Large language models (LLMs) give developers immense power and scalability, but managing resource consumption is key to delivering a smooth user experience. LLMs demand significant computational resources, which means it’s essential to anticipate and handle potential resource exhaustion. If not, you might encounter 429 “resource exhaustion” errors, which can disrupt how users interact with your AI application.
Today, we’ll delve into why 429 errors occur with LLMs and equip you with three practical strategies to address them effectively. By understanding the root causes and implementing the right solutions, you can help ensure a smooth and uninterrupted experience, even during times of peak demand.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x3e280c56b370>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/vertex-ai/’), (‘image’, None)])]>
Backoff!
Exponential backoff and retry logic have been around for a number of years. These basic techniques for handling resource exhaustion or API unavailability also apply to LLMs. When a generative AI application’s calls floods a model’s API, or when an excessive amount of queries overloads a system, backoff and retry logic in the code can help. The waiting time increases exponentially with each retry until the overloaded system recovers.
In Python, there are decorators available to implement backoff logic in your application code. For example, tenacity is a useful general-purpose retrying library written in Python to simplify the task of adding retry behavior to your code. 429 errors are more likely to occur with asynchronous code and multimodal models such as Gemini with large context windows. Below is a sample of an asynchronous code for retry using tenacity. To view the entire notebook, please visit this link.
- code_block
- <ListValue: [StructValue([(‘code’, ‘from tenacity import retry, wait_random_exponentialrnrnasync def async_ask_gemini(contents, model_name=DEFAUL_MODEL_NAME):rn # This basic function calls Gemini asynchronously without a retry logicrn multimodal_model = GenerativeModel(model_name)rn response = await multimodal_model.generate_content_async(rn contents=contents, generation_config=config)rn return response.textrnrnrn@retry(wait=wait_random_exponential(multiplier=1, max=60))rnasync def retry_async_ask_gemini(contents, model_name=DEFAUL_MODEL_NAME):rn “””This is the same code as the async_ask_gemini function but implements arn retry logic using tenacity decorator.rn wait_random_exponential(multiplier=1, max=60) means that it willrn Retry “Randomly wait up to 2^x * 1 seconds between each retry until the rn range reaches 60 seconds, then randomly up to 60 seconds afterwards.rn “””rn multimodal_model = GenerativeModel(model_name)rn response = await multimodal_model.generate_content_async(contents=contents, generation_config=config)rn return response.text’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e282ad63a00>)])]>
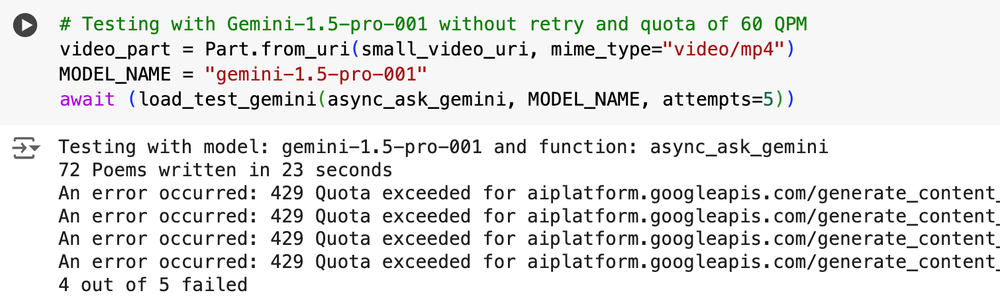
We tested passing a large amount of input to Gemini 1.5 Pro to demonstrate how backoff and retry is crucial to the success of your gen AI application. We’re using images and videos stored in Google Cloud Storage to heavily tax the Gemini system.
Below are the results without backoff and retry configured; where four out of five attempts failed.

Below are the results with backoff and retry configured. Implementing backoff and retry allowed all five attempts to succeed. Even with a successful API call and a response from the model, there is a trade-off. The backoff and retry adds increasing latency to a response. There may be other changes to make to the code, changes to the model, or a different cloud region that could improve performance. Nonetheless, backoff and retry is an overall improvement during moments of peak traffic and congestion.

Additionally, when working with LLMs, you may often encounter issues from the underlying APIs such as rate-limiting or downtime. As you move your LLM applications into production it becomes more and more important to safeguard against these. That’s why LangChain introduced the concept of a fallback, an alternative plan that may be used in an emergency. A fallback can be to a different model or even to another LLM provider altogether. Fallbacks can be implemented in code along with backoff and retry methods for greater resilience of your LLM applications.
Another robust option for LLM resiliency is circuit breaking with Apigee. By placing Apigee between a retrieval-augmented generation (RAG) application and LLM endpoints, you can manage traffic distribution and graceful failure handling. Of course, each model will provide a different answer so fallbacks and circuit breaking architecture should be thoroughly tested to ensure it meets your users needs.
Dynamic shared quota
Dynamic shared quota is one way that Google Cloud manages resource allocation for certain models, aiming to provide a more flexible and efficient user experience. Here’s how it works:
Traditional quota vs. dynamic shared quota
- Traditional quota: In a traditional quota system, you’re assigned a fixed limit for a specific resource (e.g., API requests per day, per minute, per region). If you need more capacity, you usually have to submit a quota increase request and wait for approval. This can be slow and inconvenient. Of course, simply having quota allocated does not guarantee capacity, as it is still on-demand and not dedicated capacity. We will talk more about dedicated capacity when we discuss Provisioned Throughput later in this blog.
- Dynamic shared quota: With dynamic shared quota, Google Cloud has a pool of available capacity for a service. This capacity is dynamically distributed among all users who are making requests. Instead of having a fixed individual limit, you draw from this shared pool based on your needs at any given moment.
Benefits of dynamic shared quota
- Eliminates quota increase requests: You no longer need to submit quota increase requests for services that use dynamic shared quota. The system automatically adjusts to your usage patterns.
- Improved efficiency: Resources are used more efficiently because the system can allocate capacity where it’s needed most at any given time.
- Reduced latency: By dynamically allocating resources, Google Cloud can minimize latency and provide faster responses to your requests.
- Simplified management: It simplifies capacity planning because you don’t have to worry about hitting fixed limits.
Dynamic shared quota in action
429 resource exhaustion errors are more likely to occur with asynchronous calls to Gemini with large multimodal input such as large video files. Below is a comparison of model performance of Gemini-1.5-pro-001 with traditional quota versus Gemini-1.5-pro-002 with dynamic shared quota. We can see even without retry (not recommended) the second-generation Gemini Pro model outperforms the previous-generation model because of dynamic shared quota.


Backoff and retry mechanisms should be combined with dynamic shared quota, especially as request volume and token size increase. During our testing of the -002 model with larger video input, we encountered 429 errors in all our initial attempts. However, the test results below demonstrate that incorporating backoff and retry logic allowed all five subsequent attempts to succeed. This highlights the necessity of this strategy for the newer -002 Gemini model to be consistently successful.


Dynamic shared quota represents a shift towards a more flexible and efficient way of managing resources in Google Cloud. By dynamically allocating capacity, it aims to provide a tightly integrated experience for users while optimizing resource utilization. Dynamic shared quota is not user-configurable. Google enables it only on specific models’ versions like Gemini-1.5-pro-002 and Gemini-1.5-flash-002. Check supported Google Model versions for more details.
Alternatively, there are times where you want a hard-stop threshold to prevent excessive API calls to Gemini. Abuse, budget limits and controls, or security reasons all play a factor in purposely setting a customer-defined quota in Vertex AI. This is where the feature of consumer quota override comes in. This can be a useful tool to protect your AI applications and systems. You can manage consumer quota with Terraform using the google_service_usage_consumer_quota_override schema.
Provisioned Throughput
Provisioned Throughput from Google Cloud is a service that allows you to reserve dedicated capacity for generative AI models on the Vertex AI platform. This means you can have predictable and reliable performance for your AI workloads, even during peak demand.
Here’s a breakdown of what it offers and why it’s useful:
Benefits:
- Predictable performance: You get consistent response times and avoid performance variability, helping your AI applications run smoothly.
- Reserved capacity: No more worrying about resource contention or queuing. You have your own dedicated capacity for your AI models. By default, when Provisioned Throughput capacity is surpassed, the excess traffic is billed at the pay-as-you-go rate.

- Cost-effective: It can be more cost-effective than pay-as-you-go pricing if you have consistent, high-volume AI workloads. To estimate if you can save money using Provisioned Throughput, follow steps one through ten in the order process.
- Scalable: You can easily scale your reserved capacity up or down as your needs change.
If you have an application with a large user base and need to provide fast response times then this is definitely going to help. This is designed especially for applications that require immediate AI processing, such as chatbots or interactive content generation. Provisioned Throughput can also help computationally-intensive AI tasks, such as processing massive datasets or generating complex outputs.
Leave 429s behind
When using generative AI in production, reliable performance is crucial. To achieve this, consider implementing these three strategies. They are designed to work together, and incorporating backoff and retry mechanisms into all your gen AI applications is a best practice. To get started building with generative AI, you can use these Vertex AI samples on GitHub or take advantage of the beginner’s guide, quickstarts, or starter pack Google Cloud offers.