Today, we are excited to announce general availability of batch inference for Amazon Bedrock. This new feature enables organizations to process large volumes of data when interacting with foundation models (FMs), addressing a critical need in various industries, including call center operations.
Call center transcript summarization has become an essential task for businesses seeking to extract valuable insights from customer interactions. As the volume of call data grows, traditional analysis methods struggle to keep pace, creating a demand for a scalable solution.
Batch inference presents itself as a compelling approach to tackle this challenge. By processing substantial volumes of text transcripts in batches, frequently using parallel processing techniques, this method offers benefits compared to real-time or on-demand processing approaches. It is particularly well suited for large-scale call center operations where instantaneous results are not always a requirement.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from data preparation to job submission and output analysis. We also explore best practices for optimizing your batch inference workflows on Amazon Bedrock, helping you maximize the value of your data across different use cases and industries.
Solution overview
The batch inference feature in Amazon Bedrock provides a scalable solution for processing large volumes of data across various domains. This fully managed feature allows organizations to submit batch jobs through a CreateModelInvocationJob API or on the Amazon Bedrock console, simplifying large-scale data processing tasks.
In this post, we demonstrate the capabilities of batch inference using call center transcript summarization as an example. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks. The general workflow for batch inference consists of three main phases:
- Data preparation – Prepare datasets as needed by the chosen model for optimal processing. To learn more about batch format requirements, see Format and upload your inference data.
- Batch job submission – Initiate and manage batch inference jobs through the Amazon Bedrock console or API.
- Output collection and analysis – Retrieve processed results and integrate them into existing workflows or analytics systems.
By walking through this specific implementation, we aim to showcase how you can adapt batch inference to suit various data processing needs, regardless of the data source or nature.
Prerequisites
To use the batch inference feature, make sure you have satisfied the following requirements:
- An active AWS account.
- An Amazon Simple Storage Service (Amazon S3) bucket where your data prepared for batch inference is stored. To learn more about uploading files in Amazon S3, see Uploading objects.
- Access to your selected models hosted on Amazon Bedrock. Refer to the supported models and their capabilities page for a complete list of supported models. Amazon Bedrock supports batch inference on the following modalities:
- Text to embeddings
- Text to text
- Text to image
- Image to images
- Image to embeddings
- An AWS Identity and Access Management (IAM) role for batch inference with a trust policy and Amazon S3 access (read access to the folder containing input data, and write access to the folder storing output data).
Prepare the data
Before you initiate a batch inference job for call center transcript summarization, it’s crucial to properly format and upload your data. The input data should be in JSONL format, with each line representing a single transcript for summarization.
Each line in your JSONL file should follow this structure:
Here, recordId is an 11-character alphanumeric string, working as a unique identifier for each entry. If you omit this field, the batch inference job will automatically add it in the output.
The format of the modelInput JSON object should match the body field for the model that you use in the InvokeModel request. For example, if you’re using Anthropic Claude 3 on Amazon Bedrock, you should use the MessageAPI and your model input might look like the following code:
When preparing your data, keep in mind the quotas for batch inference listed in the following table.
| Limit Name | Value | Adjustable Through Service Quotas? |
| Maximum number of batch jobs per account per model ID using a foundation model | 3 | Yes |
| Maximum number of batch jobs per account per model ID using a custom model | 3 | Yes |
| Maximum number of records per file | 50,000 | Yes |
| Maximum number of records per job | 50,000 | Yes |
| Minimum number of records per job | 1,000 | No |
| Maximum size per file | 200 MB | Yes |
| Maximum size for all files across job | 1 GB | Yes |
Make sure your input data adheres to these size limits and format requirements for optimal processing. If your dataset exceeds these limits, considering splitting it into multiple batch jobs.
Start the batch inference job
After you have prepared your batch inference data and stored it in Amazon S3, there are two primary methods to initiate a batch inference job: using the Amazon Bedrock console or API.
Run the batch inference job on the Amazon Bedrock console
Let’s first explore the step-by-step process of starting a batch inference job through the Amazon Bedrock console.
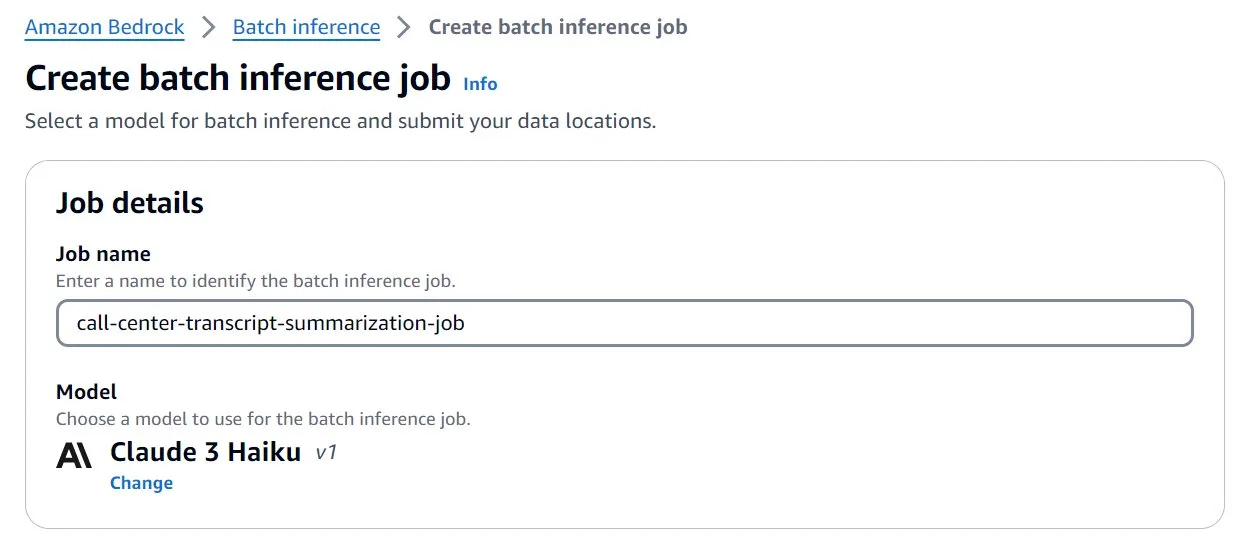
- On the Amazon Bedrock console, choose Inference in the navigation pane.
- Choose Batch inference and choose Create job.
- For Job name, enter a name for the training job, then choose an FM from the list. In this example, we choose Anthropic Claude-3 Haiku as the FM for our call center transcript summarization job.

- Under Input data, specify the S3 location for your prepared batch inference data.

- Under Output data, enter the S3 path for the bucket storing batch inference outputs.
- Your data is encrypted by default with an AWS managed key. If you want to use a different key, select Customize encryption settings.

- Under Service access, select a method to authorize Amazon Bedrock. You can select Use an existing service role if you have an access role with fine-grained IAM policies or select Create and use a new service role.
- Optionally, expand the Tags section to add tags for tracking.
- After you have added all the required configurations for your batch inference job, choose Create batch inference job.





You can check the status of your batch inference job by choosing the corresponding job name on the Amazon Bedrock console. When the job is complete, you can see more job information, including model name, job duration, status, and locations of input and output data.
Run the batch inference job using the API
Alternatively, you can initiate a batch inference job programmatically using the AWS SDK. Follow these steps:
- Create an Amazon Bedrock client:
- Configure the input and output data:
- Start the batch inference job:
- Retrieve and monitor the job status:
Replace the placeholders {bucket_name}, {input_prefix}, {output_prefix}, {account_id}, {role_name}, your-job-name, and model-of-your-choice with your actual values.
By using the AWS SDK, you can programmatically initiate and manage batch inference jobs, enabling seamless integration with your existing workflows and automation pipelines.
Collect and analyze the output
When your batch inference job is complete, Amazon Bedrock creates a dedicated folder in the specified S3 bucket, using the job ID as the folder name. This folder contains a summary of the batch inference job, along with the processed inference data in JSONL format.
You can access the processed output through two convenient methods: on the Amazon S3 console or programmatically using the AWS SDK.
Access the output on the Amazon S3 console
To use the Amazon S3 console, complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Navigate to the bucket you specified as the output destination for your batch inference job.
- Within the bucket, locate the folder with the batch inference job ID.
Inside this folder, you’ll find the processed data files, which you can browse or download as needed.
Access the output data using the AWS SDK
Alternatively, you can access the processed data programmatically using the AWS SDK. In the following code example, we show the output for the Anthropic Claude 3 model. If you used a different model, update the parameter values according to the model you used.
The output files contain not only the processed text, but also observability data and the parameters used for inference. The following is an example in Python:
In this example using the Anthropic Claude 3 model, after we read the output file from Amazon S3, we process each line of the JSON data. We can access the processed text using data['modelOutput']['content'][0]['text'], the observability data such as input/output tokens, model, and stop reason, and the inference parameters like max tokens, temperature, top-p, and top-k.
In the output location specified for your batch inference job, you’ll find a manifest.json.out file that provides a summary of the processed records. This file includes information such as the total number of records processed, the number of successfully processed records, the number of records with errors, and the total input and output token counts.
You can then process this data as needed, such as integrating it into your existing workflows, or performing further analysis.
Remember to replace your-bucket-name, your-output-prefix, and your-output-file.jsonl.out with your actual values.
By using the AWS SDK, you can programmatically access and work with the processed data, observability information, inference parameters, and the summary information from your batch inference jobs, enabling seamless integration with your existing workflows and data pipelines.
Conclusion
Batch inference for Amazon Bedrock provides a solution for processing multiple data inputs in a single API call, as illustrated through our call center transcript summarization example. This fully managed service is designed to handle datasets of varying sizes, offering benefits for various industries and use cases.
We encourage you to implement batch inference in your projects and experience how it can optimize your interactions with FMs at scale.
About the Authors
 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
 Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
 Rahul Virbhadra Mishra is a Senior Software Engineer at Amazon Bedrock. He is passionate about delighting customers through building practical solutions for AWS and Amazon. Outside of work, he enjoys sports and values quality time with his family.
Rahul Virbhadra Mishra is a Senior Software Engineer at Amazon Bedrock. He is passionate about delighting customers through building practical solutions for AWS and Amazon. Outside of work, he enjoys sports and values quality time with his family.
 Mohd Altaf is an SDE at AWS AI Services based out of Seattle, United States. He works with AWS AI/ML tech space and has helped building various solutions across different teams at Amazon. In his spare time, he likes playing chess, snooker and indoor games.
Mohd Altaf is an SDE at AWS AI Services based out of Seattle, United States. He works with AWS AI/ML tech space and has helped building various solutions across different teams at Amazon. In his spare time, he likes playing chess, snooker and indoor games.