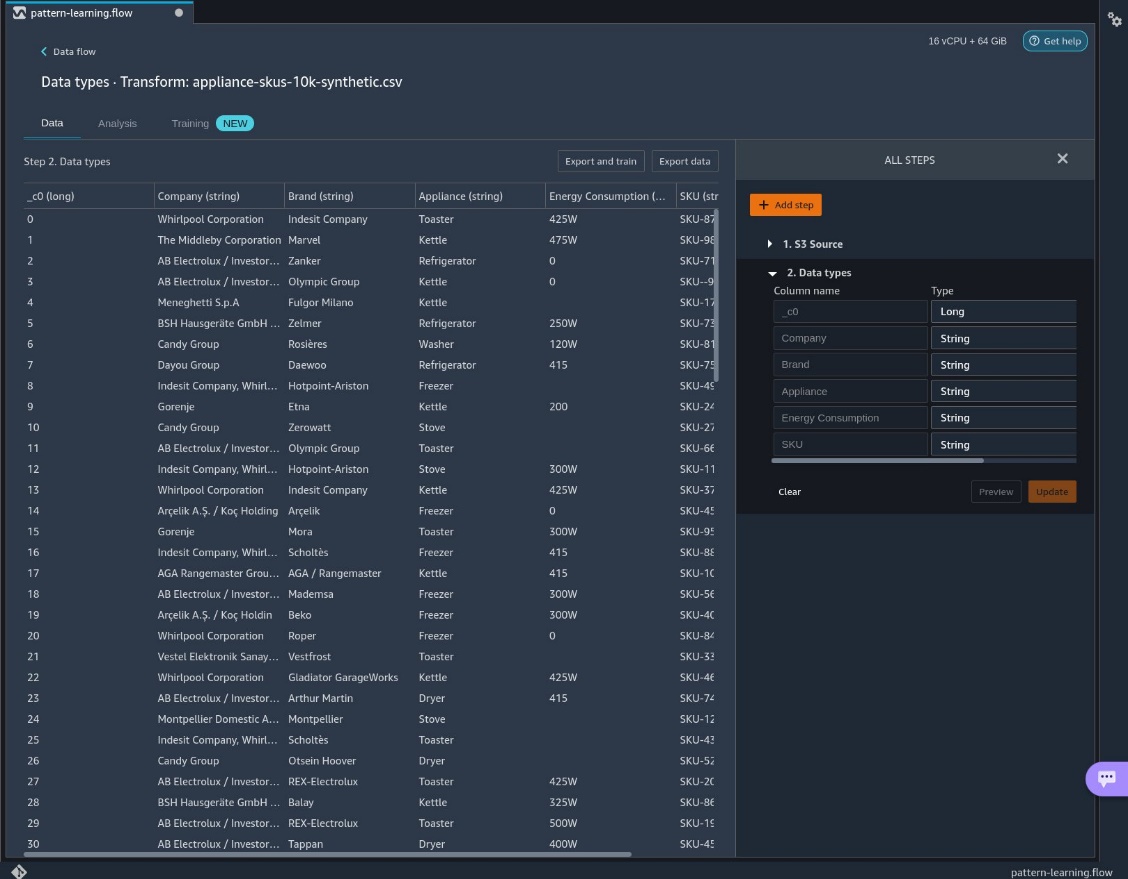
Get data insights
In this step, we create a data insights report that includes information about data quality. For more information, refer to Get Insights On Data and Data Quality. Complete the following steps:
- On the Data Flow tab, choose the plus sign next to Data types.
- Choose Get data insights.

- For Analysis type, choose Data Quality and Insights Report.
- For this post, leave Target column and Problem type blank.If you plan to use your dataset for a regression or classification task with a target feature, you can select those options and the report will include analysis on how your input features relate to your target. For example, it can produce reports on target leakage. For more information, refer to Target column.
- Choose Create.



We now have a Data Quality and Data Insights Report. If we scroll down to the SKU section, we can see an example of pattern learning describing the SKU. This feature appears to have some invalid data, and actionable remediation is required.

Before we clean the SKU feature, let’s scroll up to the Brand section to see some more insights. Here we see two patterns have been uncovered, indicating that that majority of brand names are single words consisting of word characters or alphabetic characters. A word character is either an underscore or a character that may appear in a word in any language. For example, the strings Hello_world and écoute both consist of word characters: H and é.
For this post, we don’t clean this feature.
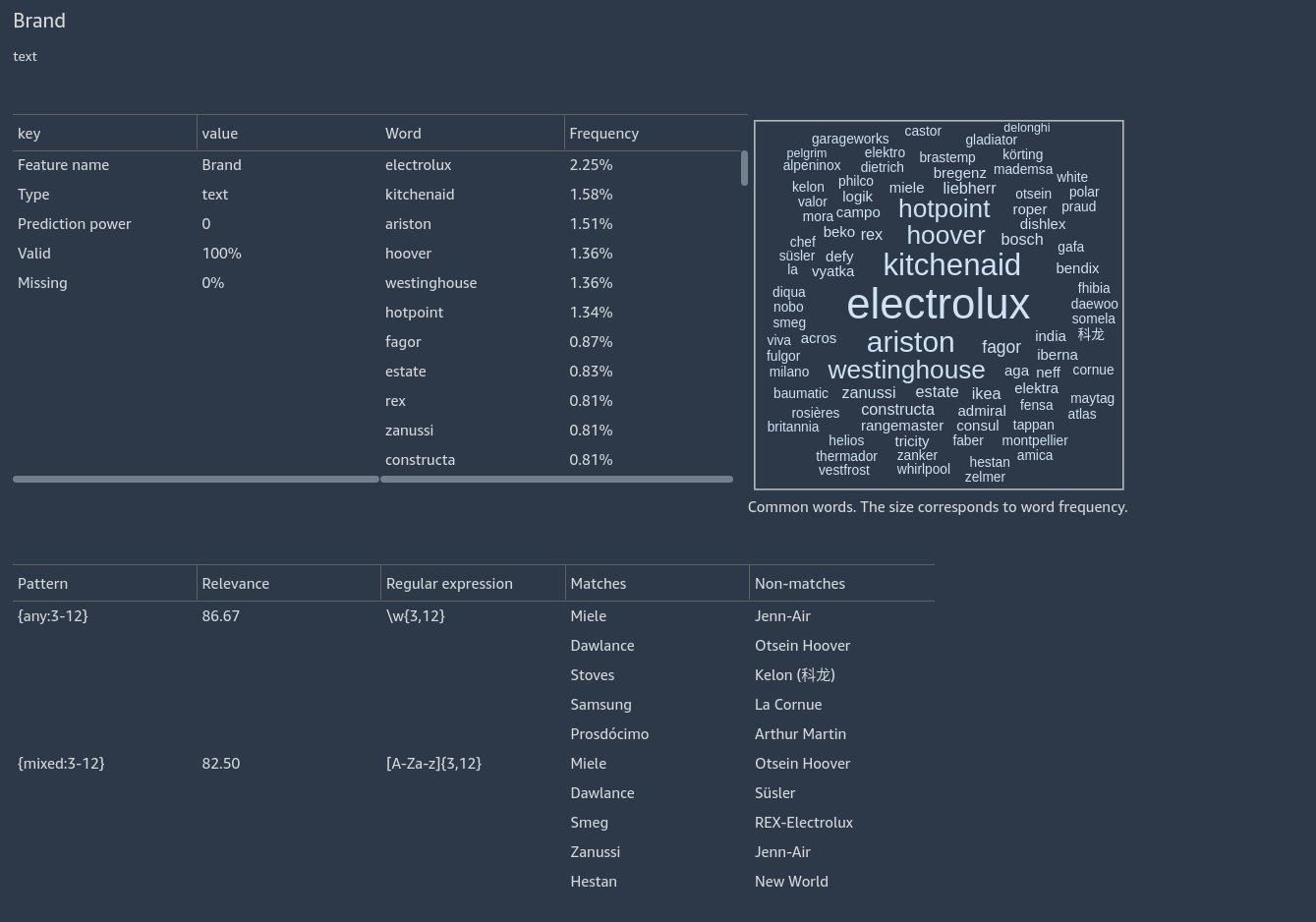
View pattern learning insights
Let’s return to cleaning SKUs and zoom in on the pattern and the warning message.
As shown in the following screenshot, pattern learning surfaces a high-accuracy pattern matching 97.78% of the data. It also displays some examples matching the pattern as well as examples that don’t match the pattern. In the non-matches, we see some invalid SKUs.
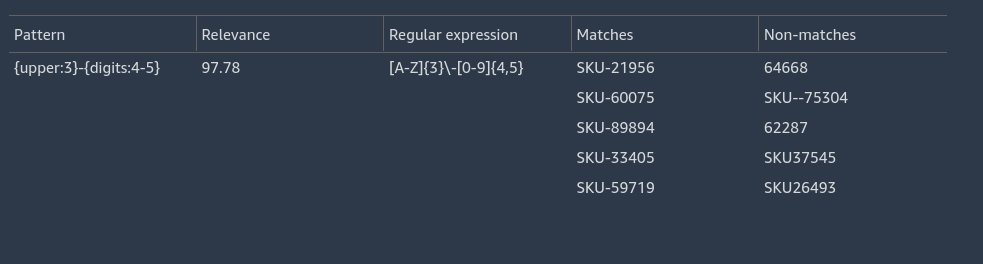
In addition to the surfaced patterns, a warning may appear indicating a potential action to clean up data if there is a high accuracy pattern as well as some data that doesn’t conform to the pattern.

We can omit the invalid data. If we choose (right-click) on the regular expression, we can copy the expression [A-Z]{3}-[0-9]{4,5}.
Remove invalid data
Let’s create a transform to omit non-conforming data that doesn’t match this pattern.
- On the Data Flow tab, choose the plus sign next to Data types.
- Choose Add transform.

- Choose Add step.
- Search for
regexand choose Search and edit.

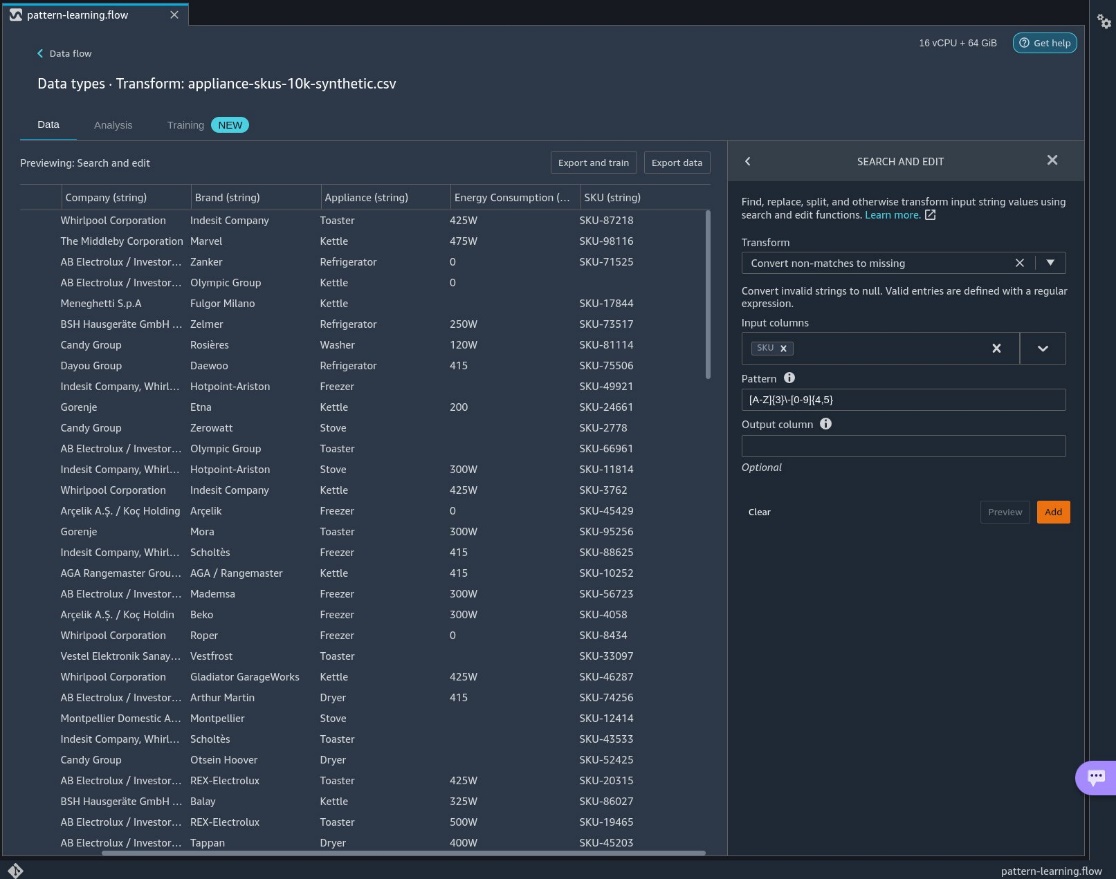
- For Transform, choose Convert non-matches to missing.
- For Input columns, choose
SKU. - For Pattern, enter our regular expression.
- Choose Preview, then choose Add.
Now the extraneous data has been removed from the features. - To remove the rows, add the step Handle missing and choose the transform Drop missing.
- Choose
SKUas the input column.



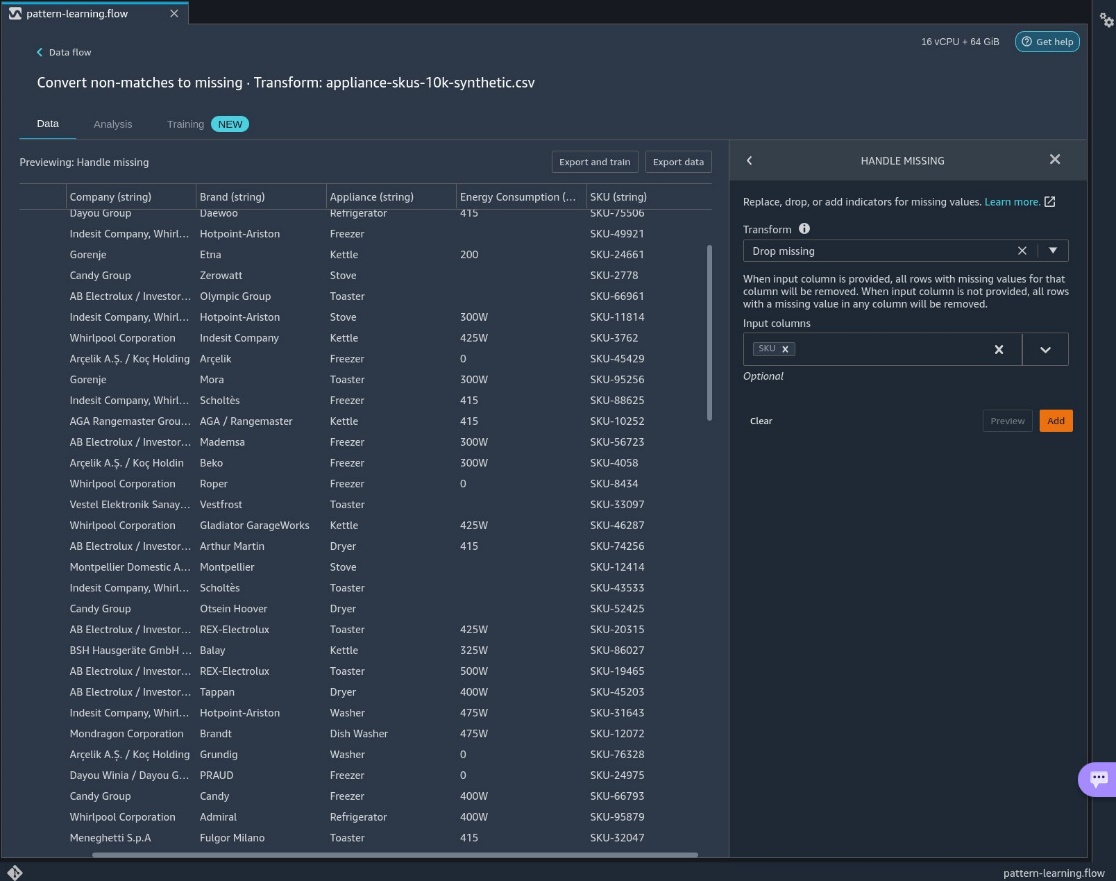
We return to our data flow with the erroneous data removed.

Conclusion
In this post, we showed you how to use the pattern learning feature in data insights to find invalid textual data in your dataset, as well as how to correct or omit that data.
Now that you’ve cleaned up a textual column, you can visualize your dataset using an analysis or you can apply built-in transformations to further process your data. When you’re satisfied with your data, you can train a model with Amazon SageMaker Autopilot, or export your data to a data source such as Amazon S3.
We would like to thank Nikita Ivkin for his thoughtful review.
About the authors
 Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.
Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.
 Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the areas of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
Zohar Karnin is a Principal Scientist in Amazon AI. His research interests are in the areas of large scale and online machine learning algorithms. He develops infinitely scalable machine learning algorithms for Amazon SageMaker.
 Ajai Sharma is a Principal Product Manager for Amazon SageMaker where he focuses on Data Wrangler, a visual data preparation tool for data scientists. Prior to AWS, Ajai was a Data Science Expert at McKinsey and Company, where he led ML-focused engagements for leading finance and insurance firms worldwide. Ajai is passionate about data science and loves to explore the latest algorithms and machine learning techniques.
Ajai Sharma is a Principal Product Manager for Amazon SageMaker where he focuses on Data Wrangler, a visual data preparation tool for data scientists. Prior to AWS, Ajai was a Data Science Expert at McKinsey and Company, where he led ML-focused engagements for leading finance and insurance firms worldwide. Ajai is passionate about data science and loves to explore the latest algorithms and machine learning techniques.
 Derek Baron is a software development manager for Amazon SageMaker Data Wrangler
Derek Baron is a software development manager for Amazon SageMaker Data Wrangler